非参数密度估计:Parzen窗与k-NN方法
需积分: 50 21 浏览量
更新于2024-07-23
收藏 1.29MB PPT 举报
"非参数估计方法,特别是Parzen窗估计和k-NN估计在概率密度估计及分类中的应用"
非参数估计是一种统计方法,用于估计未知的概率分布,它不依赖于预先设定的概率密度函数形式。这种方法在实际问题中非常有用,因为很多情况下,我们无法准确地知道数据遵循的具体概率模型。非参数估计可以处理多模态分布、高维数据以及那些不能简单分解为低维函数乘积的情况。
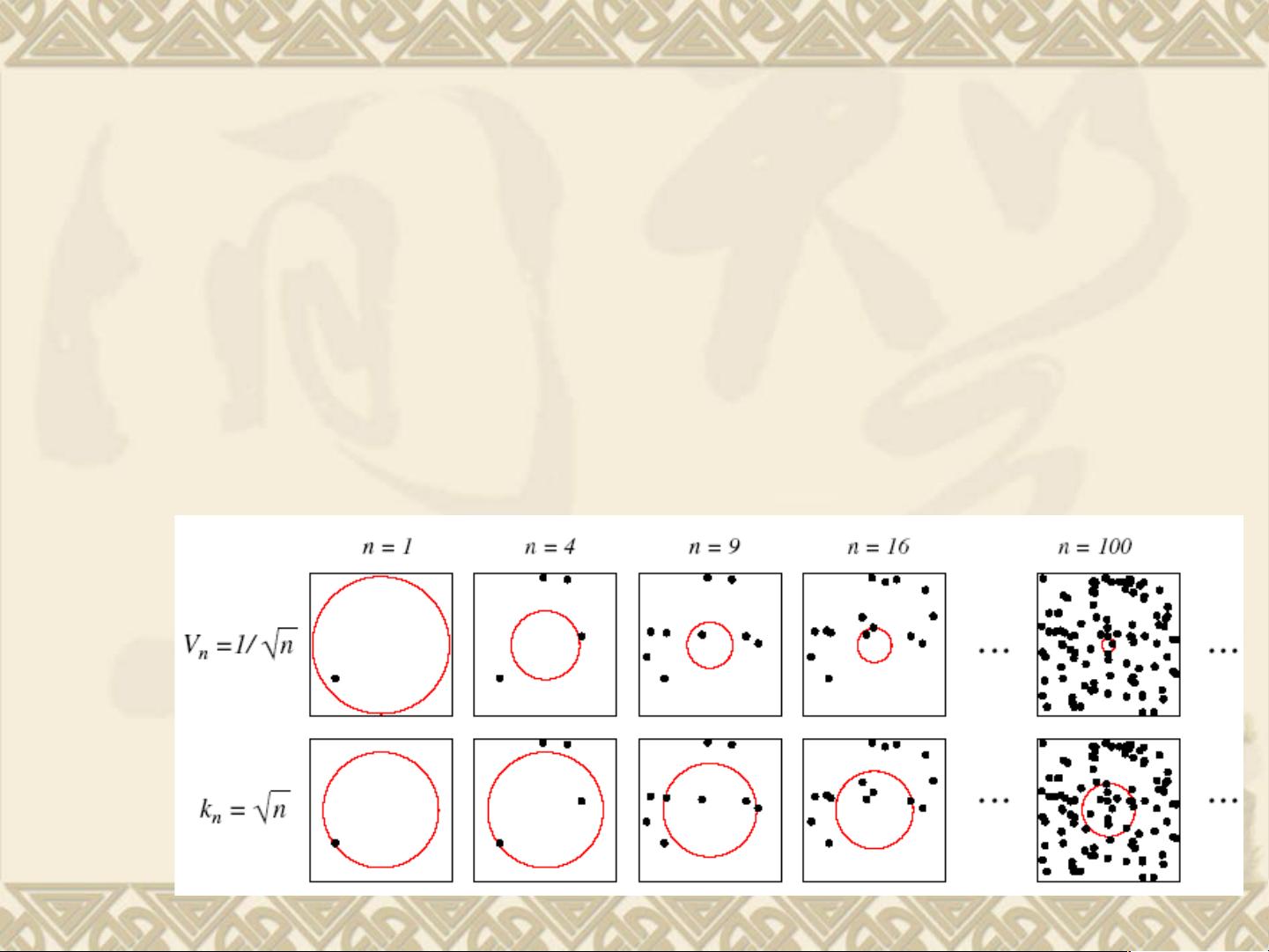
概率密度估计是寻找数据分布形状的过程,对于独立同分布(i.i.d.)的样本集,目标是找到一个能够描述这些样本的分布的函数。直方图是最简单的非参数密度估计方法,通过将数据空间划分为小的区间(或“小窗”),然后计算每个区间内样本的数量,并除以总样本数和区间体积来估计区间内的密度。
Parzen窗估计,也称为窗口密度估计,是通过在每个样本点周围放置一个有特定宽度的窗口(通常选择高斯窗口或Epanechnikov窗口),然后用窗口函数的积分来估计密度。窗口函数的选择会影响估计的平滑程度。对于足够大的样本量和适当的窗口大小,Parzen窗估计可以提供对概率密度函数的精确估计。
k-NN(最近邻)估计是另一种非参数方法,它基于一个简单的思想:一个点的密度可以由其最近的k个邻居的密度来估计。k-NN不仅用于密度估计,也被广泛应用于分类任务,即k-NN分类器。在这个分类器中,新样本的类别是其最近的k个邻居中最常见的类别。k值的选择对结果有显著影响,较小的k值可能导致过拟合,较大的k值则可能导致欠拟合。
最近邻分类器(NN)是k-NN的一个特殊情况,当k=1时,分类决策基于与新样本最近的一个训练样本的类别。NN分类器简单直观,但可能对噪声和异常值敏感。
非参数估计方法的主要优点在于其灵活性,能够适应各种复杂的数据分布,而无需进行严格的模型假设。然而,它们也有局限性,例如样本需求量大,计算成本高,以及对异常值和边界效应敏感。在实际应用中,需要根据具体问题选择合适的非参数方法,并通过调整参数(如窗口大小、k值等)来优化性能。

概率密度估计
收敛性问题:样本数量 N 无穷大是,估计的概率函
数是否收敛到真实值?
ˆ
lim
N
N
p p
x x
0R
实际中,
ˆ
p x
越精确,要求:
实际中, N 是有限的:
0R
ˆ
0p x
当 时,绝大部分区间没有样本:
ˆ
p x
如果侥幸存在一个样本,则:

剩余63页未读,继续阅读
2021-05-20 上传
2018-12-01 上传
2019-08-14 上传
2021-02-02 上传
2021-05-16 上传
2021-03-13 上传
2021-06-21 上传
2021-07-02 上传

wanglei_t
- 粉丝: 0
- 资源: 16
 我的内容管理
展开
我的内容管理
展开







最新资源
- cadastro-de-funcionarios:使用Python语言制作了小玩意儿,Qt Designer用于开发接口,MongoDB用于数据存储
- contactkeeper
- torch_sparse-0.6.12-cp36-cp36m-linux_x86_64whl.zip
- 保险科技案例报告-栈略数据:一栈式保险风控服务提供商,专注健康险风控领域2021.rar
- akslides:我的幻灯片,Markdown内容以及使用reveal.js进行渲染
- status.todoparrot.com:TODOParrot.com 的状态 API
- 城市:简单的城市应用程序,用于练习创建PostgreSQL数据库和使用Postico处理数据
- next-responsive-navbar
- SDL:CSC221@城市学院
- onnxjs_test
- myportfolio:关于我的一瞥
- 打乱
- fedora-accounts-docs:Fedora帐户文档
- 美食网站模版
- ANNOgesic-1.0.19-py3-none-any.whl.zip
- 零基础入门NLP - 新闻文本分类-数据集
