NVIDIA CUDA并行编程训练:清华大学课程
需积分: 9 165 浏览量
更新于2024-07-28
收藏 1.44MB PDF 举报
"CUDA超大规模并行程序设计训练课程"
CUDA,全称为Compute Unified Device Architecture,是由NVIDIA公司推出的一种并行计算平台和编程模型,主要应用于高性能计算、图形渲染和人工智能等领域。该课程由清华大学微电子学研究所的邓仰东教授主讲,旨在教授如何有效地利用NVIDIA GPU的并行计算能力进行程序设计。
课程内容分为四大部分:
1. **CUDA概论**:这部分会介绍CUDA的基本概念,包括GPU的架构、CUDA编程环境的设置以及CUDA编程的核心元素——kernel函数。
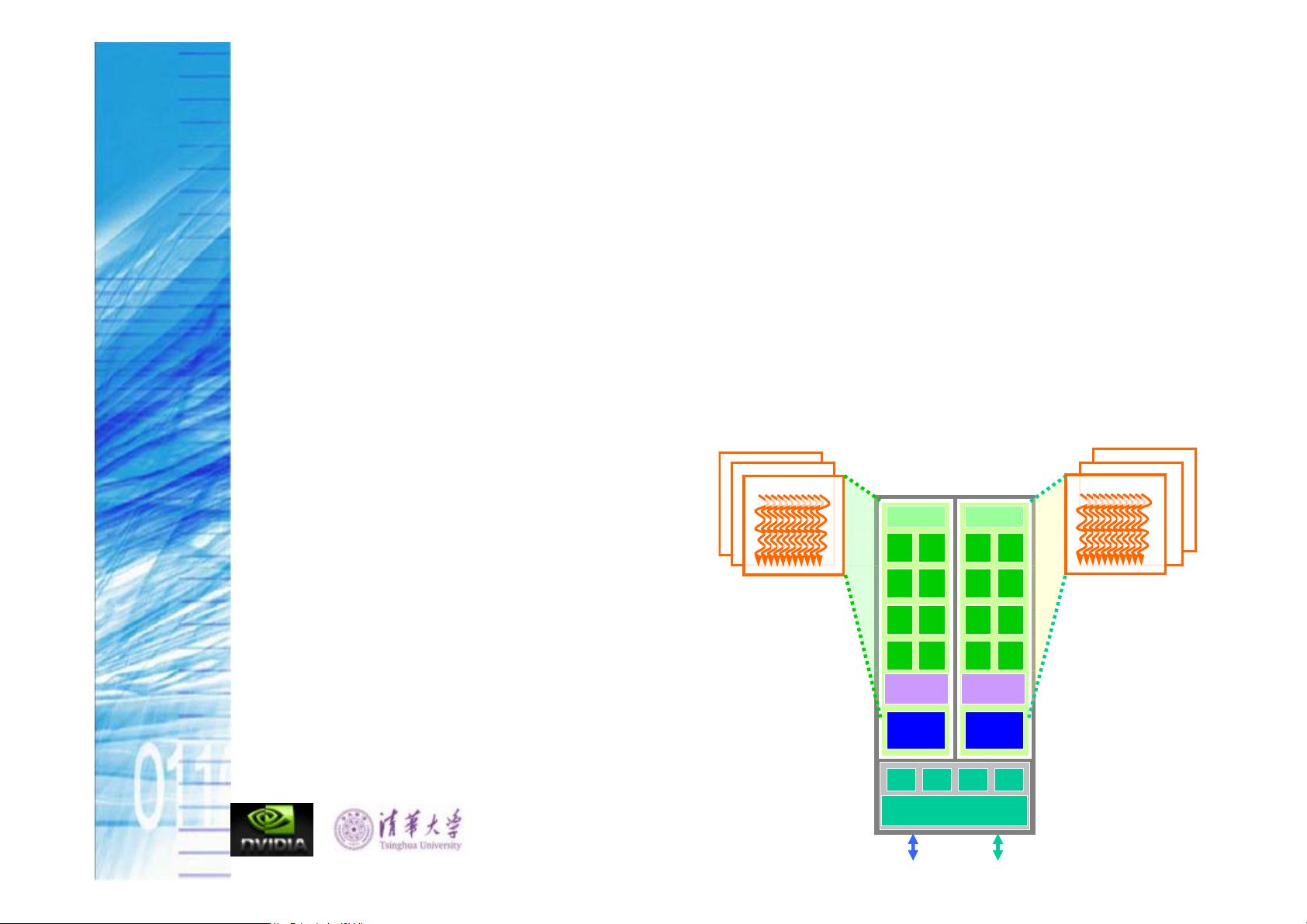
2. **编程模型**:讲解CUDA的编程模型,包括线程和线程块的概念。在CUDA中,线程是执行计算的基本单元,而线程块则是一组协同工作的线程,它们共享内存空间。线程和线程块可以进一步组织成grid,形成多级并行结构。
3. **多线程和存储器硬件**:深入探讨CUDA中的存储器层次,如寄存器、共享内存、全局内存等。其中,SM(Streaming Multiprocessor)存储资源的管理和bank conflict的避免是优化性能的关键。全局内存访问模式,如coalesced和non-coalesced access,也会影响程序效率。
4. **性能提升**:这部分将讨论如何通过优化数据访问、减少bank conflict、有效利用共享内存以及理解和应用内存对齐等方式来提高CUDA程序的运行速度。
课程中提到的并行与并发的区分也是重要的理论基础。在广义上,两者可以互换,但在狭义的并行计算中,指的是多个独立的线程同时执行任务,而并发则可能涉及线程的交替执行或暂停状态(如在单一处理器系统中的多任务处理)。
CUDA程序设计的一个特点是SPMD(Single Program, Multiple Data),即同一程序在多个数据流上并行执行。在CUDA中,CPU负责顺序执行代码,而GPU则执行以线程块组织的并行代码。每个线程块内的线程可以合作完成任务,通过共享内存和同步机制实现高效的数据交换和计算。
课程中还会详细讲解grid和thread blocks的组织方式,以及它们在设备上的执行模型。理解这些概念对于编写高效且可扩展的CUDA程序至关重要。每个kernel执行时,会形成一个grid,由多个thread blocks组成,每个block又包含多个线程。这种多层次的并行结构使得程序员能够充分利用GPU的并行计算能力。
"CUDA-lecture-3"是针对NVIDIA CUDA技术的深度学习课程,涵盖了CUDA编程的基础和高级主题,对于想要掌握GPU并行计算的开发者来说是非常宝贵的资源。


125 浏览量
点击了解资源详情
点击了解资源详情
142 浏览量
192 浏览量
188 浏览量
2021-08-09 上传
2021-06-10 上传

golddreamok
- 粉丝: 0
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国计算机技术与软件专业技术资格考试:软件评测师考试大纲
- ajax实战中文版.pdf
- 从头开始对Ubuntu优化
- spring开发指南(夏昕)
- ORACLE9i_优化设计与系统调整
- JTAG调试原理(ARM芯片)
- 第1章 Visual Basic的特点和版本
- KingbaseES入门-Windows
- Oracle DBA应该定期做什么笔记
- 网络工程师PPT 只有第一章 谢谢大家的分享
- 2008年全国计算机等级考试二级公共基础精选120题
- 统计软件SAS教程(李东风)
- 从硬盘安装Linux
- 2007年9月全国计算机等级考试二级C语言笔试试题(含参考答案).doc
- 统一建模语言(UML)参考手册——基本概念
- 2007年4月全国计算机等级考试二级C语言笔试试题(含参考答案)
