"迁移学习综述:解决不同领域数据分布偏移问题的调查"
需积分: 9 143 浏览量
更新于2024-01-02
收藏 2.32MB PDF 举报
"迁移学习综述论文:A Survey on Transfer Learning"由Sinno Jialin Pan和Qiang Yang撰写,作为IEEE会员,他们在本文中对迁移学习进行了全面的调查和总结。在许多机器学习和数据挖掘算法中,一个主要的假设是训练和未来数据必须在相同的特征空间中,并且具有相同的分布。然而,在许多实际应用中,这个假设可能不成立。例如,在一个领域中我们可能有一个分类任务,但是我们只有另一个领域中充足的训练数据,而后者数据的分布和特征空间与前者不同。
迁移学习的概念是为了解决这个问题而提出的。它旨在利用在一个领域中学到的知识来改善在另一个相关领域中的学习性能。迁移学习已经在许多领域得到了广泛的应用,包括计算机视觉、自然语言处理、医学图像分析等。本文就是要对迁移学习的相关领域、应用、方法和技术进行综述和分析。
在文章中,作者首先介绍了迁移学习的基本概念和背景,包括定义、目标、形式化问题陈述等内容。接着,他们对迁移学习的分类进行了详细的介绍。根据来源领域和目标领域的关系,迁移学习可以分为各种不同的类型,如领域自适应、多任务学习、迁移分类等。
然后,文章对迁移学习的方法和技术进行了详细的探讨。作者提出了一些典型的迁移学习算法,如基于实例的方法、基于模型的方法、基于特征的方法等,并对每种方法的优缺点进行了分析。此外,他们还介绍了一些在迁移学习中常用的技术,如领域间距离度量、核方法、深度学习等。这些方法和技术为解决迁移学习中的问题提供了重要的参考和指导。
除此之外,作者还对迁移学习在不同领域中的应用进行了总结。他们介绍了迁移学习在计算机视觉、自然语言处理、医学图像分析等领域的具体应用案例,并分析了这些案例中迁移学习的有效性和局限性。这些案例为读者提供了对迁移学习实际应用的深入理解,同时也为未来的研究提供了有益的启示。
最后,作者对迁移学习的发展趋势进行了展望。他们认为,随着数据和计算能力的不断增长,迁移学习将在更多的领域得到应用,并且迁移学习算法和技术也将会不断地得到改进和完善。同时,迁移学习还将和其他相关领域相互融合,产生更多的创新和突破。这些展望为迁移学习的未来研究提供了重要的思路和方向。
综上所述,"迁移学习综述论文:A Survey on Transfer Learning"是一篇全面而系统的关于迁移学习的综述论文。通过对迁移学习的基本概念、分类、方法、技术、应用和发展趋势进行深入的探讨,本文为读者提供了对迁移学习的全面理解和深刻认识,同时也为未来的研究和应用提供了重要的参考和指导。
is document classification, and each term is taken as a binary
feature, then X is the space of all term vectors, x
i
is the ith term
vector corresponding to some documents, and X is a
particular learning sample. In general, if two domains are
different, then they may have different feature spaces or
different marginal probability distributions.
Given a specific domain, D¼fX;PðXÞg,atask consists
of two components: a label space Y and an objective
predictive function fðÞ (denoted by T¼fY;fðÞg), which is
not observed but can be learned from the training data,
which consist of pairs fx
i
;y
i
g, where x
i
2 X and y
i
2Y. The
function fðÞ can be used to predict the corresponding label,
fðxÞ, of a new instance x. From a probabilistic viewpoint,
fðxÞ can be written as PðyjxÞ. In our document classification
example, Y is the set of all labels, which is True, False for a
binary classification task, and y
i
is “True” or “False.”
For simplicity, in this survey, we only consider the case
where there is one source domain D
S
, and one target domain,
D
T
, as this is by far the most popular of the research works in
the literature. More specifically, we denote the source domain
data as D
S
¼fðx
S
1
;y
S
1
Þ; ...; ðx
S
n
S
;y
S
n
S
Þg, where x
S
i
2X
S
is
the data instance and y
S
i
2Y
S
is the corresponding class
label. In our document classification example, D
S
can be a set
of term vectors together with their associated true or false
class labels. Similarly, we denote the target-domain data as
D
T
¼fðx
T
1
;y
T
1
Þ; ...; ðx
T
n
T
;y
T
n
T
Þg, where the input x
T
i
is in
X
T
and y
T
i
2Y
T
is the corresponding output. In most cases,
0 n
T
n
S
.
We now give a unified definition of transfer learning.
Definition 1 (Transfer Learning). Given a source domain D
S
and learning task T
S
, a target domain D
T
and learning task
T
T
, transfer learning aims to help improve the learning of the
target predictive function f
T
ðÞ in D
T
using the knowledge in
D
S
and T
S
, where D
S
6¼D
T
,orT
S
6¼T
T
.
In the above definition, a domain is a pair D¼fX;PðXÞg.
Thus, the condition D
S
6¼D
T
implies that either X
S
6¼X
T
or
P
S
ðXÞ 6¼ P
T
ðXÞ. For example, in our document classification
example, this means that between a source document set and
a target document set, either the term features are different
between the two sets (e.g., they use different languages), or
their marginal distributions are different.
Similarly, a task is defined as a pair T¼fY;PðY jXÞg.
Thus, the condition T
S
6¼T
T
implies that either Y
S
6¼Y
T
or
P ðY
S
jX
S
Þ 6¼ P ðY
T
jX
T
Þ. When the target and source domains
are the same, i.e., D
S
¼D
T
, and their learning tasks are the
same, i.e., T
S
¼T
T
, the learning problem becomes a
traditional machine learning problem. When the domains
are different, then either 1) the feature spaces between the
domains are different, i.e., X
S
6¼X
T
, or 2) the feature spaces
between the domains are the same but the marginal
probability distributions between domain data are different;
i.e., P ðX
S
Þ 6¼ P ðX
T
Þ, where X
S
i
2X
S
and X
T
i
2X
T
.Asan
example, in our document classification example, case 1
corresponds to when the two sets of documents are
described in different languages, and case 2 may correspond
to when the source domain documents and the target-
domain documents focus on different topics.
Given specific domains D
S
and D
T
, when the learning
tasks T
S
and T
T
are different, then either 1) the label
spaces between the domains are different, i.e., Y
S
6¼Y
T
,or
2) the conditional probability distributions between the
domains are different; i.e., P ðY
S
jX
S
Þ 6¼ P ðY
T
jX
T
Þ, where
Y
S
i
2Y
S
and Y
T
i
2Y
T
. In our document classification
example, case 1 corresponds to the situation where source
domain has binary document classes, whereas the target
domain has 10 classes to classify the documents to. Case 2
corresponds to the situation where the source and target
documents are very unbalanced in terms of the user-
defined classes.
In addition, when there exists some relationship, explicit
or implicit, between the feature spaces of the two domains,
we say that the source and target domains are related.
2.3 A Categorization of
Transfer Learning Techniques
In transfer learning, we have the following three main
research issues: 1) what to transfer, 2) how to transfer, and
3) when to transfer.
“What to transfer” asks which part of knowledge can be
transferred across domains or tasks. Some knowledge is
specific for individual domains or tasks, and some knowl-
edge may be common between different domains such that
they may help improve performance for the target domain or
task. After discovering which knowledge can be transferred,
learning algorithms need to be developed to transfer the
knowledge, which corresponds to the “how to transfer” issue.
“When to transfer” asks in which situations, transferring
skills should be done. Likewise, we are interested in
knowing in which situations, knowledge should not be
transferred. In some situations, when the source domain
and target domain are not related to each other, brute-force
transfer may be unsuccessful. In the worst case, it may
even hurt the performance of learning in the target
domain, a situation which is often referred to as negative
transfer. Most current work on transfer learning focuses on
“What to transfer” and “How to transfer,” by implicitly
assuming that the source and target domains be related to
each other. However, how to avoid negative transfer is an
important open issue that is attracting more and more
attention in the future.
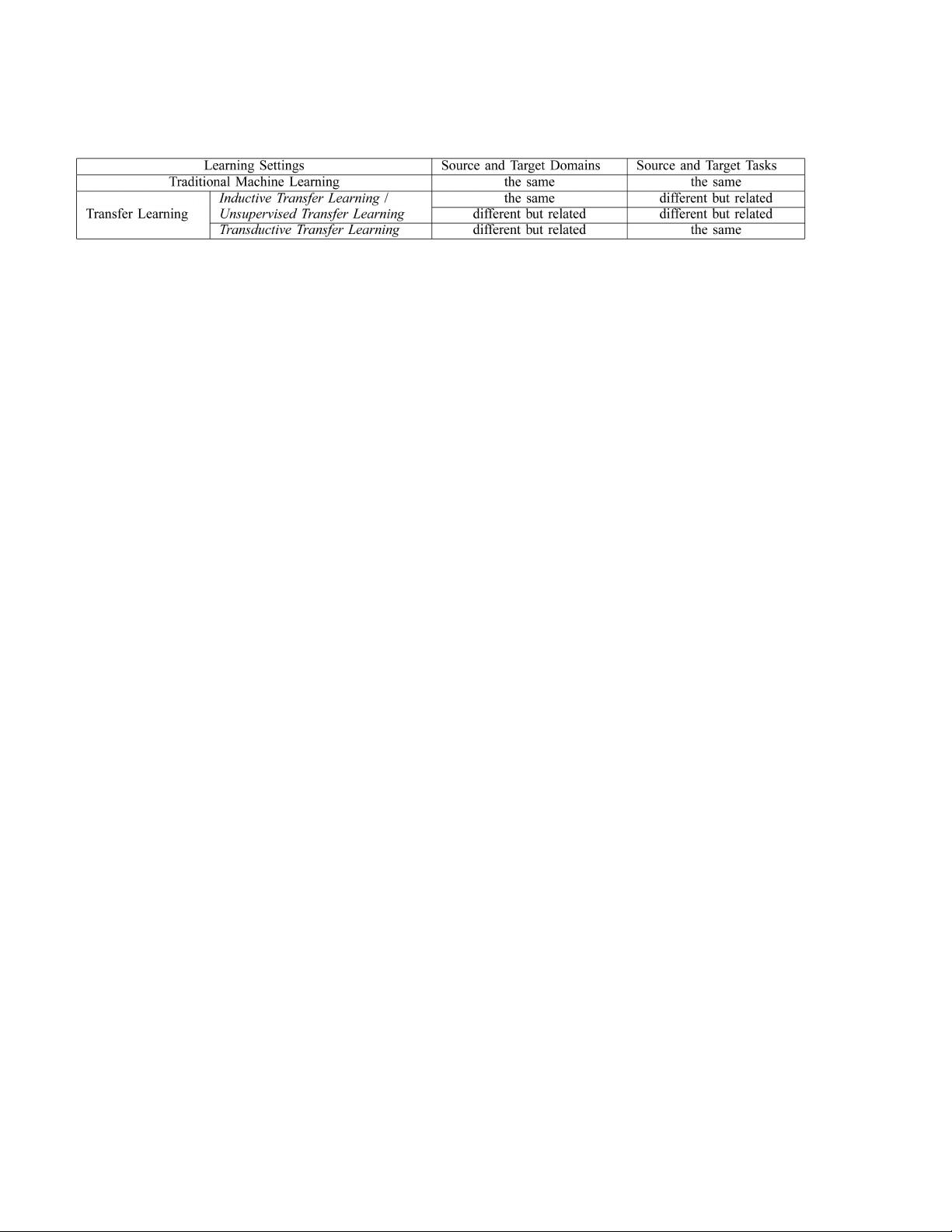
Based on the definition of transfer learning, we summarize
the relationship between traditional machine learning and
various transfer learning settings in Table 1, where we
PAN AND YANG: A SURVEY ON TRANSFER LEARNING 1347
TABLE 1
Relationship between Traditional Machine Learning and Various Transfer Learning Settings
剩余14页未读,继续阅读
2018-01-18 上传
2020-02-29 上传
2020-01-30 上传
2019-11-12 上传
2020-07-21 上传
2020-04-11 上传
2023-03-16 上传

puluowangsi2
- 粉丝: 0
- 资源: 19
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
