K-means与谱聚类:大数据分析中的关键聚类技术
需积分: 10 92 浏览量
更新于2024-07-18
收藏 4.24MB PDF 举报
在大数据分析中,聚类算法是一种重要的无监督学习技术,用于对数据进行分组,使得同一组内的数据具有较高的相似性,而不同组之间的差异较大。本资源主要关注三个核心聚类算法:
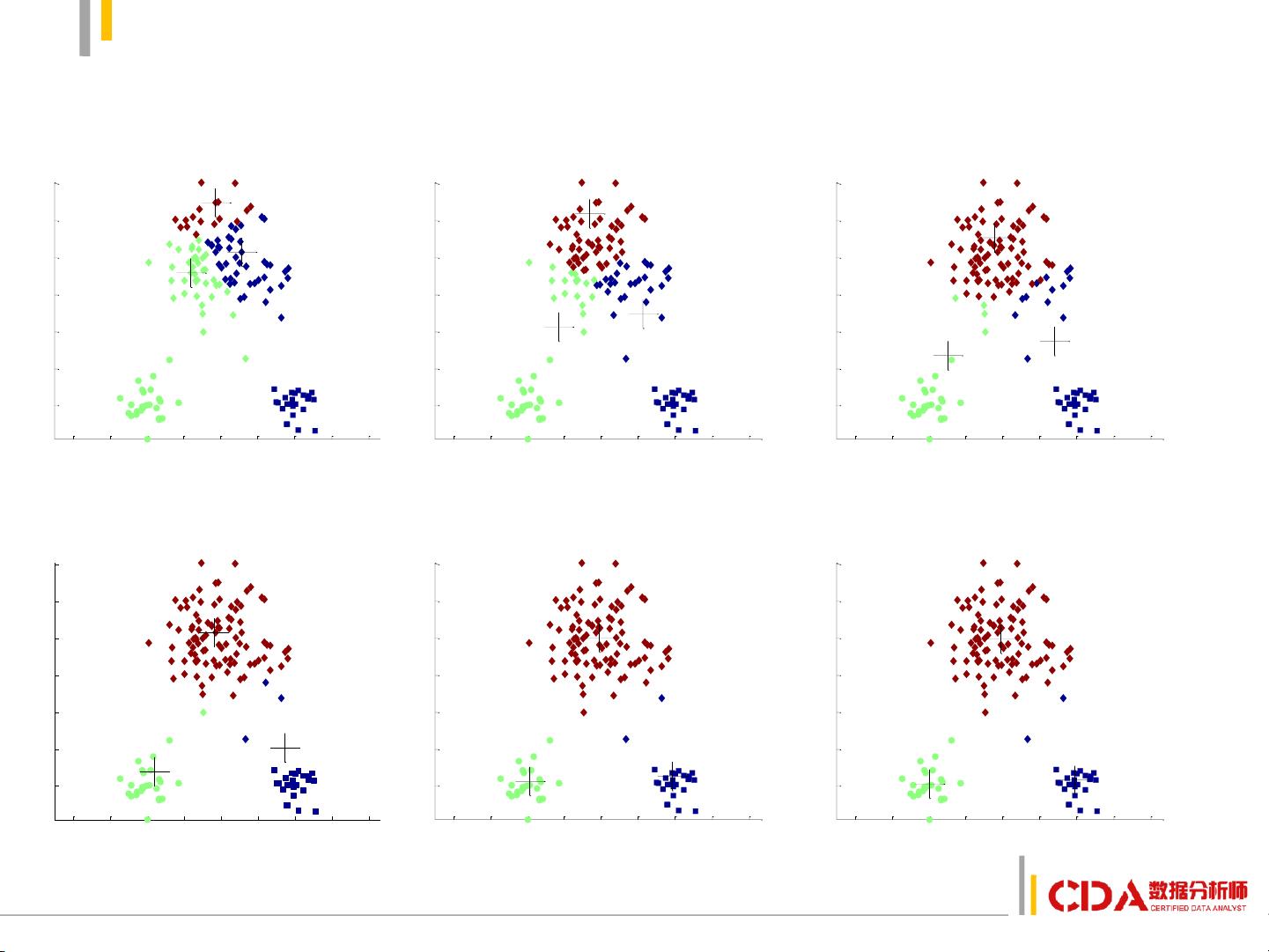
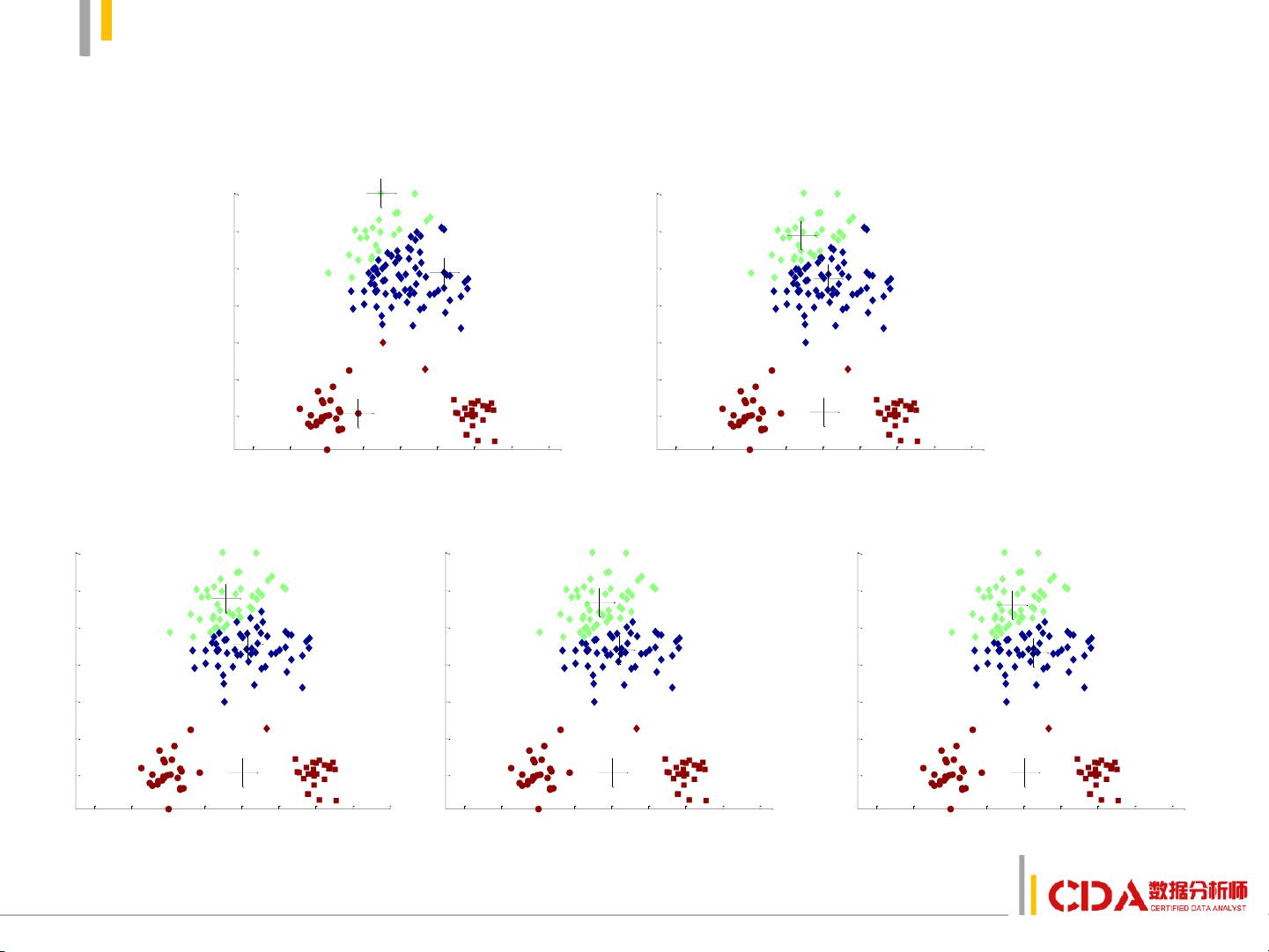
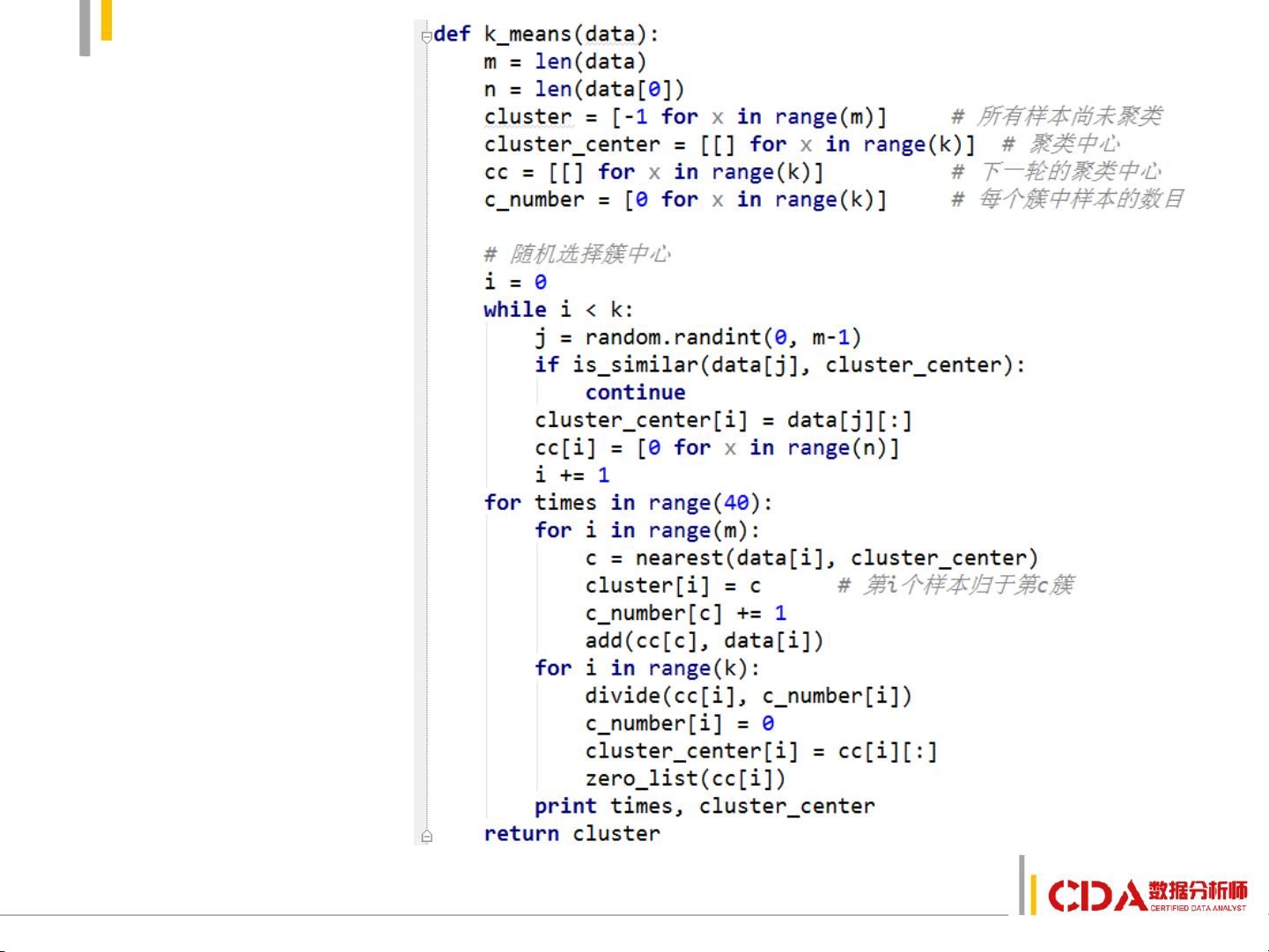
1. K-means聚类:K-means 是一种迭代的划分方法,它假设数据集可以被划分为预先设定数量(K)的类别。学习者需掌握如何选择合适的初始质心、确定聚类步骤以及评估聚类效果(如肘部法则)。K-means对数据的分布形状有一定假设,适用于数据点呈明显集群的情况。
2. 谱聚类:谱聚类是一种基于图论的聚类方法,通过构建数据点之间的相似度矩阵来识别潜在的结构。谱聚类与主成分分析(PCA)有密切关系,PCA可以视为一种低维嵌入,而谱聚类则利用图的拉普拉斯矩阵进行更复杂的聚类。理解谱聚类与PCA的联系有助于更好地应用谱聚类算法。
3. 密度聚类:包括 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)和密度最大值聚类等方法。DBSCAN是一种基于密度的聚类算法,它不预先设定聚类数量,而是自动发现高密度区域,对于噪声和异常值处理较为有效。密度最大值聚类则是寻找数据集中密度最大的子集作为聚类中心。
这些聚类算法各有特点,选择哪种方法取决于数据的特性,如数据分布、是否存在明显的聚类结构、噪声水平等。此外,还需要了解如何选择合适的相似度或距离度量方法,如闵可夫斯基距离、杰卡德相似系数、余弦相似度和Pearson相关系数,它们在不同的聚类算法中扮演关键角色。理解这些概念有助于在实际项目中高效地进行数据探索和分析。
Join Learn
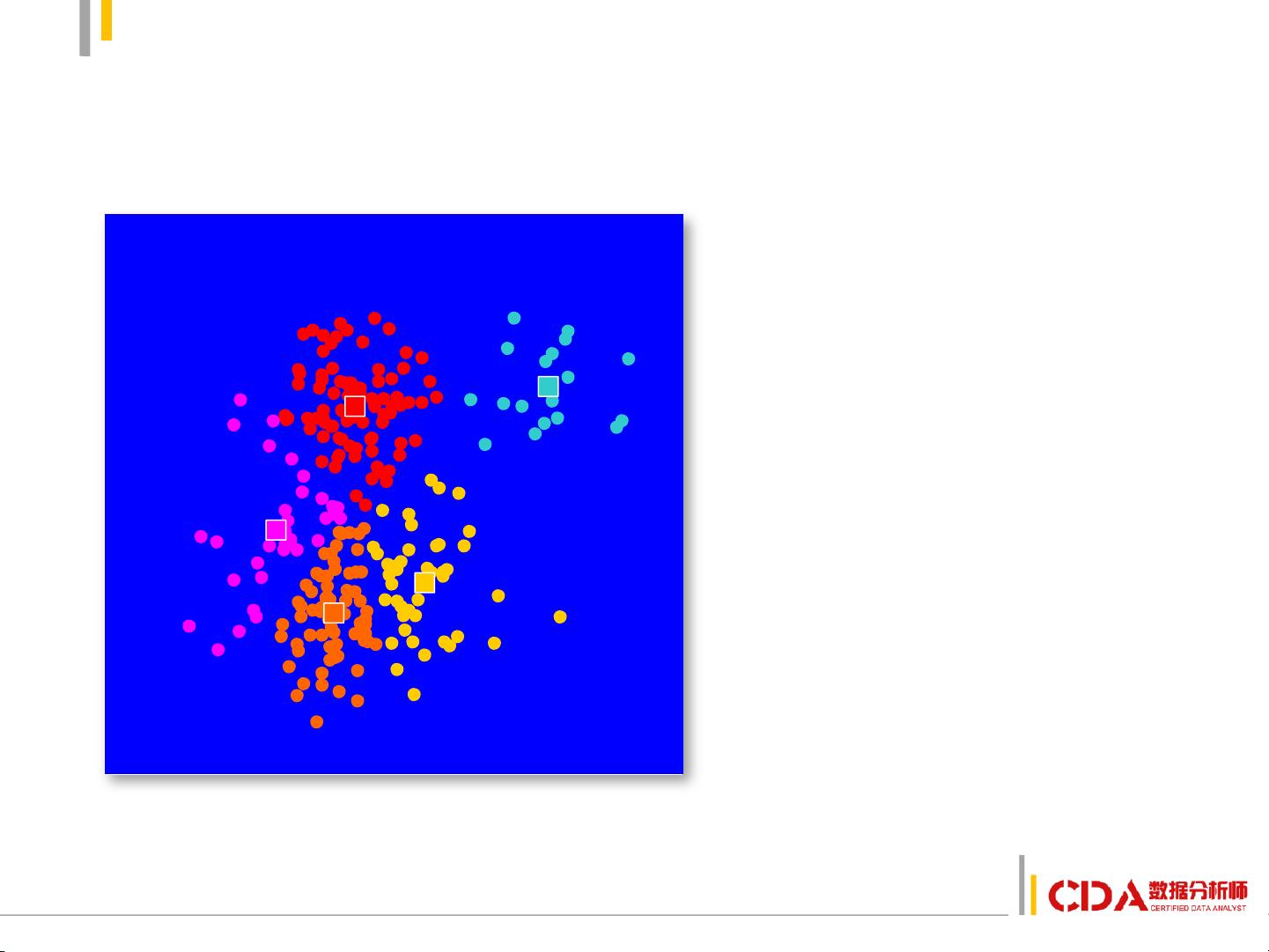
k-均值聚类法
15
训练数据
1. 选择数据.
2. 初始化中心点.
3. 将离数据近的点划分到相
应类.
4. 更新类的中心.
5. 重新将离数据近的点划分
到相应类.
6. 反复进行4、5步直至不再
有变化.
15
剩余88页未读,继续阅读
134 浏览量
1839 浏览量
351 浏览量
427 浏览量
2023-02-13 上传
202 浏览量
2022-07-15 上传
2024-12-23 上传

qilong0
- 粉丝: 2
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- 扬州大学新能源专业光伏试卷样卷4份.zip
- burrow_exporter:Prometheus导出器,用于从Burrow收集Kafka消费者组信息
- Maurice Wright - Note and Bookmarking App-crx插件
- 使用Python的关联规则:使用Python的关联规则
- xlostway.github.io:网站
- 嵌入式软件开发
- backupScripts:备份脚本
- protobuf-3.5.1 c++ inclue,lib,dll,代码
- 小型工作室展示组合响应式网页模板
- KinesisBLE:具有无线BLE的自定义Kinesis控制器
- PySpark-AI-service_Data-processing-NiFi:利用NiFi和AI服务通过云中托管的PySpark进行实时数据转换和持久性
- Python核心编程第2版习题答案.zip
- 简历模板(可任意修改) (472).zip
- 日程:Projeto utilizando AdonisJS
- git-basics:混帐基础
- 微信小程序Demo:够嗨
