大数据技术:超越Hadoop的实时分析处理
需积分: 10 178 浏览量
更新于2024-07-19
收藏 1.8MB PDF 举报
"大数据技术——超越Hadoop,实时分析处理与Spark和Shark的应用"
在大数据领域,Hadoop是最初的关键技术之一,它为大规模数据处理提供了一个分布式框架。然而,随着大数据需求的不断增长,单纯依赖Hadoop已经不能满足所有需求,特别是对于实时分析处理(Real-Time Analytical Processing, RTAP)的需求。RTAP的目标是在数据流式摄入和处理的同时,实时查询和展示数据,以便快速获取洞察。
Spark是一个快速、通用且可扩展的大数据处理引擎,它弥补了Hadoop在实时处理上的不足。Spark提供了一种内存计算模型,使得数据处理速度比传统的磁盘基础的Hadoop MapReduce快上许多倍。而Shark是基于Spark的一个SQL查询接口,它允许用户使用SQL语言对大数据进行交互式分析,进一步增强了Spark的易用性和实用性。
在实时分析处理中,数据不仅被实时摄入,而且可以在线查询和呈现,同时结合实时和历史数据进行交互式挖掘。这种处理方式主要基于内存,充分利用集群中的主内存,从而实现超过100倍的速度提升。
除了实时分析,高级机器学习和数据挖掘(MLDM)也是大数据领域的重要组成部分。例如,信息检索中的PageRank算法,用于评估网页的重要性;推荐系统,利用用户行为和兴趣模式来提供个性化推荐;以及图并行预测分析,这是一种非SQL的预测分析方法,特别适用于处理复杂网络结构的数据,如社交网络或交易网络。
Spark和Shark的结合为这些高级应用提供了平台。Spark的弹性分布式数据集(Resilient Distributed Datasets, RDDs)使得数据处理变得高效且容错,而Shark则通过SQL接口简化了数据分析的复杂性,使得非专业程序员也能进行复杂的分析任务。
案例研究通常会展示如何利用Spark和Shark实现实时分析处理。例如,一个电商公司可能会使用Spark实时处理用户的购买行为数据,通过Shark进行快速的SQL查询,实时分析用户偏好,即时调整推荐策略,从而提高销售效率和客户满意度。
大数据技术已经超越了Hadoop的范畴,涵盖了实时分析、内存计算、高级机器学习和数据挖掘等多个方面。Spark和Shark的出现,为大数据处理提供了新的解决方案,推动了大数据应用的实时化和智能化。
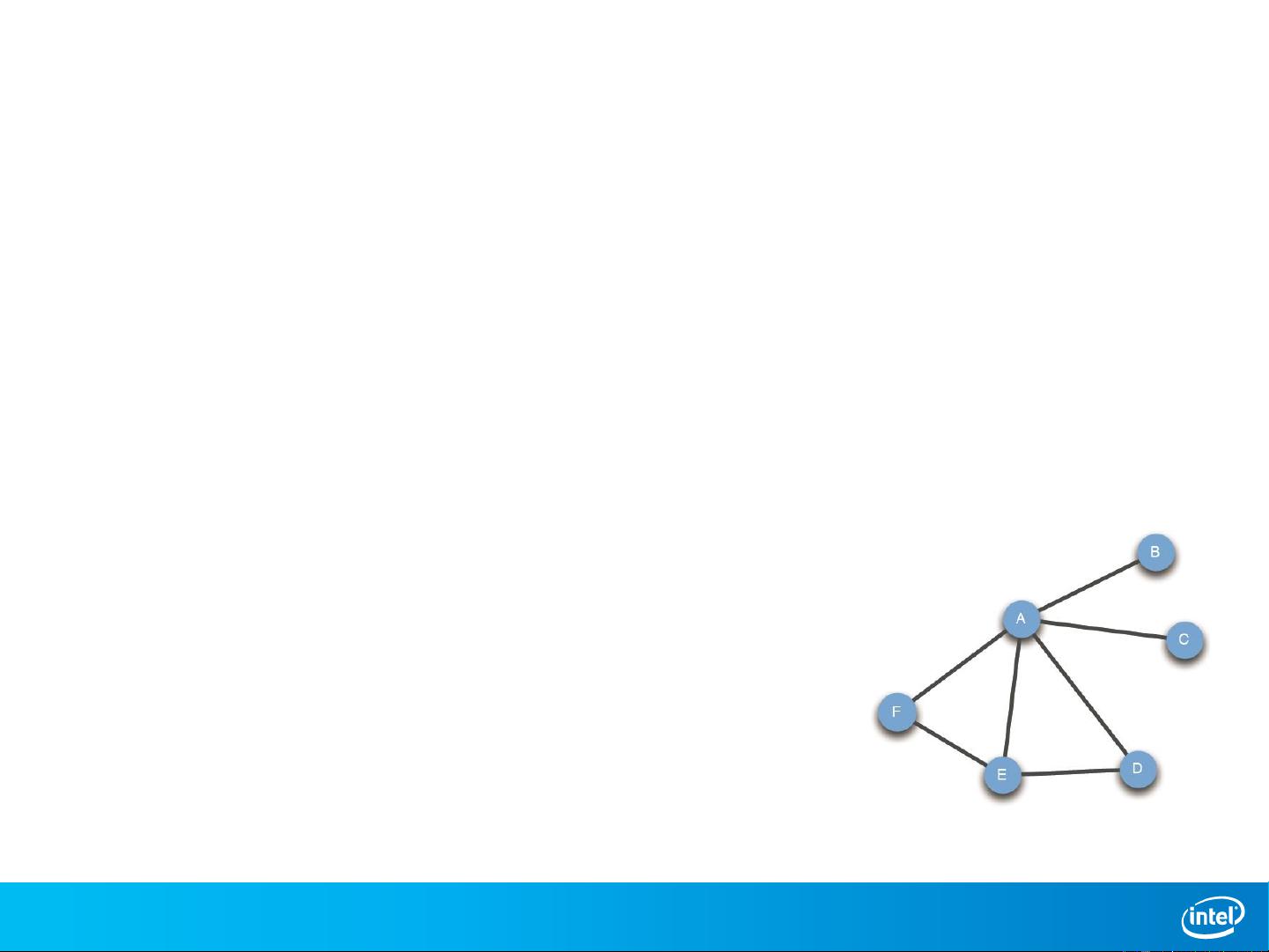
Advanced, Graph-Parallel MLDM
Advanced machine learning and data mining (MLDM)
• Information retrieval (e.g., page rank)
• Recommendation engine (e.g., ALS)
• Social network analysis (e.g., clustering)
• Natural language processing (e.g., NER)
• …
Graph parallel computations
• A sparse graph G(V, E)
• A vertex program P runs on each vertex in parallel
& repeatedly
• Vertices interact along edges
剩余23页未读,继续阅读
2022-07-13 上传
2023-10-04 上传
2022-05-06 上传
2022-10-20 上传
2014-01-23 上传

qq_33889924
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
