N-list算法:高效挖掘频繁项集的新方法
119 浏览量
更新于2024-07-14
收藏 1.27MB PDF 举报
"一种使用N-list快速挖掘频繁项集的新算法"
在数据挖掘领域,频繁项集挖掘是一项基础且关键的任务,它对于发现数据中的模式和关联规则至关重要。本文介绍了一种新的数据表示方法——N-list,它是从FP-tree启发的PPC-tree演变而来的,专门用于存储频繁项集的关键信息。N-list数据结构的优势在于其紧凑性,它允许有共同前缀的事务共享PPC树的节点,从而节省存储空间。
基于N-list,作者们设计并实现了一个名为PrePost的高效挖掘算法。PrePost算法的主要特点是:
1. 紧凑性:N-list通过共享节点减少了存储需求,尤其是对于具有公共前缀的事务,这显著降低了数据结构的大小。
2. 高效的交集计算:在计算项目集支持度时,PrePost算法将计数转换为N-list的交集。通过有效的策略,可以将两个N-list的交集操作的时间复杂度降低到O(m+n),其中m和n分别是两个N-list的基础项数,提高了运算速度。
3. 单路径属性:在某些情况下,PrePost可以直接在N-list的单条路径上找到频繁项集,避免了生成候选项集的过程,进一步提升了效率。
为了验证PrePost算法的有效性,研究者将其与四个最先进的频繁项集挖掘算法进行了比较,这些实验在各种真实和合成数据集上进行。实验结果显示,PrePost在大多数情况下运行速度最快,即使在数据集稀疏时,虽然内存消耗可能增加,但其速度优势仍然明显。
这篇研究论文发表在《中国科学:信息科学》2012年9月刊上,展示了N-list和PrePost算法在频繁项集挖掘领域的创新性和实用性。通过这种方式,数据挖掘的效率得到了显著提高,为后续的数据分析和决策支持提供了更快更有效的工具。这一方法不仅对数据挖掘领域,而且对依赖关联规则分析的诸多应用领域,如市场篮子分析、推荐系统等,都具有重要的理论和实际意义。
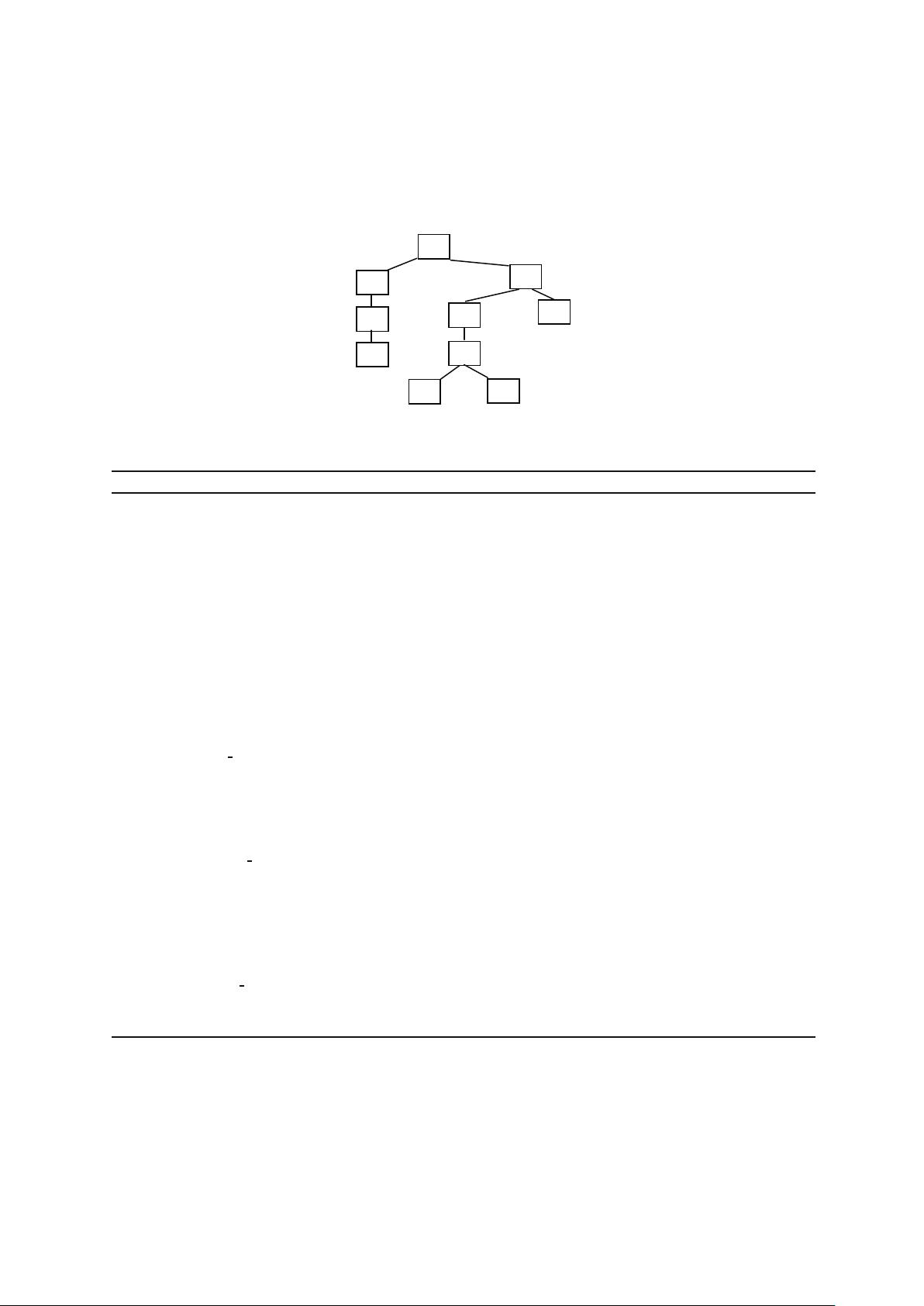
2012 Deng Z H, et al. Sci China Inf Sci September 2012 Vol. 55 No. 9
{}
(0,9)
c:1
(1,2)
(4,8)
b:4
f:1
a:1
(2,1)
(3,0)
c:3
(6,5)
(5,6)
(7,3)
(8,4)
(9,7)
f:1
a:1
e:3
f:1
Figure 1 The PPC-tree resulting from Example 1 after running Algorithm 1.
Algorithm 1 (PPC-tree construction)
Input: A transaction database DB and a minimum support ξ.
Output: A PPC-tree and F1 (the set of frequent 1-itemsets).
Method: Construct-PPC-tree(DB,ξ)
1: [Frequent 1-itemsets generation]
2: According to ξ , scan DB once to find F
1
, the set of frequent 1-itemsets (frequent items), and their supports.
3: Sort F1 in support descending order as L1, which is the list of ordered frequent items. Note that, if the supports
of some frequent items are equal, the orders can be assigned arbitrarily.
4: [PPC-tree construction]
5: Create the root of a PPC-tree, Tr , and label it as “null”.
6: for each transaction Trans in DB do
7: Select the frequent items in Trans and sort out them according to the order of F
1
. Let the sorted frequent-item
list in Trans be [p|P ], where p is the first element and P is the remaining list.
8: Call insert
tree([p|P ],Tr).
9: end for
10: [Pre-Post code generation]
11: Scan PPC-tree to generate the pre-order and the post-order of each node.
12:
13: [Function insert
tree([p|P ],Tr)]
14: if T
r
has a child N such that N.item-name = p.item-name then
15: increase N’s count by 1;
16: else
17: create a new node N, with its count initialized to 1, and add it to T
r
s children-list;
18: if Pisnonemptythen
19: call insert
tree(P, N) recursively.
20: end if
21: end if
Definition 2 (PP-code). For each node N in a PPC-tree, we call (N.pre−order, N.post-order):count
the PP-code of N.
In fact, the goal of constructing PPC-tree is to generate the PP-codes of frequent items, since the
PP-codes can reflect the structure of the PPC-tree as follows.
Property 1. Given any two different nodes N
1
and N
2
, N
1
is an ancestor of N
2
, if and only if
N
1
.pre-order < N
2
.pre-order and N
1
.post-order > N
2
.post-order.
For the proof of Property 1, please refer to [16]. Property 1 also shows that nodes and their PP-code
are 1-1 mapping. That is, a node uniquely determines a PP-code and a PP-code also uniquely determines
a node. Therefore, we have the following definition.
剩余22页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-11-01 上传
2021-03-28 上传
点击了解资源详情
2021-04-30 上传
2019-10-20 上传
2015-01-14 上传

weixin_38607971
- 粉丝: 3
- 资源: 972
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
