基于Sphinx的汉语连续数字语音识别系统研究
需积分: 0 161 浏览量
更新于2024-09-08
收藏 288KB PDF 举报
"这篇论文研究了使用Sphinx进行汉语连续数字语音识别的方法。作者王韵和张雪英来自太原理工大学信息工程学院,他们构建了一个基于Sphinx的系统,该系统利用SphinxTrain训练声学模型,cmuclmtk生成语言模型,并采用PocketSphinx作为识别引擎。实验结果显示,该系统在非特定人不定长数字串识别中的准确率为89.583%,词识别率为97.20%。"
文章详细介绍了构建汉语连续数字语音识别系统的过程。首先,Sphinx是一个广泛使用的开源语音识别框架,而SphinxTrain是用于训练声学模型的工具,它可以处理汉语的声学特性,将声音转换为可识别的模式。声学模型是语音识别系统的关键组成部分,它将音频信号转化为概率模型,以便与词汇表中的发音对应。
其次,cmuclmtk是一个统计语言模型生成工具,用于构建语言模型。语言模型则处理语音识别中的语言上下文问题,帮助系统理解连续数字串的语义结构,提高识别准确性。在汉语环境中,由于数字之间的混淆性和单音节的特点,语言模型尤为重要。
接着,文章提到使用了PocketSphinx作为识别引擎。PocketSphinx是CMU开发的轻量级、适用于嵌入式设备的语音识别引擎,特别适合小词汇量的连续语音识别,例如数字识别。尽管它最初设计用于英语,但经过调整后,也可以适应汉语数字的识别。
系统结构部分,文章指出连续语音识别系统包括四个主要部分:特征提取、声学模型、语言模型和识别引擎。特征提取是通过SphinxBase库实现的,该库使用MFCC(梅尔频率倒谱系数)技术对原始音频数据进行预处理,提取出有助于识别的特征。MFCC流程包括预加重、分帧、窗函数、傅里叶变换、梅尔滤波器组、对数运算以及离散余弦变换等步骤。
这篇论文展示了一个基于Sphinx的汉语连续数字语音识别系统的构建过程和其实效性,为汉语语音识别技术的发展提供了有价值的参考。通过优化声学模型和语言模型,以及利用开源工具,系统实现了高识别率,显示了在各种应用场景中的潜力。
http://www.paper.edu.cn
- 1 -
中国科技论文在线
Sphinx 用于汉语连续数字语音识别的研究
王韵,张雪英
太原理工大学信息工程学院,太原(030024)
E-mail:312118847@163.com
摘 要:本文介绍了一个基于 Sphinx 的汉语连续数字语音识别系统,其声学模型采用
SphinxTrain 训练生成,语言模型由 cmuclmtk 统计语言模型生成,识别引擎采用 PocketSphinx
工具。实验证明该系统对于非特定人不定长数字串的句子识别率为 89.583%,词识别率为
97.20%,说明该系统有良好的性能。
关键词:Sphinx;语音识别;声学模型;语言模型
中图分类号:TN912.34
1.引 言
作为汉语语音识别的一个重要分支,非特定人连续数字识别有着广阔的应用前景。它在
语音电话拨号、数字家电遥控、移动通信、电话证券交易等众多实用化领域
[1]
都给人们带来
极大的便利。连续数字识别是一个小词汇量的语音识别系统,识别对象仅包括 0~9 十个数
字,但由于汉语的单音节及易混淆性使得识别率同实际应用还存在一定差距。
本文利用卡内基梅陇大学(CMU)开发的嵌入式识语音识别引擎 PocketSphinx,声学
模型训练工具 SphinxTrain,语言模型生成工具 cmuclmtk
[2]
构建了一个汉语数字识别系统。
PocketSphinx 是 CMU 开发的一款用于快速语音识别的嵌入式语音识别引擎,它对于小词汇
量的英语连续语音有很高的识别率。这里我们借助此识别引擎,通过训练汉语数字的声学模
型和语言模型来构建一个高性能的汉语连续数字语音识别系统。这些工具的源代码都是公开
的,通过改进算法,在汉语连续数字识别方面取得了一定的成效。
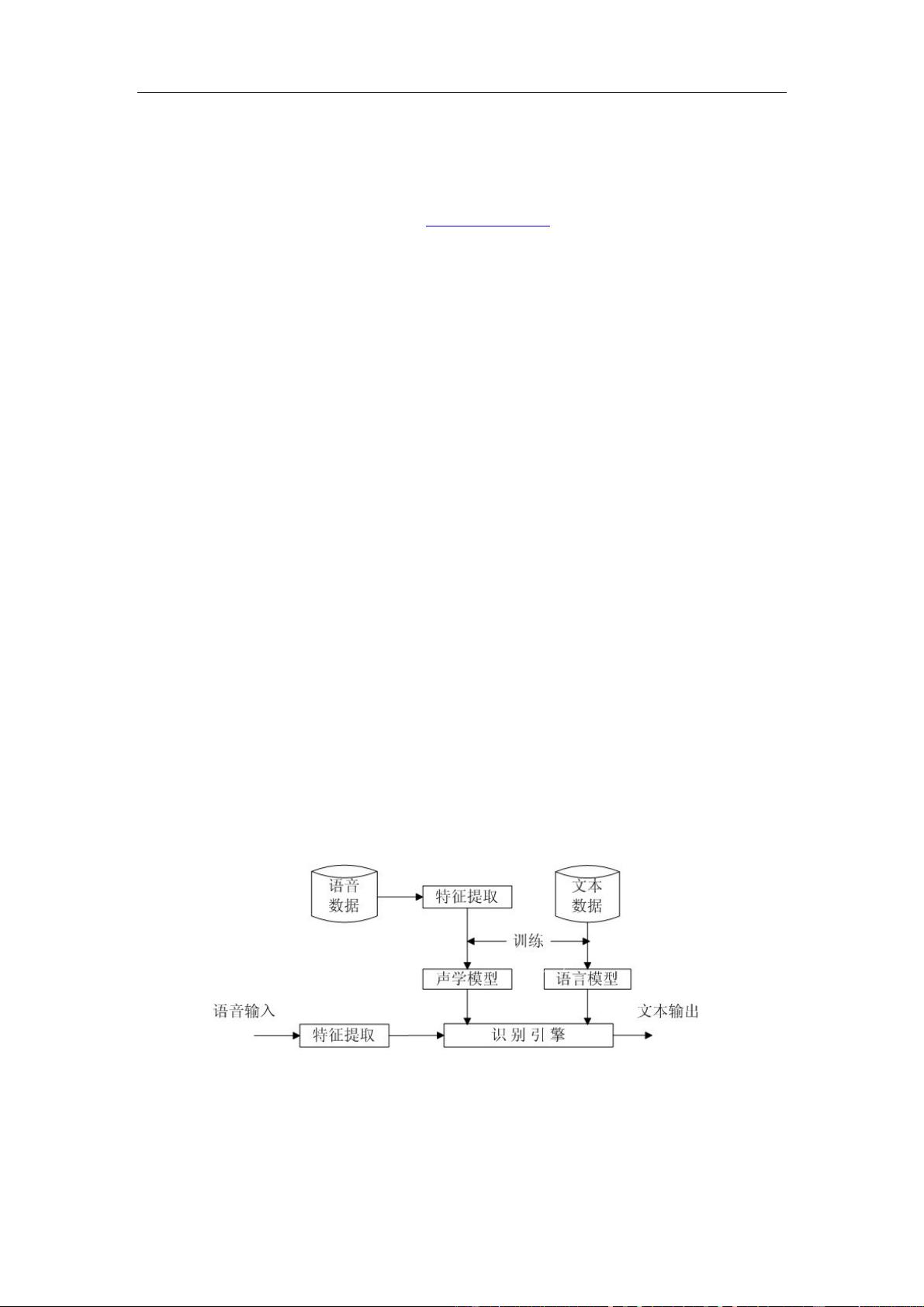
2.系统结构
连续语音识别系统主要由特征提取,声学模型,语言模型,识别引擎四部分组成如图 1。
以下会根据本文构建的数字连续语音系统对这四部分分别介绍。
图 1 连续语音识别系统的基本结构
2.1 特征提取
SphinxBase 是卡内基梅隆大学著名的 Sphinx 语音识别工程的公用库,主要用 MFCC 实
现了语音识别系统的前端特征提取,其流程如图 2 示:
下载后可阅读完整内容,剩余4页未读,立即下载
345 浏览量
664 浏览量
149 浏览量
678 浏览量

weixin_39840588
- 粉丝: 451
 我的内容管理
展开
我的内容管理
展开







最新资源
- Web远程教学系统需求分析指南
- 禅道6.2版本发布,优化测试流程,提高安全性
- Netty传输层API中文文档及资源包免费下载
- 超凡搜索:引领搜索领域的创新神器
- JavaWeb租房系统实现与代码参考指南
- 老冀文章编辑工具v1.8:文章编辑的自动化解决方案
- MovieLens 1m数据集深度解析:数据库设计与电影属性
- TypeScript实现tca-flip-coins模拟硬币翻转算法
- Directshow实现多路视频采集与传输技术
- 百度editor实现无限制附件上传功能
- C语言二级上机模拟题与VC6.0完整版
- A*算法解决八数码问题:AI领域的经典案例
- Android版SeetaFace JNI程序实现人脸检测与对齐
- 热交换器效率提升技术手册
- WinCE平台CPU占用率精确测试工具介绍
- JavaScript实现的压缩包子算法解读
