YOLOv5改进详解:CSPDarkNet53、SPP与自适应策略
121 浏览量
更新于2024-08-04
1
收藏 1.21MB DOCX 举报
"这篇文档详细介绍了YOLOv5的改进思想和关键组件,包括不同的模型大小,如Yolov5s、Yolov5m、Yolov5l和Yolov5x,以及一系列技术优化,如CSPDarkNet53+Focus作为backbone,SPP+PAN在neck部分,还有自适应图片缩放、数据增强策略、自适应锚框计算、LeakyReLU和Sigmoid激活函数、GIOU损失函数以及跨网格预测的Loss计算方法。"
YOLOv5系列模型的改进主要体现在以下几个方面:
1. **Backbone**:YOLOv5采用了CSPDarkNet53结构,这是一种结合了Cross Stage Partial (CSP)块的DarkNet53网络。CSP结构旨在减少计算量,提高模型效率,同时保持或提升性能。CSPDarkNet53通过将信息在不同阶段之间部分地回传,减少了信息的丢失。
2. **Focus模块**:引入Focus结构来改善信息下采样的过程。Focus通过周期性地抽取高分辨率图像中的像素点并堆叠到低分辨率图像中,将wh维度信息转移到c通道空间,增大每个点的感受野,同时减少信息丢失。这有助于在网络早期阶段保留更多细节。
3. **Neck部分**:YOLOv5引入了Spatial Pyramid Pooling (SPP)模块,它通过不同大小的池化层(如5x5、9x9、13x13)增加模型的感受野,然后将结果concatenation起来,增强了特征提取能力。此外,YOLOv5的Neck部分还采用了CSP2结构,进一步优化了特征融合。
4. **自适应图片缩放**:YOLOv5允许自适应地调整输入图像的大小,以适应不同大小的目标物体,提高检测效果。
5. **数据增强**:采用了马赛克(Mosaic)数据增强技术,它随机混合不同图像的四角,增加了训练数据的多样性,提高了模型的泛化能力。
6. **自适应锚框计算**:YOLOv5改进了锚框的生成方式,使其能更好地适应不同尺寸和比例的目标物体。
7. **激活函数**:模型使用了LeakyReLU和Sigmoid激活函数,LeakyReLU解决了ReLU在负区的死亡神经元问题,而Sigmoid用于预测边界框的概率。
8. **损失函数**:采用了Generalized Intersection over Union (GIOU)损失函数,这是一种改进的IoU,即使在边界框不重叠时也能提供梯度,从而改进了训练过程。
9. **跨网格预测**:YOLOv5使用了一种新的Loss计算方法,跨网格预测能够更精确地估计边界框的位置和大小。
这些改进使得YOLOv5在保持快速检测速度的同时,提高了目标检测的精度。根据不同的应用场景,可以选择不同规模的模型,如Yolov5s追求速度,而Yolov5m、Yolov5l和Yolov5x则倾向于更高的精度。
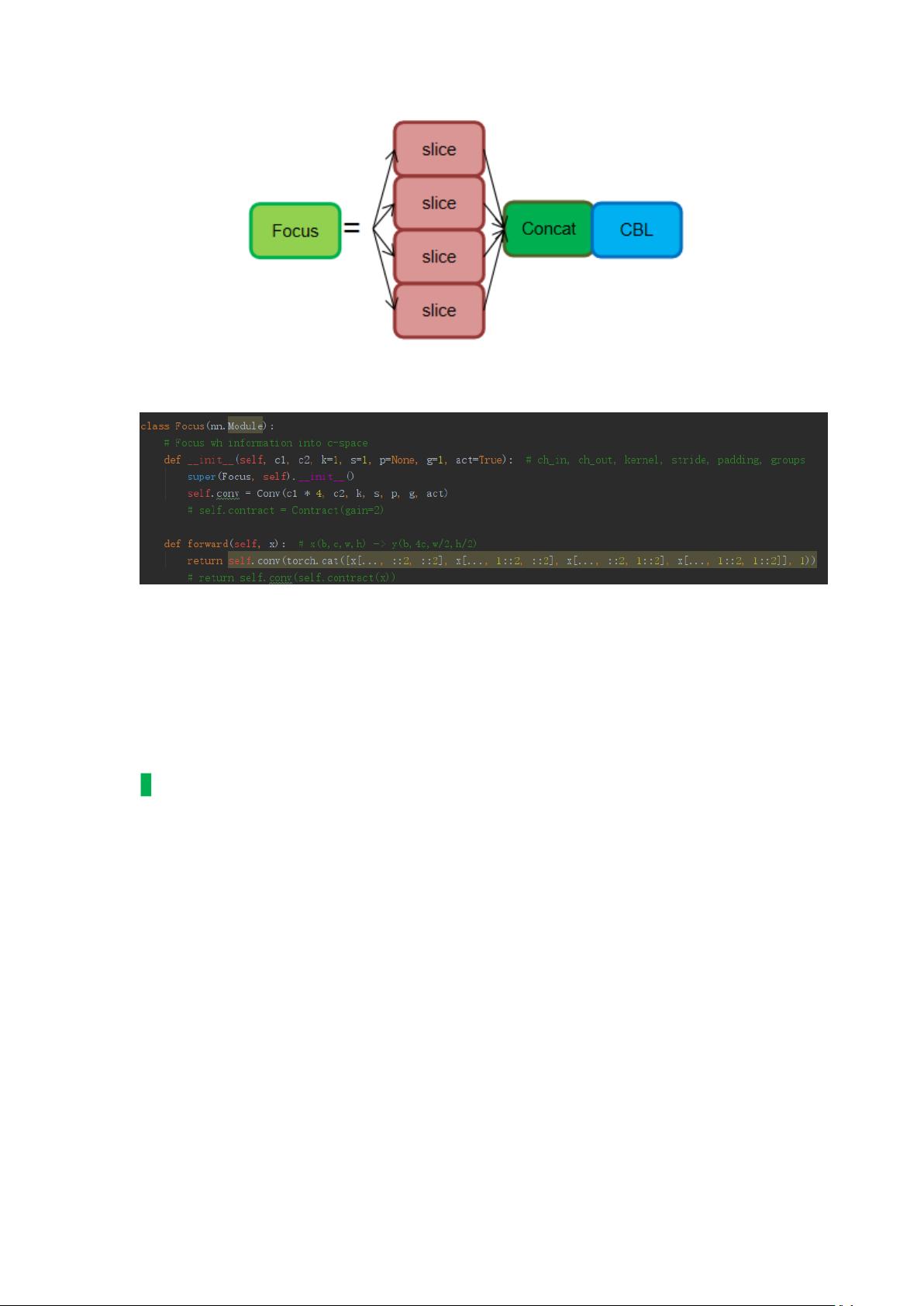
为什么要加 fucus?其最大好处是可以最大程度的减少信息损失而进行下采样
操作。
CSP(跨阶段局部网络)跨阶段局部网络缓解以前需要大量推理计算的问
题。
Yolov4 中只有主干网络使用了 CSP 结构,而 Yolov5 中设计了两种 CSP 结
构。
以 Yolov5s 网络为例,CSP1_X 结构应用于 Backbone 主干网络,另一种
CSP2_X 结构则应用于 Neck 中。
Yolov4 的 Neck 结构中,采用的都是普通的卷积操作。
Yolov5 的 Neck 结构中,采用借鉴 CSPnet 设计的 CSP2 结构,加强网络
特征融合的能力。
剩余13页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-06-04 上传
2023-06-07 上传
2022-08-19 上传
2024-06-03 上传
2024-06-20 上传
2022-12-15 上传

sun7bear
- 粉丝: 1
- 资源: 121
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
