大规模深度强化学习在Dota 2中的应用
需积分: 13 157 浏览量
更新于2024-07-15
收藏 8.4MB PDF 举报
"这篇PDF文档是关于OpenAI团队利用大规模深度强化学习在Dota 2游戏中取得突破的研究。在2019年4月13日,OpenAI Five成为了首个战胜电子竞技游戏Dota 2世界冠军的人工智能系统。Dota 2游戏中的长时间跨度、不完全信息以及复杂连续的状态-动作空间对AI系统提出了新的挑战,这些挑战对于构建更强大的AI系统至关重要。OpenAI Five通过扩展现有的强化学习技术,实现了每两秒大约学习200万个帧的训练速率。他们开发了一套分布式训练系统和持续训练工具,使得OpenAI Five能够连续训练10个月,并最终击败了Dota 2的世界冠军队伍。"
在这篇研究中,OpenAI团队主要关注的是如何运用深度强化学习来解决复杂环境下的策略问题,特别是针对像Dota 2这样的多人在线战斗竞技游戏。深度强化学习是机器学习的一个分支,它结合了深度学习(用于从高维数据中学习抽象特征)与强化学习(通过与环境互动来优化决策策略)。在Dota 2这样的游戏中,AI必须处理大量不确定性和复杂的决策树,这在传统的人工智能方法中是非常困难的。
研究中提到的关键点包括:
1. **长时间跨度**:与许多其他游戏相比,Dota 2的比赛时间较长,要求AI具备长期规划和决策能力。这需要一个能够处理长期依赖和延迟奖励的强化学习算法。
2. **不完全信息**:游戏环境中的部分信息是不可见的,AI需要通过推理和观察来推断对手的策略。这需要引入基于概率的模型,如蒙特卡洛树搜索(MCTS)或者部分可观测马尔科夫决策过程(POMDPs)。
3. **复杂连续状态-动作空间**:Dota 2的动作空间巨大且连续,每个英雄有多种可能的动作,AI必须学会在这些动作间做出选择。这需要使用能处理连续动作空间的算法,如策略梯度方法。
4. **大规模并行训练**:OpenAI设计了一个分布式训练系统,能够同时处理大量数据和训练任务,显著加速了学习过程。
5. **持续训练**:OpenAI Five能够持续学习和适应,这可能涉及到在线学习、迁移学习或元学习等技术,以使AI能够从以往的经验中不断改进。
通过这些技术的综合应用,OpenAI Five不仅在单个游戏实例上表现出色,而且在长时间的训练后能够适应和对抗不同风格的玩家,展现了深度强化学习在解决复杂、动态问题上的潜力。这一研究对人工智能在游戏、机器人、自动驾驶等领域的应用具有深远的影响。
0 200 400 600 800
0
50
100
150
200
250
TrueSkill
Final OpenAI Five TrueSkill = 254
Rerun
OpenAI Five
0 200 400 600 800
Total project compute (PFLOPs/s-days)
0
50
100
150
200
250
TrueSkill
15x more
hypothetical always-restart run
time spent retraining from scratch
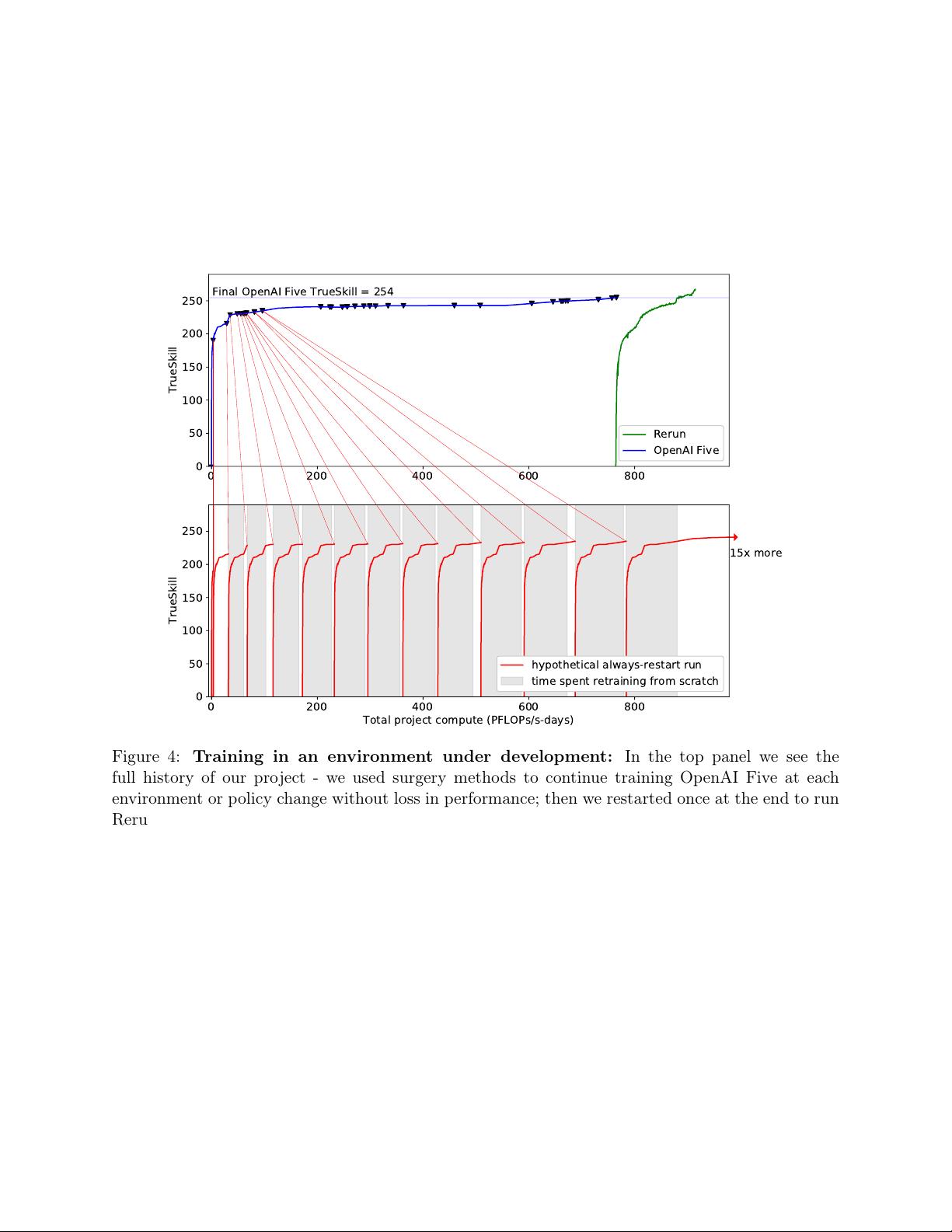
Figure 4: Training in an environment under development: In the top panel we see the
full history of our project - we used surgery methods to continue training OpenAI Five at each
environment or policy change without loss in performance; then we restarted once at the end to run
Rerun. On the bottom we see the hypothetical alternative, if we had restarted after each change
and waited for the model to reach the same level of skill (assuming pessimistically that the curve
would be identical to OpenAI Five). The ideal option would be to run Rerun-like training from the
very start, but this is impossible — the OpenAI Five curve represents lessons learned that led to
the final codebase, environment, etc., without which it would not be possible to train Rerun.
11

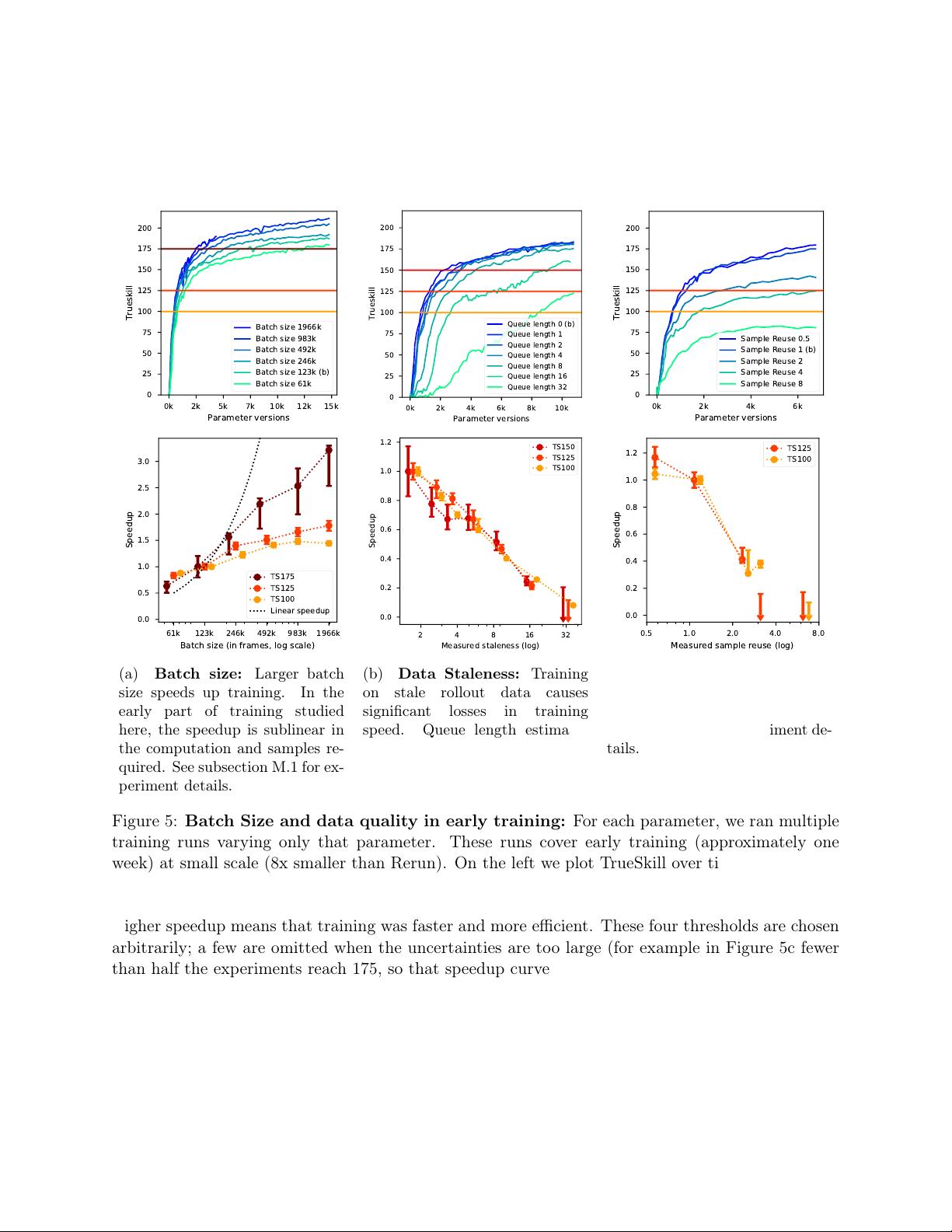

剩余65页未读,继续阅读
332 浏览量
点击了解资源详情
129 浏览量
205 浏览量
234 浏览量
386 浏览量
251 浏览量
152 浏览量

星桥翊月
- 粉丝: 1
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 16道嵌入式C语言面试题
- java第一章java概述教学课件
- 連連看-戊-核心算法
- 全国计算机技术与软件专业技术资格(水平)考试2008年下半年 系统分析师 下午试卷II
- 全国计算机技术与软件专业技术资格(水平)考试2008年下半年 系统分析师 下午试卷
- 全国计算机技术与软件专业技术资格(水平)考试2008年下半年系统分析师上午试卷
- 易学C++电子书1-17
- 2008微软认证-.NET+Framework2.0程序设计70-536英文版264道题目
- FANUC 0i系统的原理框图和维修方法.
- OpenSolaris 2008.05 安装全解
- OpenSolaris 2008.05
- 2008年4月全国计算机等考软件测试工程师试题(部分答案)
- JAVA程序笔记JAVA程序笔记JAVA程序笔记
- 基于RFID 技术的室内机器人定位方法的研究
- 计算机组成原理试卷2004年卷
- java面试葵花宝典
