深度学习Q-learning算法解析:价值函数与强化学习策略
"Q-learning是深度学习算法中的价值基础方法,用于训练一个批评网络(critic),而不是直接训练策略(policy)。批评网络评估演员(actor)的策略,并预测从当前状态开始直至游戏结束,遵循该策略所能获得的奖励总和。这种价值函数的输入是游戏状态,输出是一个标量值,表示预期的累积奖励。Q-learning可以通过两种方法计算:蒙特卡洛(MC)方法和时间差分(TD)方法。MC方法需要游戏完整结束来获取累积奖励,而TD方法则只需部分路径就能更新估计,具有更低的方差但可能不完全准确。"
Q-learning是一种强化学习算法,它属于无模型的决策过程,其中智能体与环境进行交互,尝试最大化长期累积奖励。在这个框架下,critic的作用是估算Q值,即在特定状态下执行某个动作后,未来可能获得的奖励总和。Q值函数是Q-learning的核心,它指导智能体选择最优动作。
价值函数(Value Function)是Q-learning的基础,它提供了一个度量标准,用于衡量在给定状态下,按照特定策略行动的长期效益。在实际应用中,价值函数通常通过神经网络来近似,以提高泛化能力。
Q-learning的两种计算方法:
1. 蒙特卡洛方法(Monte Carlo Approach):当一个episode(游戏的一轮)结束后,根据实际获得的累积奖励来更新Q值。这种方法的优点是最终的Q值估计准确,但缺点是需要完整的游戏轨迹,效率较低。
2. 时间差分方法(Temporal-Difference Approach):Q-learning通常采用TD学习,它可以在每个时间步利用当前的估计和下一个时间步的估计进行更新,无需等待完整episode。这种方法更高效,但可能会引入一些误差,因为它依赖于当前的Q值估计。
在TD方法中,Q-learning的更新规则基于TD误差(Temporal-Difference Error),即预测的Q值与实际获得的奖励加上下一个状态的Q值之和之间的差距。通过不断地迭代和更新,Q值逐渐收敛,从而找到最优策略。
MC与TD方法的比较:
MC方法的方差较大,因为它依赖于整个episode的随机结果,导致不同episode的累积奖励差异显著。而TD方法仅依赖于当前和下一状态,其方差较小,更新更频繁,但可能由于局部最优解而偏离全局最优。
Q-learning通过不断试错和学习,能够找到一个接近最优的策略,即使在未知环境中也能自我优化。这种方法在游戏控制、机器人导航、资源管理等领域有广泛的应用。
深度学习算法深度学习算法 Q-learning 原理原理
Q-learning
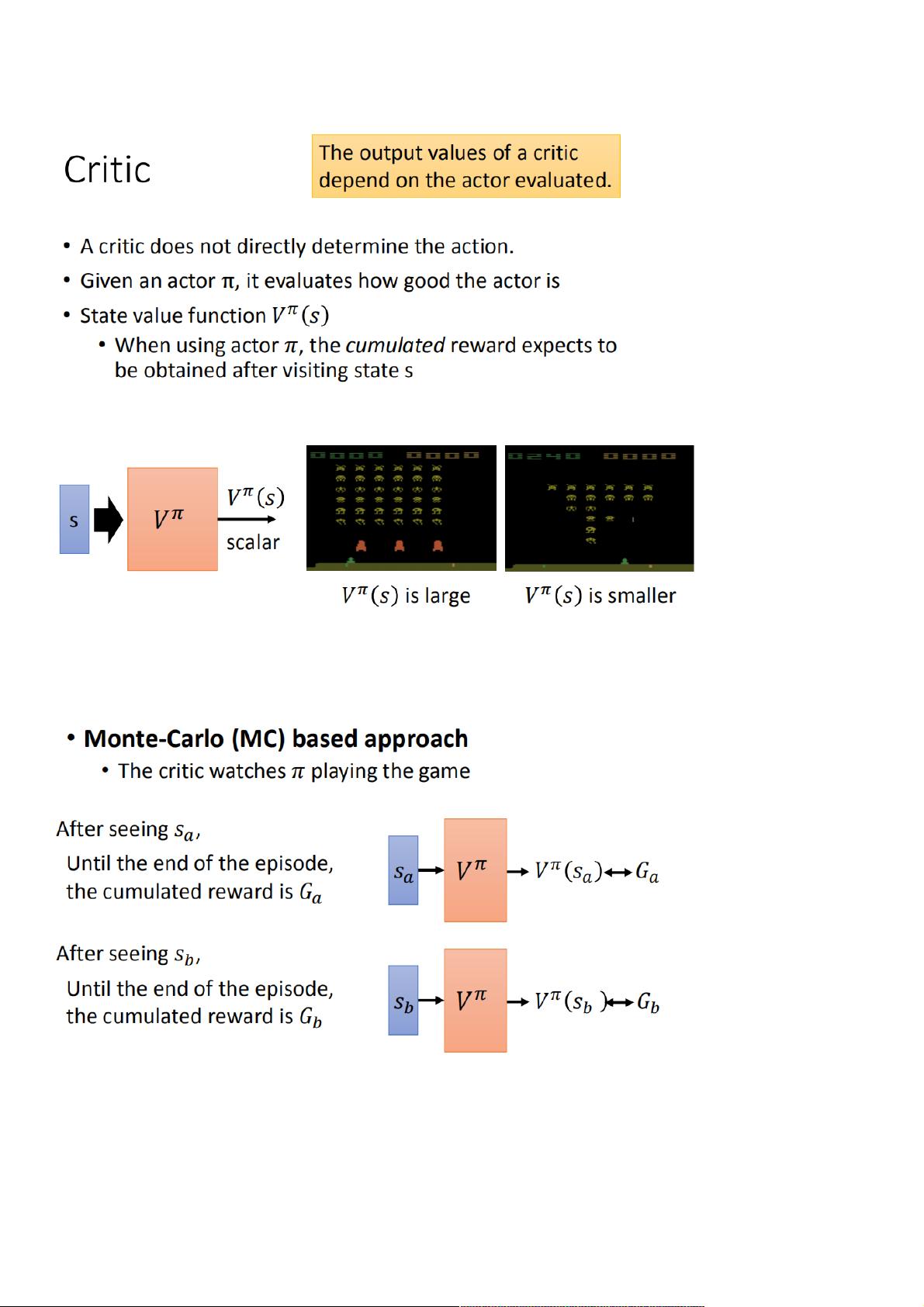
Q-learning 是 value-based 的方法,在这种方法中我们不是要训练一个 policy,而是要训练一个critic网络。critic 并不直接采取行为,只是对现有的 actor ,评价它的好坏。
Value-Fuction
critic 给出了一个 value function ,代表在遇到游戏的某个 state 后,采取策略为的actor 一直玩到游戏结束,所能得到的 reward 之和。
(即critic)的输入是某个state,输出是一个scalar标量。上图游戏画面中左边的 很大,因为当前怪物比较多,防护罩也没被摧毁,从此时玩到游戏结束得到的 reward 就会比
较多;而相对的右边的 就比较小。综上 critic 的输出取决于两点:
state,这个就是左右图对比,刚才说过了
actor 的策略 ,如果是个很弱的actor即便左图可能也得到很低的reward。
怎么计算呢?
计算的2种方式:
1、Monte-Carlo (MC) based approach :
将作为的输入最终输出 ,而实际上应该得到的cumulative reward是。这其实和 regression problem 很相似,因为我们的目标就是通过训练让 越来越接近 ,即理想情况下(这
里为了方便,假设学习率为1,原始的公式为)。
注意:是一个网络,因为在游戏中,不可能所有的image都看过,所以将做成网络来提高泛化性。
2、Temporal-difference (TD) approach
下载后可阅读完整内容,剩余6页未读,立即下载
2018-04-26 上传
2021-10-10 上传
2021-09-30 上传
2022-07-13 上传
2021-09-11 上传
2021-09-29 上传
2022-04-13 上传

weixin_38556394
- 粉丝: 7
- 资源: 896
 我的内容管理
展开
我的内容管理
展开







