无监督学习:聚类算法原理与应用
"该资源为一个关于聚类算法的PPT,主要介绍了聚类的基本概念、目的、与分类的区别,以及聚类中的相似度计算和有效性函数等关键要素。"
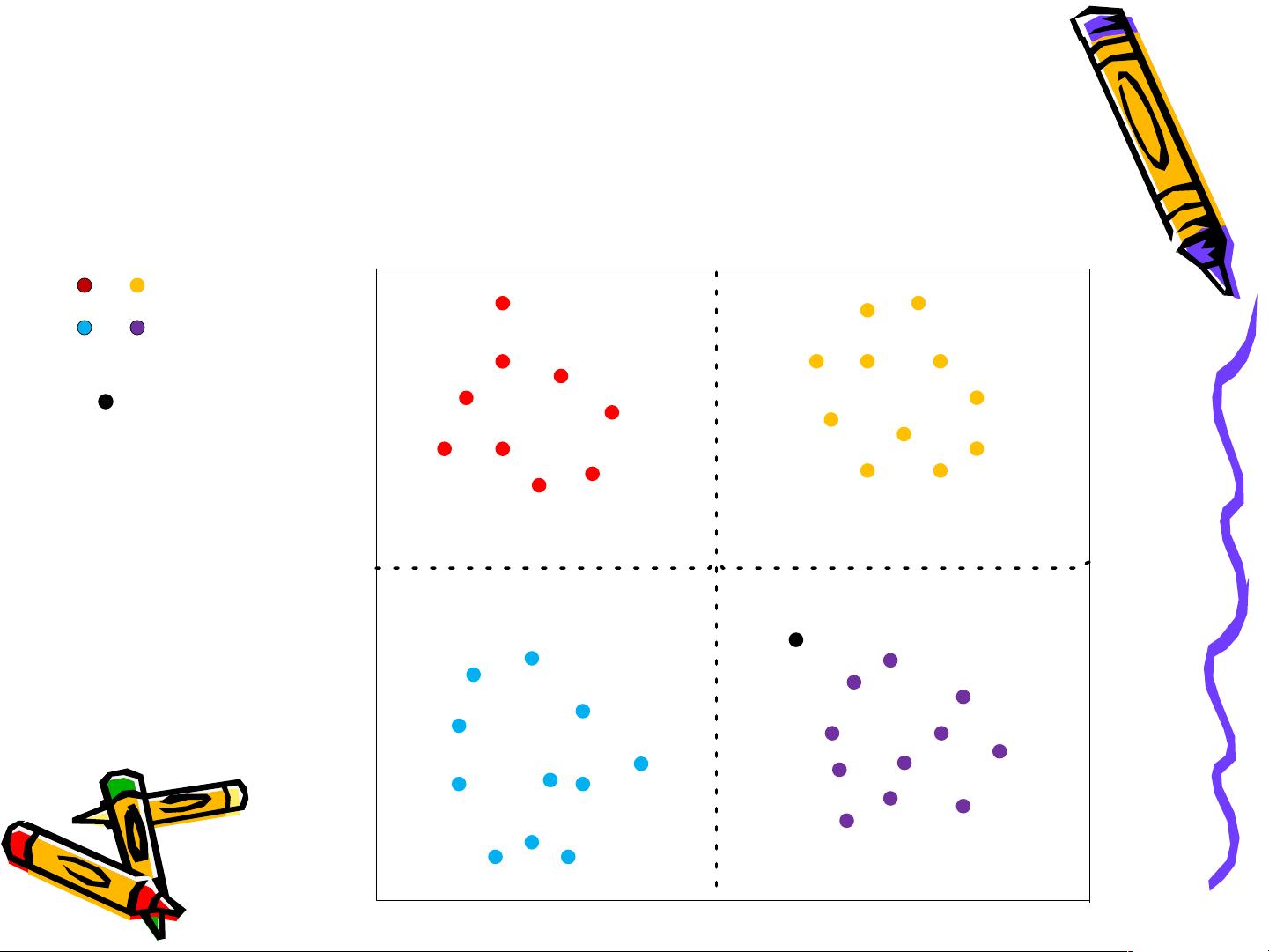
聚类算法是一种无监督学习方法,它通过对大量未标记数据进行分析,依据数据的内在相似性将其分组成多个类别。在类别内部,数据点之间具有较高的相似度,而类别之间则保持较低的相似度。这种划分可以帮助我们揭示数据的自然结构,发现潜在的模式,并在没有先验知识的情况下进行数据组织。
聚类在许多领域有着广泛的应用,例如在信息检索中,通过聚类相似的文档或超链接,可以显著减少用户查找相关信息的时间。聚类算法的工作过程通常是自下而上的,从单个数据点开始,逐渐合并相似的数据,形成更大的簇。
与聚类相比,分类是一种有监督的学习方法。分类需要预先存在的类别标记数据,即训练数据,目的是学习到一个模型,该模型可以根据新的未标记数据的特征将其分配到正确的类别。在分类过程中,模型会基于训练数据调整参数,以最小化预测错误。
聚类算法的关键要素包括:
1. **相似度度量**:这是聚类的基础,常见的相似度度量有欧氏距离,它衡量的是两个数据点在多维空间中的直线距离。相似度计算通常基于数据的特征或属性。
2. **聚类有效性函数(停止判别条件)**:用于评估聚类结果的质量,如最小误差准则和最小方差准则。聚类算法会迭代执行,直到满足某个预设的有效性函数,表明聚类达到了预期的划分效果。
3. **类别划分策略(算法)**:例如K-means算法、层次聚类等,它们决定了如何根据相似度将数据点分配到不同的簇。
聚类与分类的主要区别在于,聚类是无监督的,没有预先设定的类别标签;而分类是有监督的,依赖于已知的类别标签进行学习。此外,聚类通常不需要训练数据,而分类需要训练数据来构建分类模型。
聚类算法在实际应用中,如市场细分、生物信息学、图像分割、社交网络分析等领域都有着重要作用。理解并正确选择合适的聚类方法对于挖掘数据价值至关重要。
分类图示
1
2
3
4
训练数据
待分类数据
剩余28页未读,继续阅读
相关推荐





橙色幸福
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握PerfView:高效配置.NET程序性能数据
- SQL2000与Delphi结合的超市管理系统设计
- 冲压模具设计的高效拉伸计算器软件介绍
- jQuery文字图片滚动插件:单行多行及按钮控制
- 最新C++参考手册:包含C++11标准新增内容
- 实现Android嵌套倒计时及活动启动教程
- TMS320F2837xD DSP技术手册详解
- 嵌入式系统实验入门:掌握VxWorks及通信程序设计
- Magento支付宝接口使用教程
- GOIT MARKUP HW-06 项目文件综述
- 全面掌握JBossESB组件与配置教程
- 古风水墨风艾灸养生响应式网站模板
- 讯飞SDK中的音频增益调整方法与实践
- 银联加密解密工具集 - Des算法与Bitmap查看器
- 全面解读OA系统源码中的权限管理与人员管理技术
- PHP HTTP扩展1.7.0版本发布,支持PHP5.3环境
