使用八爪鱼采集微信文章正文:步骤详解
版权申诉
67 浏览量
更新于2024-06-27
收藏 5.11MB DOCX 举报
网页文章正文采集方法是IT领域的实用技能,特别是在信息抓取和自动化工具的帮助下,能有效地提高工作效率。以微信文章为例,本文将详细介绍如何使用八爪鱼这款通用的网页数据采集器来采集搜狗微信平台的文章正文内容。主要分为两种情况:一是只采集文本,不包含图片;二是同时采集文本和图片链接。
首先,我们需了解八爪鱼的功能特性。它支持自定义爬取,允许用户指定爬取的网站、数据类型、范围和时间,并提供数据存储选项。例如,XPath用于精确定位网页元素,判断条件帮助设置筛选规则,分页列表信息采集针对多页内容,而AJAX相关的教程则针对动态加载内容的处理。
具体到微信文章采集,以下是详细的步骤:
1. **创建采集任务** - 进入八爪鱼主界面,选择“自定义模式”,并将目标网址(如http://weixin.sogou.com/)输入并保存。
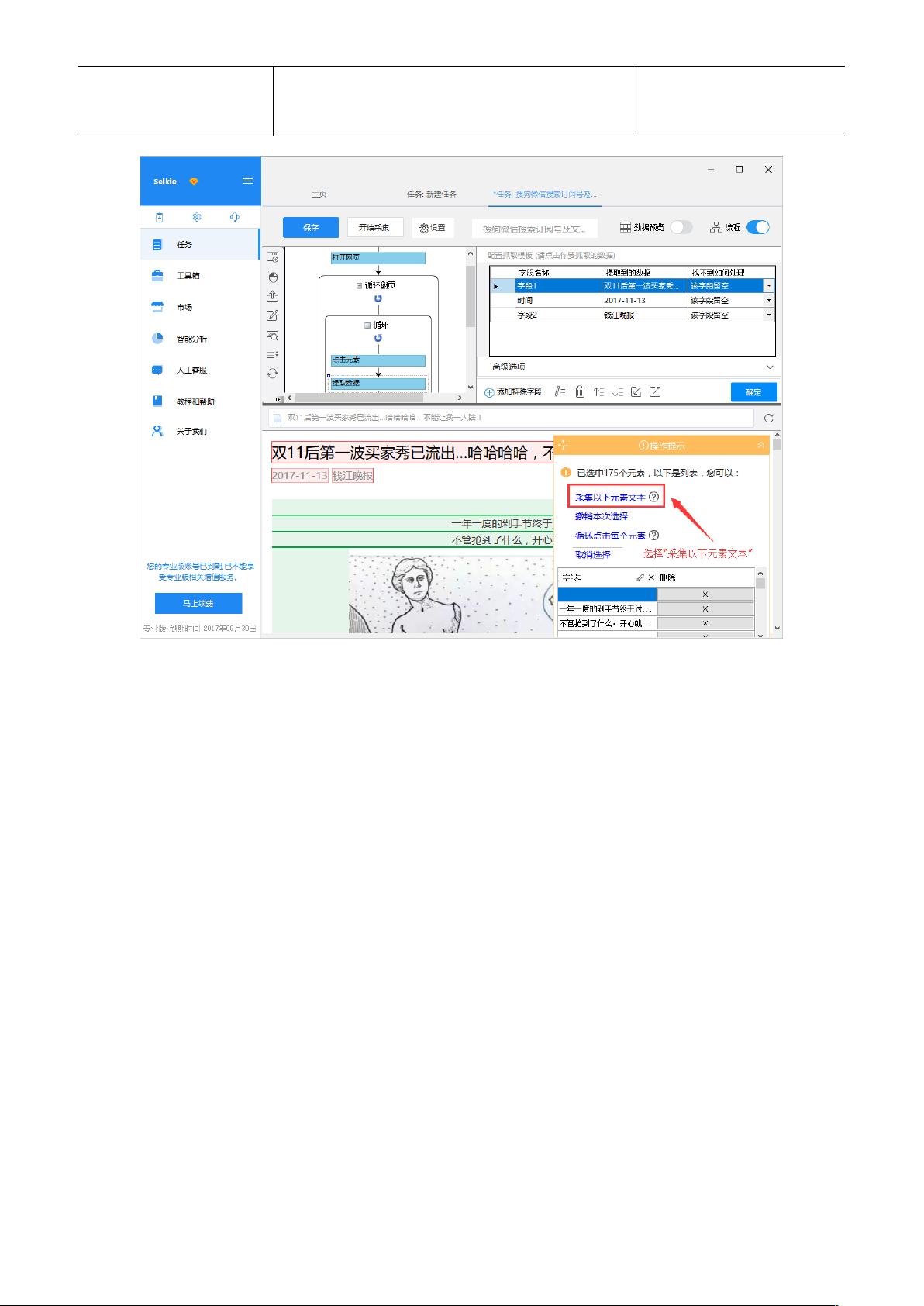
2. **设置翻页循环** - 在“流程设计器”中,首先查看默认的“热门”文章,然后找到并点击“加载更多内容”按钮,触发AJAX加载。在此过程中,选择“循环点击单个元素”来实现无限翻页,同时启用“Ajax加载数据”选项,设置等待时间。
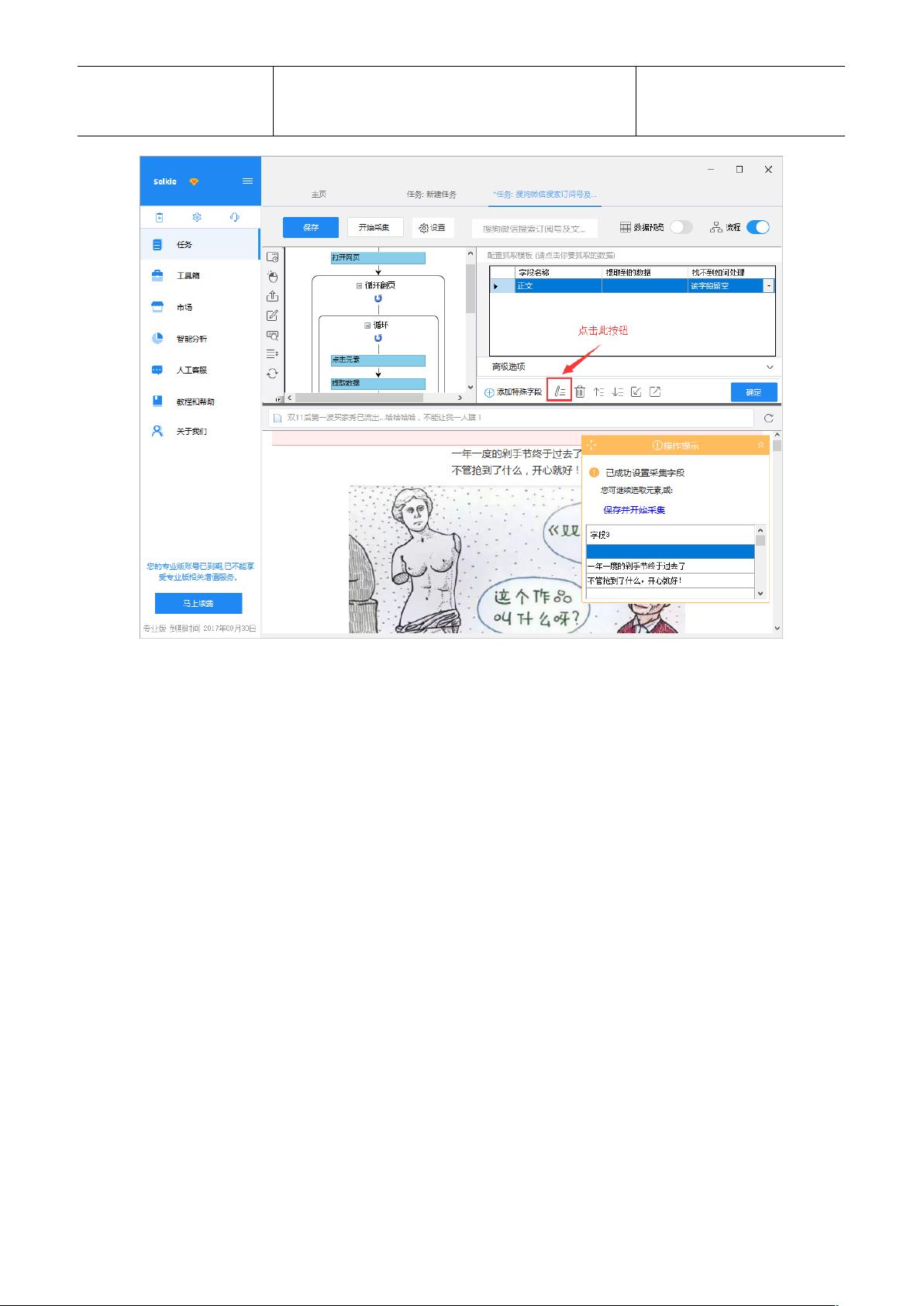
3. **文本采集** - 对于每一页,需要捕获文章正文中的文本。在“点击元素”的高级选项中,确保正确选择和定位到文本区域,以便抓取内容。
4. **图片URL采集** - 如果需要包括图片,需在“元素属性”或类似选项中查找图片链接,可能需要结合CSS选择器或者XPath表达式来定位,然后保存或下载图片链接。
5. **自动化执行** - 完成设置后,可以设置定时任务或一键执行,让八爪鱼自动按照预设的逻辑持续抓取数据,大大节省了手动操作的时间。
总结来说,掌握网页文章正文采集方法不仅限于微信文章,而是适用于任何支持网络抓取的网站。通过熟练运用八爪鱼等工具,不仅可以提升效率,还能为数据分析、内容整合等应用场景提供有力支持。
编号:
时间:2021 年 x 月 x 日
书山有路勤为径,学海无涯苦作舟
页码:第 12 页 共 69 页
第 12 页 共 69 页
网页文章正文采集步骤 11
注意:在字段表中,可进行字段的自定义修改

剩余68页未读,继续阅读
2023-06-10 上传
2023-02-24 上传
2023-05-31 上传
2023-05-30 上传
2023-05-27 上传
2023-09-22 上传
2023-09-04 上传
2023-06-01 上传

猫一样的女子245
- 粉丝: 221
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型智能电加热器:触摸感应与自动温控技术
- 社区物流信息管理系统的毕业设计实现
- VB门诊管理系统设计与实现(附论文与源代码)
- 剪叉式高空作业平台稳定性研究与创新设计
- DAMA CDGA考试必备:真题模拟及章节重点解析
- TaskExplorer:全新升级的系统监控与任务管理工具
- 新型碎纸机进纸间隙调整技术解析
- 有腿移动机器人动作教学与技术存储介质的研究
- 基于遗传算法优化的RBF神经网络分析工具
- Visual Basic入门教程完整版PDF下载
- 海洋岸滩保洁与垃圾清运服务招标文件公示
- 触摸屏测量仪器与粘度测定方法
- PSO多目标优化问题求解代码详解
- 有机硅组合物及差异剥离纸或膜技术分析
- Win10快速关机技巧:去除关机阻止功能
- 创新打印机设计:速释打印头与压纸辊安装拆卸便捷性
