深度学习驱动的低资源语音识别与关键词检测技术
"本文介绍了一种基于深度学习的低资源语音识别和关键词识别方法,重点关注在有限的数据资源条件下实现高效语音处理技术。该方法在Babel项目背景下被探讨,该项目旨在开发灵活且稳健的语音识别技术,能快速应用于任何人类语言,以提供有效的搜索能力,帮助分析师高效处理大量真实世界的录音语音。主要任务是关键词(短语)检测,其中查询条件可以是单个词或短语。"
在语音识别领域,深度学习已经成为主流技术,尤其是对于低资源语音识别,它能够处理有限的训练数据、音频转录、音素词典、语言模型训练数据以及语言处理资源。深度学习模型,如循环神经网络(RNN)、长短时记忆网络(LSTM)和卷积神经网络(CNN),在捕捉语音信号的动态变化和提取特征方面表现优秀。
关键词识别(Keyword Spotting)是语音识别的一个特定任务,其目标是从连续的语音流中检测预定义的关键词或短语。这个任务在安全监控、智能家居、智能助手等应用场景中尤为重要。例如,关键词"OK Google"或"Hey Siri"可以触发语音助手的激活。在示例中,我们看到一个时间轴,表示了不同单词在语音片段中的出现时间,这是进行关键词识别时可能需要分析的数据。
为了在低资源环境下优化语音识别和关键词识别,通常会采用以下策略:
1. 数据增强:通过合成、剪切、混合现有音频来增加训练数据的多样性和数量。
2. 轻量级模型:设计更小、更高效的模型结构,以适应资源受限的设备。
3. 迁移学习:利用预训练的模型在类似任务或大量资源语言上的知识。
4. 半监督或无监督学习:在没有大量标记数据的情况下,利用未标注数据进行学习。
5. 音素建模:对于有限的词汇量,可以直接对音素进行建模,减少对完整词汇表的依赖。
在Babel项目中,研究人员面临的挑战是如何在多种语言和有限资源下构建通用的语音识别系统。他们可能探索了跨语言迁移、多任务学习和联合建模等技术,以提高系统性能并确保其在不同语言环境下的适应性。
本文涉及的语音识别和关键词识别方法是深度学习在语音处理领域的应用,尤其关注在数据稀缺条件下的解决方案,以及关键词检测这一特定任务。通过各种技术手段,研究人员致力于提升系统的泛化能力和实际场景的实用性。
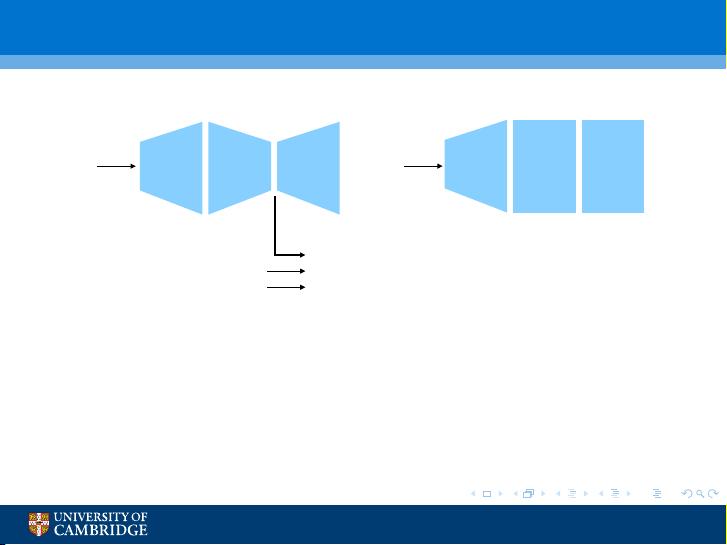
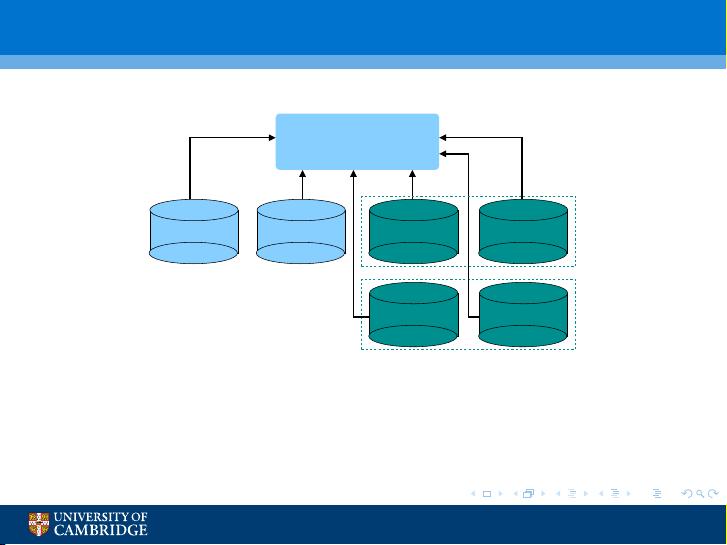
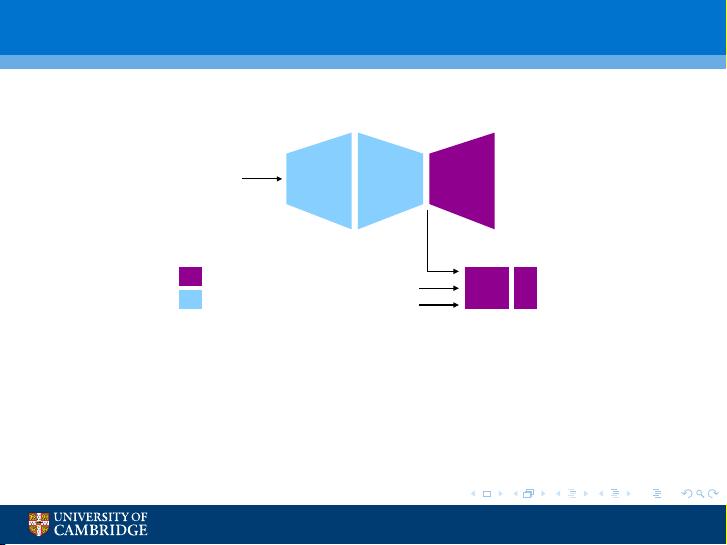
Use of (Deep) Neural Networks
Targets
Context−Dependent
Targets
Hidden Layers
Input Layer
Layer
Bottleneck
Context−Dependent
Bottleneck
PLP
Pitch
Input
Features
Input
Features
Input Layer
Hidden Layers
•
Develop both Tandem and Hybrid system configurations
•
results are complementary (both for ASR and KWS) - see later
•
gains from techniques often apply to both set-ups
•
but systems also have different advantages
•
Mixed gains from RNN/LSTM/CNN configurations
•
challenges to get KWS working well
•
BBN team got some gains in OP3
8/63
剩余67页未读,继续阅读
2023-03-31 上传
2023-06-06 上传
2023-06-10 上传
2023-06-12 上传
2023-04-23 上传
2023-07-24 上传

weixin_44276261
- 粉丝: 1
- 资源: 49
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
