自建网络爬虫教程:实战案例与关键技术
需积分: 11 43 浏览量
更新于2024-07-29
收藏 2.49MB PDF 举报
"本文档深入探讨了网络爬虫技术,并通过实例讲解如何自己动手编写网络爬虫。首先,作者揭示了网络爬虫在搜索引擎领域的应用,如百度和Google如何实时抓取大量网页,指出自己编写爬虫的重要性,尤其是在企业中,数据抓取可以帮助构建数据仓库,支持多维度数据分析和数据挖掘,甚至个人用户也会利用爬虫获取特定信息,如股票数据。
第1章全面剖析网络爬虫,从基础的抓取网页开始,强调了理解URL的核心作用。URL,全称为统一资源定位符,是浏览器与服务器之间通信的关键,它包含了访问资源的方式(协议)、服务器地址和资源路径。当我们输入网址,实际上是向服务器发送请求,服务器响应后,浏览器会接收并解析返回的网页内容。
1.1.1节中,详细解释了抓取网页的过程,涉及到浏览器作为客户端发送HTTP请求,服务器响应HTTP状态码,以及如何查看和分析源代码。HTTP状态码是服务器对请求状态的反馈,常见的状态码有200(成功)和404(未找到),理解和处理这些状态码对于爬虫的稳定性和效率至关重要。
作者随后给出了使用Java语言抓取网页的实例,帮助读者从实践中学习。这部分内容可能包括如何使用诸如`java.net.URL`类来构造和发送HTTP请求,如何解析HTTP响应,以及如何处理可能出现的异常情况。通过这些步骤,读者可以建立起自己编写网络爬虫的基础能力,能够灵活地抓取网络上的各种信息。
本篇文章不仅介绍了网络爬虫的基本原理,还提供了实际操作技巧,适合希望学习网络爬虫的读者,无论是对企业数据采集还是个人兴趣,都将有所帮助。"
12
1
的遍历的方式对互联网这个超级大 “ 图 ” 进行访问。图的遍历通常可分为宽度优先遍历和
深度优先遍历两种方式。但是深度优先遍历可能会在深度上过 “ 深 ” 地遍历或者陷入 “ 黑
洞 ” ,大多数爬虫都不采用这种方式。另一方面,在爬取的时候,有时候也不能完全按照
宽度优先遍历的方式 , 而是给待遍历的网页赋予一定的优先级 , 根据这个优先级进行遍历
,
这种方法称为带偏好的遍历。本小节会分别介绍宽度优先遍历和带偏好的遍历。
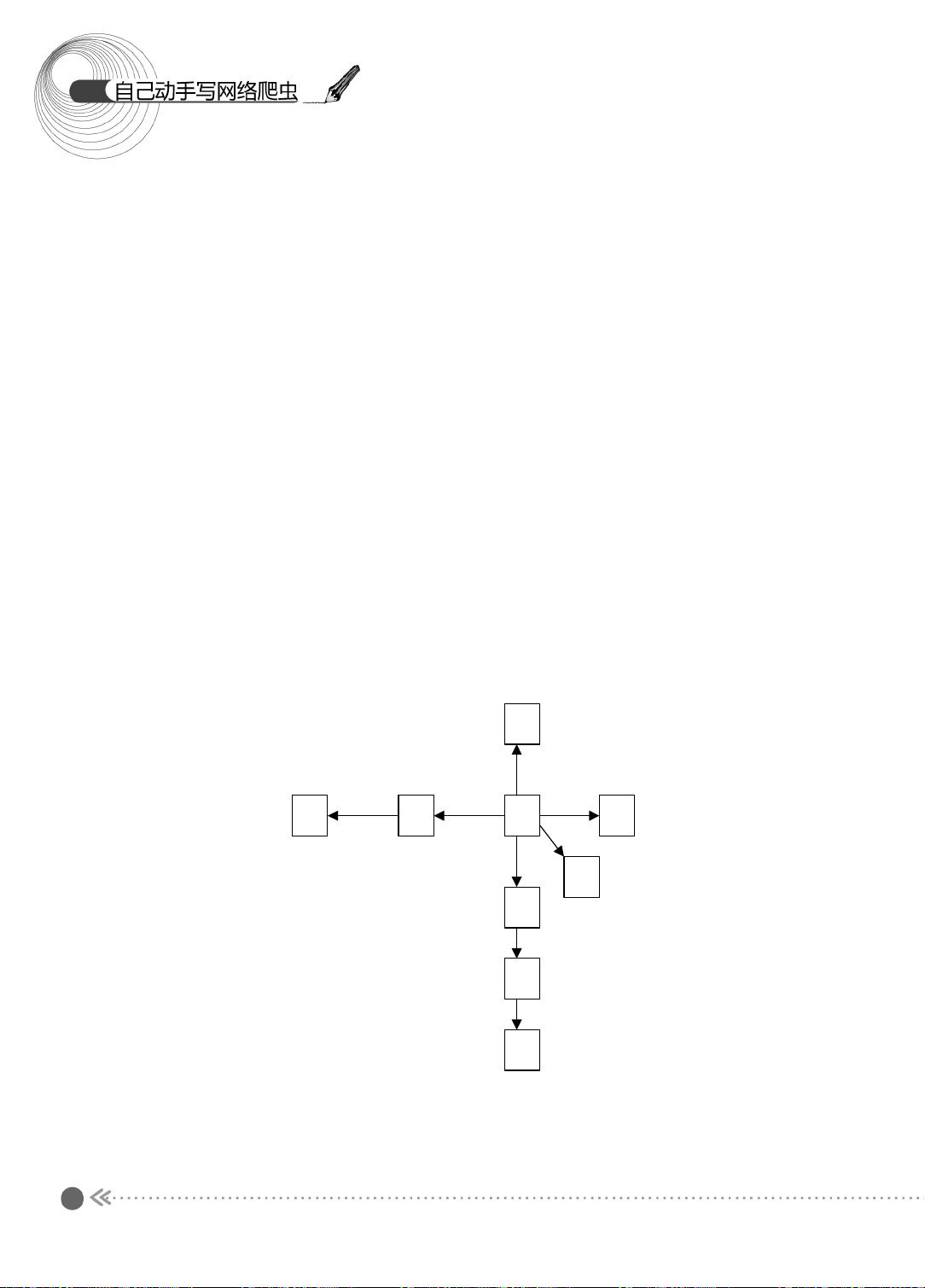
1.2.1 图的宽度优先遍历
下面先来看看图的宽度优先遍历过程 。 图的宽度优先遍历 (BFS) 算法是一个分层搜索的
过程,和树的层序遍历算法相同。在图中选中一个节点,作为起始节点,然后按照层次遍
历的方式,一层一层地进行访问。
图的宽度优先遍历需要一个队列作为保存当前节点的子节点的数据结构。具体的算法
如下所示:
(1) 顶点 V 入队列。
(2) 当队列非空时继续执行,否则算法为空。
(3) 出队列,获得队头节点 V ,访问顶点 V 并标记 V 已经被访问。
(4) 查找顶点 V 的第一个邻接顶点 col 。
(5) 若 V 的邻接顶点 col 未被访问过,则 col 进队列。
(6) 继续查找 V 的其他邻接顶点 col ,转到步骤 (5) ,若 V 的所有邻接顶点都已经被访
问过,则转到步骤 (2) 。
下面,我们以图示的方式介绍宽度优先遍历的过程,如图 1.3 所示。
G
B
A
C
D
F
E
I
H
图 1.3 宽度优先遍历过程

剩余67页未读,继续阅读
2015-11-05 上传
2016-12-13 上传
499 浏览量
2024-11-16 上传
2024-11-16 上传
2024-11-16 上传
2024-11-16 上传

驰驰的老爸
- 粉丝: 297
- 资源: 47
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
