中文共指消解新方法:基于特征分选策略
需积分: 0 125 浏览量
更新于2024-08-05
收藏 263KB PDF 举报
"基于特征分选策略的中文共指消解方法1"
中文共指消解是自然语言处理领域中的一个重要任务,它旨在识别文本中具有相同指代含义的名词短语,以帮助理解和解析复杂的语言结构。传统的共指消解方法主要依赖规则和手工编写的特征,而近年来,随着机器学习技术的发展,基于机器学习的共指消解方法逐渐成为主流。
本文针对基于机器学习的中文共指消解存在的问题,特别是不同类别名词短语特征向量的使用差异,提出了一个创新性的特征分选策略。这个策略在特征选择阶段对人称代词和普通名词短语采取不同的处理方式,旨在更有效地利用各类名词短语的特性,同时减少无效特征对模型的干扰。无效特征在共指消解过程中可能会产生“噪声”,降低模型的准确性。
在特征分选策略中,首先对所有可能的特征进行分析,包括但不限于词汇、语法、上下文信息等。对于人称代词,由于其特殊的指代性质,可能需要考虑更多的语境信息和角色关系;而对于普通名词短语,可能需要关注它们的共现频率、词性、修饰词等特征。通过这种方法,可以有针对性地提取出对共指消解最有帮助的特征,提升模型的泛化能力和消解效果。
实验结果显示,采用这种特征分选策略的中文共指消解方法在性能上有显著提升,F值达到了80.72%,这表明该方法在保持较高精度的同时,也具有较好的召回率,能有效提升共指消解的整体性能。
此外,文章还提到了支撑向量机(SVM)作为潜在的分类器,这表明作者可能将SVM应用到特征选择后的模型训练中,利用SVM的强大分类能力来判断名词短语之间的共指关系。数据词典也可能在此过程中起到关键作用,提供预定义的实体信息,帮助模型更好地理解名词短语的语义。
关键词涵盖了共指消解的核心概念,如特征选择、自然语言处理和支撑向量机,这些都是实现高效共指消解的关键技术。同时,数据词典也是解决中文共指消解问题时不可或缺的工具,它可以提供丰富的先验知识,帮助系统准确识别实体和它们的共指关系。
这篇文章提出的基于特征分选策略的中文共指消解方法,通过优化特征选择过程,提高了模型在处理中文文本时的共指消解能力,为中文自然语言处理领域的研究提供了新的思路和方法。
基于特征分选策
基于特征分选策基于特征分选策
基于特征分选策略的中文共指消解
略的中文共指消解略的中文共指消解
略的中文共指消解方法
方法方法
方法
李渝勤
李渝勤李渝勤
李渝勤
1,2
,
,,
,甘润生
甘润生甘润生
甘润生
1
,
,,
,杨永红
杨永红杨永红
杨永红
3
,
,,
,施水才
施水才施水才
施水才
1,2
(1. 北京信息科技大学计算机学院,北京 100101;2. 北京拓尔思信息技术股份有限公司,北京 100101;
3. 中山大学信息科学与技术学院计算机科学系,广州 510275)
摘
摘摘
摘 要
要要
要:
::
:针对基于机器学习的中文共指消解中不同类别名词短语特征向量的使用差异,提出一种基于特征分选策略的方法。该方法在选择
特征向量时对人称代词和普通名词短语分别处理,充分利用不同名词短语的已有特征进行共指消解,并减少部分无效特征在共指消解过程
中产生的“噪声”。实验结果表明,该中文共指消解方法能提高共指消解的性能,
F
值达到 80.72%。
关键词
关键词关键词
关键词:
::
:共指消解;特征选择;自然语言处理;支撑向量机;数据词典
Chinese Coreference Resolution Method
Based on Feature Respective Selection Strategy
LI Yu-qin
1,2
, GAN Run-sheng
1
, YANG Yong-hong
3
, SHI Shui-cai
1,2
(1. Computer School, Beijing Information Science & Technology University, Beijing 100101, China;
2. Beijing TRS Information Technology Co. Ltd., Beijing 100101, China;
3. School of Information Science and Technology, Sun Yat-Sen University, Guangzhou 510275, China)
【
【【
【Abstract】
】】
】This paper studies different features based up on the type of noun phrase in Chinese coreference resolution based on machine learning,
and proposes features selection strategy to be applied to coreference resolution, the approach selects pronouns and other noun phrases features
respectively, so this method can reduce some “noise” and utilize features effectively. Experimental results show that the method can improve the
performance of coreference resolution system, and F-measure reaches 80.72%.
【
【【
【Key words】
】】
】coreference resolution; feature selection; nature language processing; Support Vector Machine(SVM); data dictionary
DOI: 10.3969/j.issn.1000-3428.2011.18.059
计 算 机 工 程
Computer Engineering
第 37 卷 第 18 期
Vol.37 No.18
2011 年 9 月
September 2011
·
··
·人工智能及识别技术
人工智能及识别技术人工智能及识别技术
人工智能及识别技术·
··
·
文章编号
文章编号文章编号
文章编号:
::
:1000—
——
—3428(2011)18—
——
—0180—
——
—03
文献标识码
文献标识码文献标识码
文献标识码:
::
:A
中图分类号
中图分类号中图分类号
中图分类号:
::
:TP391
1
概述
概述概述
概述
共指现象广泛存在于自然语言的各种表达中,表示篇章
中的一个语言单位与之前出现的语言单位存在语义上的关联
(
本文不讨论回指和零指
)
,用于指向的语言单位称为照应语,
被指向的语言单位为先行语。确定照应语和先行语之间关系
的过程就是共指消解,类型一般有人称代词消解和名词短语
消解。
共指消解方法早期侧重于理论的研究,在自然语言处理
技术发展的带动下,多数研究偏向基于机器学习的方法
[1-2]
。
当前很多的研究更侧重于挖掘更多的有效信息作为特征用于
共指消解,研究其对共指消解性能的作用
[3]
。
相对于英语来说,中文共指消解的研究起步较晚,且还
不够深入,但几十年来,学者在相关方面也取得了一定的成
果
[4-5]
。在前人共指消解研究中发现,特征向量的选择对系统
的最终性能有很大的影响。使用相同的机器学习方法,但选
取不同的特征向量,系统的性能可能有较大的差异。一些研
究者在共指消解研究中没有对名词短语的类别进行细分和区
别处理,也没有深入考虑人称代词和其他名词短语的差异,
在特征选取和处理方式上不尽相同。本文针对人称代词和其
他名词短语分别选取特征,对不同特征构建的实例利用支撑
向量机
(Support Vector Machine, SVM)
分类器进行分类。
2
共指消解平台
共指消解平台共指消解平台
共指消解平台
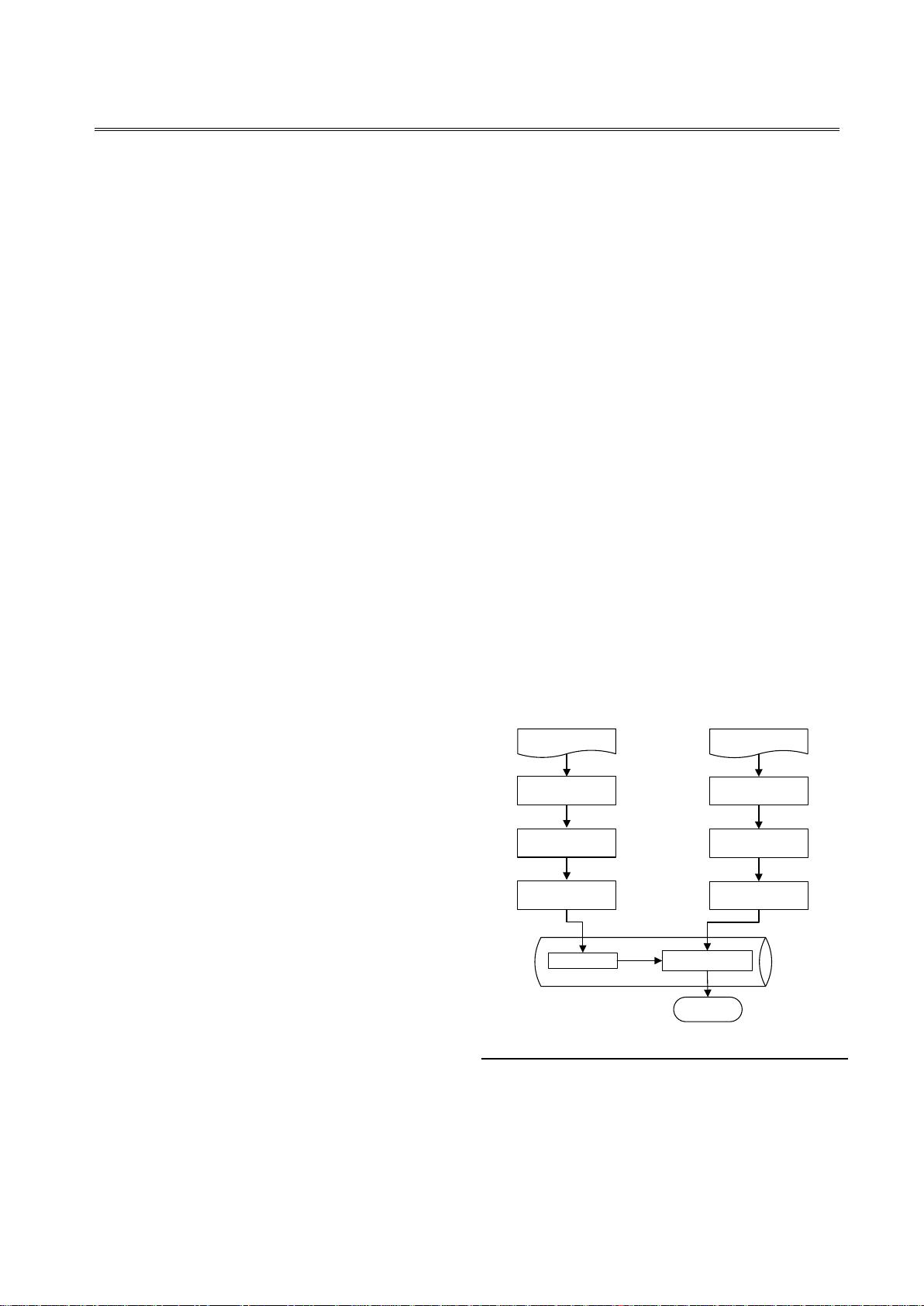
本文的系统平台是在文献
[1]
的基础上实现,根据流程构
建出如图
1
所示的共指消解基本框架。从图
1
可看出,本文
的共指消解系统由预处理、特征向量选择、训练和测试实例
构造、机器学习算法
(SVM)
,以及消解结果构成。
训练语料
测试语料
预处理
预处理
特征向量的选择和表示
特征向量的选择和表示
构建训练实例
构建测试实例
SVM分类器
模型文件 预测消解项正负关系
消解结果
图
图图
图
1
共指消解流程
共指消解流程共指消解流程
共指消解流程
基金项目
基金项目基金项目
基金项目:
::
:国家“863”计划基金资助重点项目(2006AA010105);
国家自然科学基金资助项目(60772081);北京市自然科学基金资助
项目(4092015);北京市教委科技发展计划基金资助项目(KM201010
772023)
作者简介
作者简介作者简介
作者简介:
::
:李渝勤(1963-),女,副研究员,主研方向:中文信息处
理,信息检索;甘润生,硕士研究生;杨永红,讲师;施水才,
教授
收稿日
收稿日收稿日
收稿日期
期期
期:
::
:2011-03-02 E-mail:
::
:wsgrs@126.com
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-12 上传
2022-12-15 上传
2022-07-15 上传
2018-09-07 上传
2021-01-27 上传
2021-09-21 上传

乔木Leo
- 粉丝: 31
- 资源: 301
 我的内容管理
展开
我的内容管理
展开







最新资源
- OO Principles.doc
- Keil C51程序设计中几种精确延时方法.doc
- 基于单片机的智能遥控小汽车
- 利用asp.net Ajax和sqlserver2005实现电子邮件系统
- 校友会网站需求说明书
- Microsoft Windows Internals (原版PDF)
- 软件测试工具的简单介绍
- 2009年上半年软件评测师下午题
- 2009年上半年软件评测师上午题
- linux编程从入门到提高-国外经典教材
- 2009年上半年网络管理员下午题
- 2009年上半年系统集成项目管理师下午题
- 2009年上半年系统集成项目管理师上午题
- 数据库有关的中英文翻译
- 2009年上半年系统分析师下午题II
- 2009年上半年系统分析师上午题
