帕尔默企鹅数据集:基于分类与聚类的模式识别系统实现详解
需积分: 5 25 浏览量
更新于2024-08-04
收藏 798KB DOC 举报
本文档深入探讨了基于分类和聚类算法的模式识别系统的设计与实现,以帕尔默企鹅数据集作为实验对象。研究内容涵盖了整个系统的构建流程,主要包括数据获取、预处理、特征提取、分类决策和分类器设计。
1. 数据获取与预处理:首先,作者从现有的Palmer Penguin Dataset中获取数据,并确保数据质量,删除空值并检查是否存在异常值。这是模式识别的基础,确保数据的准确性对于后续分析至关重要。
2. 特征提取:采用主成分分析(PCA)技术,这是一种常用的维度ality reduction方法,用于降低数据的复杂性,同时保留关键信息。通过PCA,可以将原始特征转换为一组新的、线性无关的特征,便于后续的分类和聚类操作。
3. 分类决策与方法:设计者运用了多种机器学习算法,如决策树、KNN(K-近邻算法)、逻辑回归、梯度提升决策树以及K-means聚类算法。这些算法的选择体现了对不同分类策略的理解和实践,每个算法都有其适用场景和优缺点。
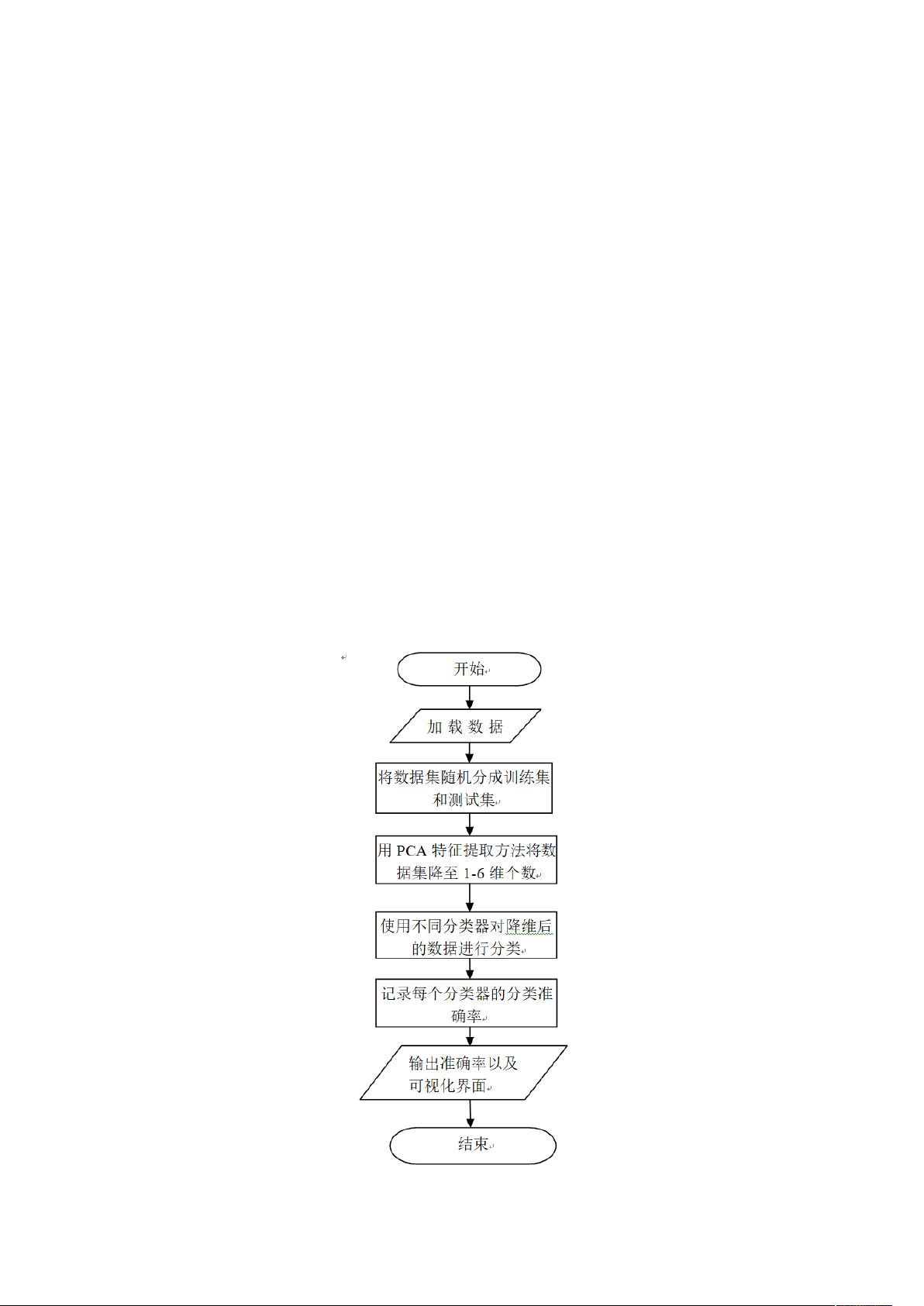
4. 系统流程图:文中提供了一张详细的系统流程图,展示了整个模式识别系统的架构,包括数据输入、预处理、特征处理、模型训练和结果分析等步骤,有助于理解和执行系统。
5. 实验环境:硬件方面,使用了Intel Core i5-6300HQ处理器和16GB内存的计算机,操作系统为Windows 10。软件环境则是Python 3.6在PyCharm平台上开发,这些都是实现项目的关键工具。
6. 数据集描述:帕尔默企鹅数据集包含了3种企鹅种类(Adelie、Chinstrap和Gentoo)的六个特征,如岛屿、喙部尺寸、鳍长度等,共计343个样本。数据进行了标准化处理,便于模型学习。
7. 实现代码:文档中可能会包含这些算法的具体实现代码,这对于读者理解算法原理和应用于实际项目具有很高的参考价值。
通过本文档的学习,读者不仅能了解到模式识别系统的具体设计过程,还能掌握如何运用分类和聚类算法解决实际问题,提升数据分析和编程技能。
题目 基于分类和聚类算法的模式识别系统的设计与实现
1.1 题目的主要研究内容
(1)根据课上所学模式识别系统主要的组成内容,本设计使用帕尔默企鹅
数据集(Palmer Penguin Dataset)进行实验,主要内容分为以下几个方面:数
据获取、数据预处理、特征提取、分类决策和分类器设计 5 个部分。首先获取
数据,对现有数据集进行获取;接着对获取的数据进行预处理,使用代码删除
数据中的空值,数据中没有异常值;然后使用课上所讲的 PCA 主成分分析法
对特征进行降维和提取;通过课上总结和课下所学对数据进行分类决策,本设
计使用了决策树、KNN、逻辑回归、梯度提升决策树、K-means 几种分类和聚
类方法进行决策;最后设计以上分类决策的分类器实现数据的模式识别以及对
结果进行分析。
(2)系统流程图
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
1308 浏览量
2022-10-19 上传
2022-10-19 上传
2022-10-19 上传
126 浏览量
123 浏览量
145 浏览量

李逍遥敲代码
- 粉丝: 2992
 我的内容管理
展开
我的内容管理
展开







最新资源
- 易酷免费影视系统:开源网站代码与简易后台管理
- Coursera美国人口普查数据集及使用指南解析
- 德加拉6800卡监控:性能评测与使用指南
- 深度解析OFDM关键技术及其在通信中的应用
- 适用于Windows7 64位和CAD2008的truetable工具
- WM9714声卡与DW9000网卡数据手册解析
- Sqoop 1.99.3版本Hadoop 2.0.0环境配置指南
- 《Super Spicy Gun Game》游戏开发资料库:Unity 2019.4.18f1
- 精易会员浏览器:小尺寸多功能抓包工具
- MySQL安装与故障排除及代码编写全攻略
- C#与SQL2000实现的银行储蓄管理系统开发教程
- 解决Windows下Pthread.dll缺失问题的方法
- I386文件深度解析与oki5530驱动应用
- PCB涂覆OSP工艺应用技术资源下载
- 三菱PLC自动调试台程序实例解析
- 解决OpenCV 3.1编译难题:配置必要的库文件
