使用正则表达式爬取读书信息的实验步骤
版权申诉
26 浏览量
更新于2024-06-27
收藏 2.72MB PPTX 举报
爬虫技术之使用正则表达式提取某站点读书信息
**爬虫技术概述**
爬虫技术是指通过程序或软件自动或半自动地从互联网上提取和收集数据的技术。它广泛应用于数据挖掘、信息检索、商业智能等领域。爬虫技术可以分为两大类:网络爬虫和数据爬虫。网络爬虫主要用于爬取网络上的网页数据,而数据爬虫则用于爬取特定网站或数据库中的数据。
**使用正则表达式提取某站点读书信息**
在本实验中,我们使用了爬虫技术来提取某站点的读书信息。该站点是一个图书行业门户网站,提供了大量的书籍信息。为了获取这些信息,我们使用了正则表达式来解析网页的HTML代码,并提取出书籍的名称、作者、简介等信息。
**实验思路**
实验思路主要分为四步:
1. 数据定位:使用浏览器的开发者工具来定位要爬取的数据标签结构。
2. 正则表达式编写:根据数据元素标签结构编写正则表达式来匹配要爬取的数据。
3. 数据爬取:使用requests库进行网络连接,并模拟浏览器向网站发送请求,获取网站的HTML代码,然后使用re正则表达式模块来解析HTML代码,并提取出书籍信息。
4. 数据存储:将提取出的书籍信息存储到数据库或文件中。
**实验步骤**
实验步骤主要分为五步:
1. 打开浏览器,输入读书网页地址,并使用F12打开开发者工具。
2. 在开发者工具中,找到请求地址的header值,并定位到要爬取书籍信息的标签目录结构。
3. 根据前两步的结果,编写正则表达式来匹配要爬取的数据。
4. 创建book项目,并创建book.py文件,根据正则表达式完成数据爬取。
5. 将提取出的书籍信息存储到数据库或文件中。
**使用正则表达式的优点**
使用正则表达式可以轻松地提取出网页中的数据,且可以根据需要灵活地修改正则表达式来匹配不同的数据结构。此外,正则表达式还可以用于数据清洗和数据处理等方面。
**爬虫技术的应用**
爬虫技术广泛应用于各个领域,例如:
* 数据挖掘:爬虫技术可以用于爬取大量的数据,以供后续的数据分析和处理。
* 信息检索:爬虫技术可以用于爬取特定的信息,以供后续的信息检索和处理。
* 商业智能:爬虫技术可以用于爬取商业数据,以供后续的商业智能分析和处理。
爬虫技术是指通过程序或软件自动或半自动地从互联网上提取和收集数据的技术。使用正则表达式可以轻松地提取出网页中的数据,并可以灵活地修改正则表达式来匹配不同的数据结构。
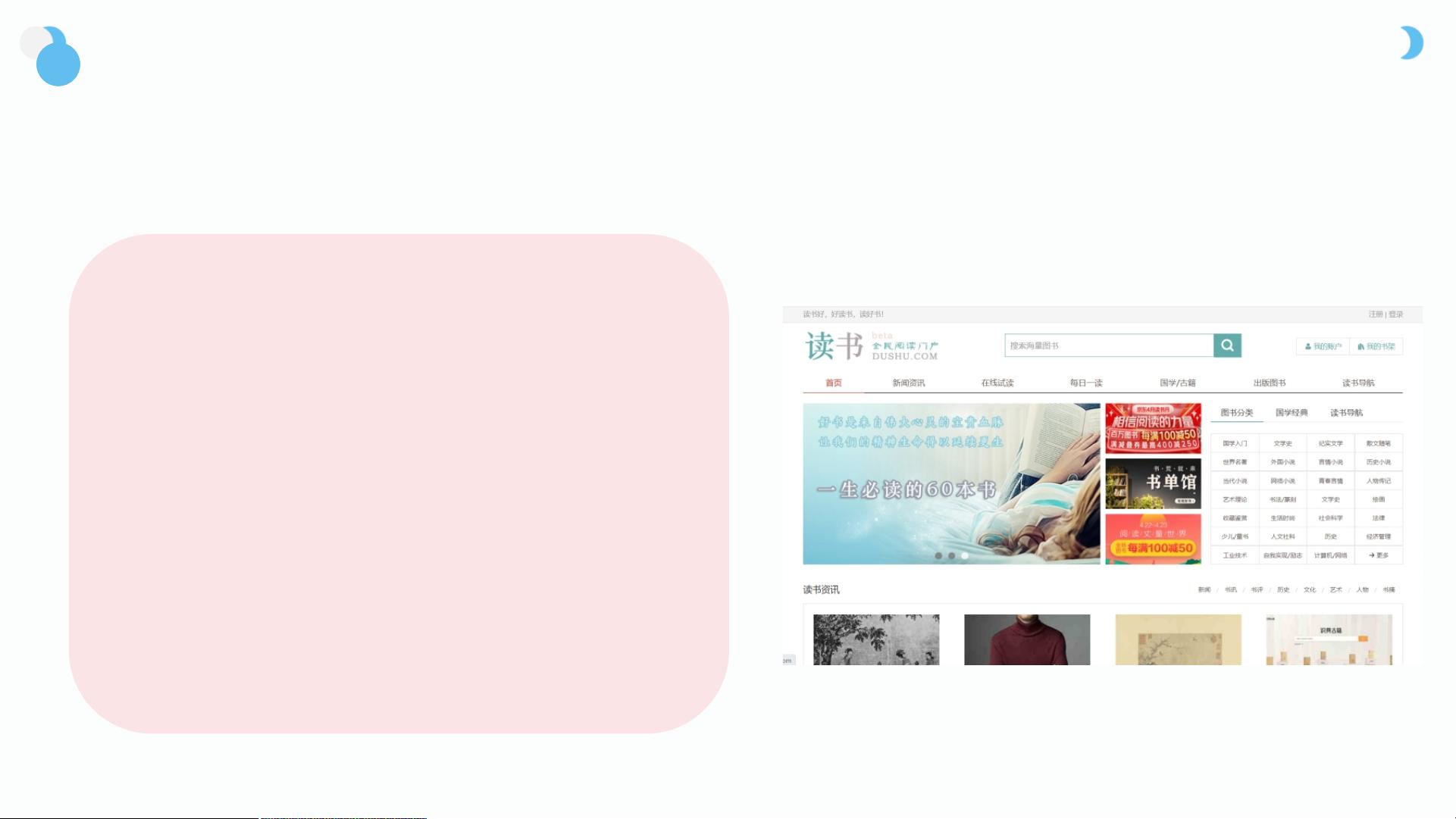
实验背景
使用正则表达式提取某站点读书信息
读书网是集图书搜索、在线阅读、比较购物,
图书行业资讯平台以及读者交流平台为一身的图
书行业门户网站。我们可以轻松了各种书籍信息
,为了了解不同小说的排名及热度,我们需要将
网站中的小说书籍信息通过网络爬虫技术爬取下
来。
本实验使用re正则表达式模块获取读书资讯页
面的读书信息,读书信息主要有:书籍名称、作
者、简介,每页有40本书籍信息,我们需要将所
有读书信息全部爬取下来。
剩余16页未读,继续阅读
2021-10-08 上传
2021-10-03 上传
2021-10-08 上传
2022-06-13 上传
2021-03-12 上传
2020-12-09 上传
2021-07-06 上传

知识世界
- 粉丝: 373
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
