Spark部署与架构详解:Master、Worker与Driver的角色
Spark概述
Spark是一个开源的大数据处理框架,它以其高效、内存计算为核心优势,被广泛应用于实时流处理和批处理任务。系统部署是Spark集群设置的重要步骤,包括Master节点和Worker节点的分工。
Master节点是集群的管理和协调中心,常驻有Master守护进程。这个守护进程负责监控和管理所有的Worker节点,确保任务的调度和分配。它接收来自Driver(运行用户自定义Spark应用程序的进程)的任务请求,并将它们分发给Worker节点。例如,在本地模式下运行`./bin/run-exampleSparkPi10`时,Master节点就是Driver的运行位置;而在YARN集群中,Driver可能会被调度到Worker节点上。
Driver在Spark架构中扮演着至关重要的角色,它执行main()函数创建SparkContext,负责应用程序的初始化和配置。用户编写的Spark程序(如WordCount.scala)就是Driver程序。直接在PC上通过`val sc = new SparkContext("spark://master:7077", "AppName")`连接Master,虽然简单,但并不推荐,因为PC可能与Worker节点不在同一局域网,导致通信延迟。
Worker节点是执行实际计算任务的地方。每个Worker上运行一个或多个ExecutorBackend进程,每个进程包含一个Executor对象,Executor持有多个线程,这些线程构成了一个任务池。Executor负责执行由Driver提交的任务(Tasks),每个任务在Executor的一个独立线程中运行。在一个典型的Standalone部署中,每个Worker实例化的是CoarseGrainedExecutorBackend进程,这意味着每个Worker只有一个Executor实例,但可以通过配置文件调整Executor的数量,这有助于提高并发性和资源利用率。
在实践中,对于大型集群,可能需要配置多个Executor以支持更复杂的任务分布和并行计算。然而,具体配置取决于应用需求、硬件资源以及网络环境等因素。理解Master、Worker和Driver的角色,以及它们之间的交互,是有效管理和优化Spark集群的关键。通过深入学习Spark源码分析,开发者可以更好地理解和优化集群性能,确保任务的高效执行。
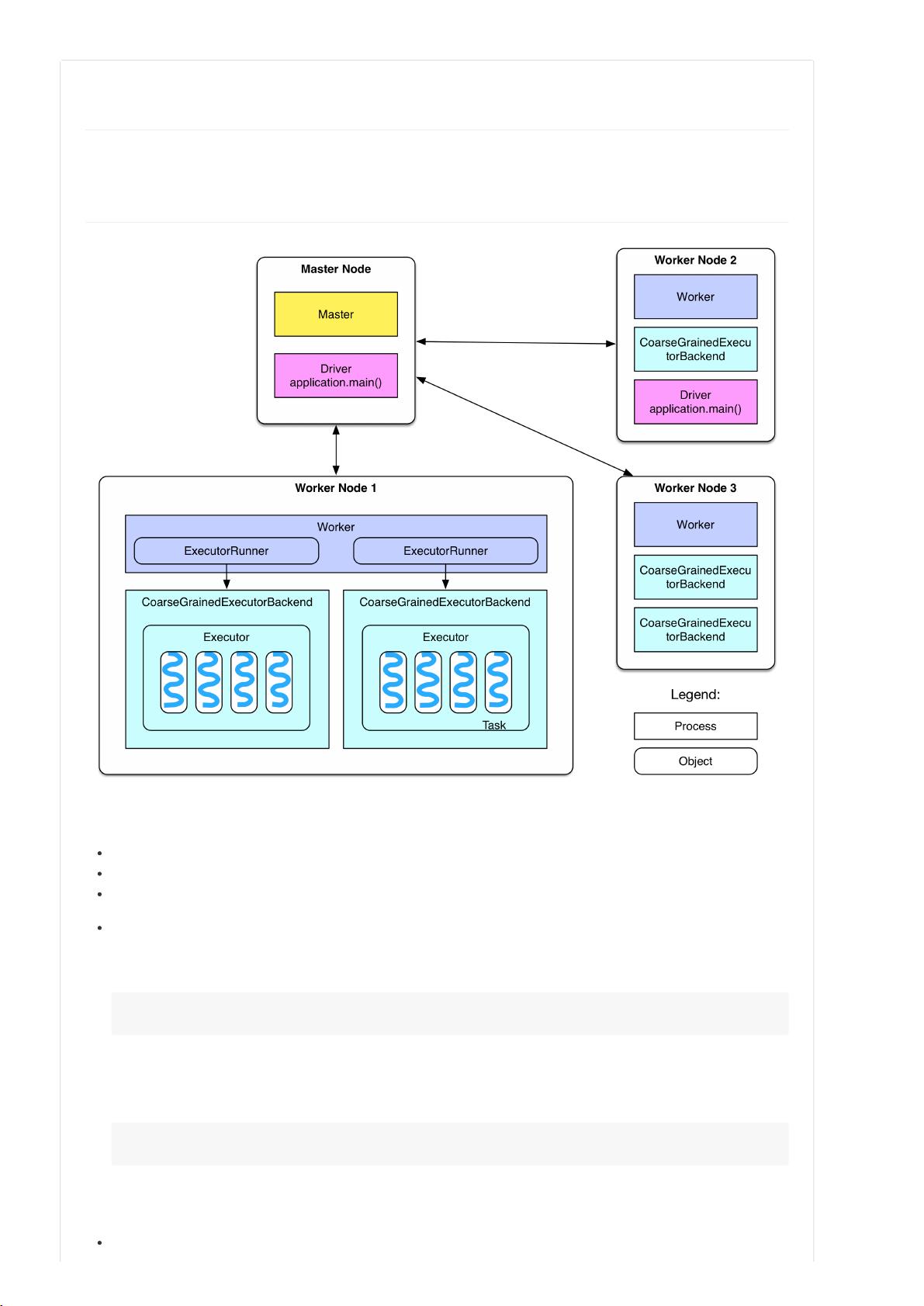
拿到系统后,部署系统是第一件事,那么系统部署成功以后,各个节点都启动了哪些服务?
从部署图中可以看到
整个集群分为 Master 节点和 Worker 节点,相当于 Hadoop 的 Master 和 Slave 节点。
Master 节点上常驻 Master 守护进程,负责管理全部的 Worker 节点。
Worker 节点上常驻 Worker 守护进程,负责与 Master 节点通信并管理 executors。
Driver 官方解释是 “The process running the main() function of the application and creating the SparkContext”。
Application 就是用户自己写的 Spark 程序(driver program),比如 WordCount.scala。如果 driver program 在
Master 上运行,比如在 Master 上运行
./bin/run‐exampleSparkPi10
那么 SparkPi 就是 Master 上的 Driver。如果是 YARN 集群,那么 Driver 可能被调度到 Worker 节点上运行(比如上
图中的 Worker Node 2)。另外,如果直接在自己的 PC 上运行 driver program,比如在 Eclipse 中运行 driver
program,使用
valsc=newSparkContext("spark://master:7077","AppName")
去连接 master 的话,driver 就在自己的 PC 上,但是不推荐这样的方式,因为 PC 和 Workers 可能不在一个局域网,
driver 和 executor 之间的通信会很慢。
每个 Worker 上存在一个或者多个 ExecutorBackend 进程。每个进程包含一个 Executor 对象,该对象持有一个线程
概览
部署图
下载后可阅读完整内容,剩余5页未读,立即下载
2015-01-04 上传
2018-11-04 上传
2018-12-23 上传
133 浏览量
2019-01-14 上传
2018-01-05 上传
2021-03-10 上传
2019-04-14 上传
2019-06-25 上传

cc_wx
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android应用源码利用poi将内容填到word模板-IT计算机-毕业设计.zip
- mdi-es:材料设计图标导出为ES模块
- LocationSearch
- 行业文档-设计装置-一种利用浸胶纸作为过渡联接体的胶合板.zip
- ImageProcessingApp:使用流行的MVC架构的图像处理应用程序
- hideandseek:Hide & Seek 是一款开源的多人在线街机游戏,对抗两支捉迷藏者团队,玩法有趣快节奏。 项目已从 https 移出
- angular-first-app
- 数据库课程设计-家庭理财管理.zip
- MochaBabelCoverage:一个 Mocha 运行器,支持对包含 JSX 的文件运行 Mocha,并支持覆盖率报告
- 脑机接口BCI-eeglab安装包
- grantwforsythe.github.io
- 性能测试工具LoadRunner书籍(14本)目录知识点(思维导图加图).rar
- ArgRouter:为js函数添加重载功能
- 2D形状
- android应用源码合肥工业大学客户端源码-IT计算机-毕业设计.zip
- PdfFormFillerUTF-8:带有命令行或 WWW 界面的简单 PDF Form Filler 实用程序。-开源
