文本歧义与清理:分词、停用词移除与词干还原
55 浏览量
更新于2024-08-31
收藏 106KB PDF 举报
在第2章“文本的歧义及其清理”中,章节详细探讨了文本处理中的关键步骤,以确保准确理解和分析文本内容。主要内容包括:
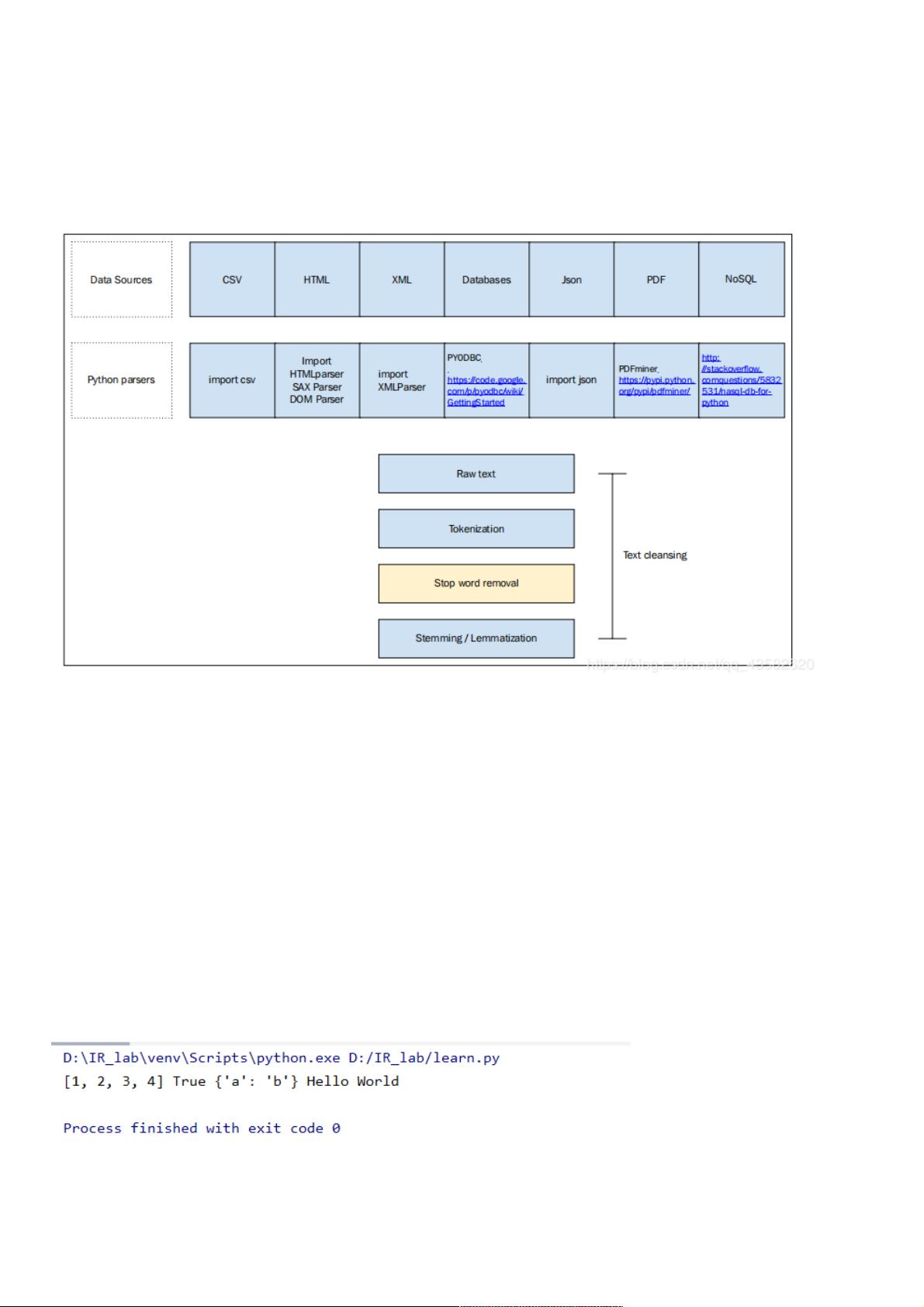
1. **文本预处理**:首先,对输入的文本进行词项化,即将连续的文本转换为一个个可处理的单元,例如单词或短语。这通常是通过分词技术实现,将句子拆分成单个词语,比如在Python中可以使用NLTK库的`word_tokenize()`函数。
2. **去除停用词**:停用词是指在文本分析中通常不会影响语义理解的常见词汇,如“的”、“是”、“在”等。它们被去除是因为在大多数情况下对文本的中心思想贡献较小。Python中可以通过自然语言处理库(如NLTK)提供停用词列表,并使用`nltk.corpus.stopwords`进行过滤。
3. **词干提取与词形还原**:词干提取(Stemming)和词形还原(Lemmatization)是减少词汇变形形式的重要步骤。词干提取通常采用算法如Porter Stemmer或Snowball Stemmer,将单词归一化为其基本形式。词形还原则是找到一个词的基本词根,如在英文中,“running”还原为“run”。NLTK库提供了这些功能的实现。
4. **JSON文件操作**:章节中提到的一个示例展示了如何使用Python处理JSON文件,通过`json.load()`函数加载数据,然后访问键值对。这对于非文本数据的处理同样重要,尤其是在处理结构化数据时。
5. **语句分离**:对长篇文本进行句子分割,有助于更好地理解文本的逻辑结构。`nltk.tokenize.sent_tokenize()`函数用于基于语句边界进行分割,如例子中的HTML文本和普通文本处理。
6. **标识化处理**:针对字符串类型的数据,`split()`方法是基础的分隔操作,可以利用空白符将字符串分割成单词。更高级的方法如`word_tokenize()`和`regex_tokenize()`提供了更复杂的分割规则,可以根据需求定制。
第2章的内容涵盖了文本处理中的核心步骤,通过这些技术,能够有效地清理、标准化和解析文本,为后续的分析和理解打下坚实基础。
第第2章章 文本的歧义及其清理(包括,分词,去除停用词,词干文本的歧义及其清理(包括,分词,去除停用词,词干
提取,词形还原等)提取,词形还原等)
第第2章章 文本的歧义及其清理文本的歧义及其清理
文本处理的过程:文本处理的过程:
词项化—>去除停用词—->词干提取或词形还原
1. 简单看看简单看看json文件的基本内容:文件的基本内容:
example.json:
{
“array”: [1,2,3,4],
“boolean”: “True”,
“object”: {
“a”: “b”
},
“string”: “Hello World”
}
简单的处理代码:
import json
#打开文件
jsonfile=open("example.json")
#加载数据
data=json.load(jsonfile)
print(data['array'],data['boolean'],data['object'],data['string'])
结果如下:
2.语句分离语句分离
前边应该进行文本清理,如前面对html语言进行处理不必要字符,以及删去长度短的字母。
语句分离即将大段原生文本分割成一系列语句。
利用利用
sent_tokenize
分离语句分离语句
:
下载后可阅读完整内容,剩余3页未读,立即下载
2018-05-15 上传
2018-04-15 上传
2024-12-02 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-06-09 上传
2024-12-22 上传
2024-12-22 上传

weixin_38723753
- 粉丝: 2
- 资源: 906
 我的内容管理
展开
我的内容管理
展开







