隐马尔可夫模型在汉字输入法中的优化应用
需积分: 33 121 浏览量
更新于2024-07-24
1
收藏 642KB PPT 举报
"本文主要探讨了隐马尔可夫模型(HMM)及其在自然语言处理(NLP)中的应用,从拼音输入法的角度出发,深入分析了汉字编码、输入效率和歧义解决策略,并讨论了利用上下文信息提高输入速度的方法。"
在自然语言处理领域,隐马尔可夫模型是一种广泛应用的概率模型,它被广泛用于建模序列数据,如语音识别、机器翻译和词性标注等任务。在本文中,作者首先通过介绍拼音输入法来引出问题,指出汉字输入的本质是将汉字的形状信息转化为计算机可识别的编码。早期的输入法如微软双拼存在编码歧义和击键时间较长的问题,而五笔输入法则需要拆字,虽然减少了编码长度,但增加了寻键时间。
接着,文章讨论了输入一个汉字的平均击键次数,引入了信息论的概念,如信息熵,指出理想情况下,每个汉字的编码长度应与其信息熵成正比。通过统计分析,发现汉字信息熵大约在10比特,而一个字母代表的信息量约为4.7比特,这意味着输入一个汉字理论上需要2.1次键击。考虑到词组和上下文,这个数字可以进一步降低,但实际应用中受限于词库大小和模型复杂性。
在解决汉字输入的歧义性问题上,文章提到了建立大词库和上下文相关的统计语言模型,比如基于隐马尔可夫模型的词性标注和语言模型,能够有效地减少多音字和词的混淆。然而,这种方法在处理复杂的语言现象时仍有局限,例如未登录词和长距离依赖。
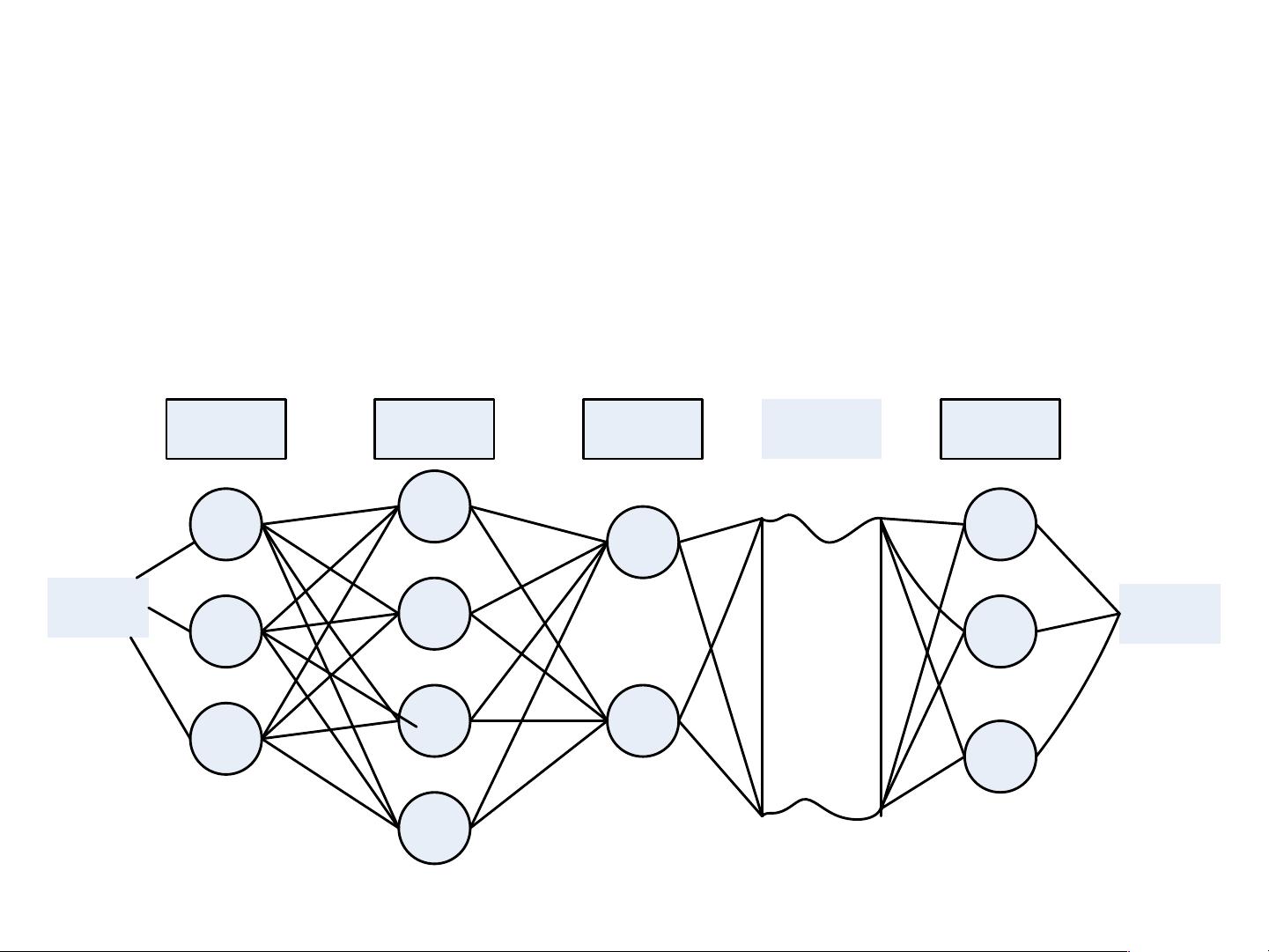
隐马尔可夫模型在NLP中的核心思想是利用隐藏状态来描述序列的生成过程,而观察到的序列只是这些状态的投影。在拼音输入法中,可以将每个汉字看作是隐藏状态,而我们看到的拼音序列是这些状态的观测。通过Viterbi算法或者 Baum-Welch 算法,我们可以找到最可能的汉字序列,从而有效地解决一音多字的问题。
隐马尔可夫模型在自然语言处理中起到了关键作用,特别是在解决序列数据的建模和预测问题上。通过与拼音输入法的结合,HMM帮助我们理解如何利用上下文信息和统计模型来提高汉字输入的效率,降低了用户的输入负担,推动了自然语言处理技术的发展。

•
若以词为单位统计汉字信息熵,则为 8 比特
8/4.7 ≈1.7
•
若考虑上下文相关性,建立基于词的统计语
言模型,则汉字信息熵为 6 比特左右
6/4.7 ≈1.3
•
实际上达不到这个理论极限值
–
词组的编码
–
模型的规模

剩余57页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
123 浏览量
319 浏览量
172 浏览量
点击了解资源详情
2024-10-26 上传

haining098
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 初学者入门必备!Visual C++开发的连连看小程序
- C#实现SqlServer分页存储过程示例分析
- 西门子工业网络通信例程解读与实践
- JavaScript实现表格变色与选中效果指南
- MVP与Retrofit2.0相结合的登录示例教程
- MFC实现透明泡泡效果与文件操作教程
- 探索Delphi ERP框架的核心功能与应用案例
- 爱尔兰COVID-19案例数据分析与可视化
- 提升效率的三维石头制作插件
- 人脸C++识别系统实现:源码与测试包
- MishMash Hackathon:Python编程马拉松盛事
- JavaScript Switch语句练习指南:简洁注释详解
- C语言实现的通讯录管理系统设计教程
- ASP.net实现用户登录注册功能模块详解
- 吉时利2000数据读取与分析教程
- 钻石画软件:从设计到生产的高效解决方案
