Zookeeper安装与配置指南 - 分布式协调服务
需积分: 0 200 浏览量
更新于2024-08-03
收藏 1.2MB DOCX 举报
"这篇文档介绍了如何在虚拟机环境中安装和配置Zookeeper,Zookeeper是一个分布式协调服务,常用于大数据环境中的配置管理、域名服务、分布式同步等任务。它需要在全分布式环境搭建完成后进行安装。"
在大数据领域,Zookeeper扮演着至关重要的角色,它是一个开源的分布式协调服务,由Apache Hadoop项目开发。Zookeeper的主要任务是为分布式应用提供一致性服务,其中包括配置管理、集群管理、命名服务、分布式同步和组服务等多种功能。这些服务对于构建可靠的分布式系统至关重要,因为它们确保了系统组件之间的协调和通信。
在Zookeeper的安装过程中,首先需要访问Apache官方网站下载最新稳定版,例如这里的3.5.8版本。下载后,通过tar命令进行解压,并重命名文件夹以方便管理。接下来的步骤是在解压后的Zookeeper目录下创建"data"文件夹,这个文件夹将用于存储Zookeeper运行时的数据,如节点ID。
接着,创建一个名为"myid"的文件在"data"目录下,该文件的内容代表当前Zookeeper服务器的ID,对于多节点集群来说,每个节点的ID必须是唯一的。在这里,我们输入数字"1"表示这是集群中的第一个节点。
然后,我们需要编辑Zookeeper的配置文件"zoo.cfg",这个文件位于"conf"目录下。配置文件中的"tickTime"定义了一个时间单位,通常设置为2000毫秒;"initLimit"和"syncLimit"分别限制了Zookeeper初始化连接和同步数据的时间;"dataDir"指定了Zookeeper的数据目录,即之前创建的"data"文件夹的路径。
在集群环境中,Zookeeper需要多台机器协同工作,因此还需要配置其他节点的信息,如"server."配置项,来指定集群中的其他服务器。在实际生产环境中,这一步骤会涉及到多个节点的IP地址和端口设置。
一旦配置完成,可以通过启动脚本来启动Zookeeper服务。在大数据生态系统中,Zookeeper常与Hadoop、HBase、Kafka等组件配合使用,确保这些分布式系统的高可用性和一致性。
Zookeeper是大数据基础设施的关键组件,它的正确配置和运行对于整个分布式系统的稳定性至关重要。了解并掌握Zookeeper的基本概念和操作,对于从事大数据相关工作的人员来说,是必备的技能之一。
1.5 (master)配置 Zookeeper 内部环境
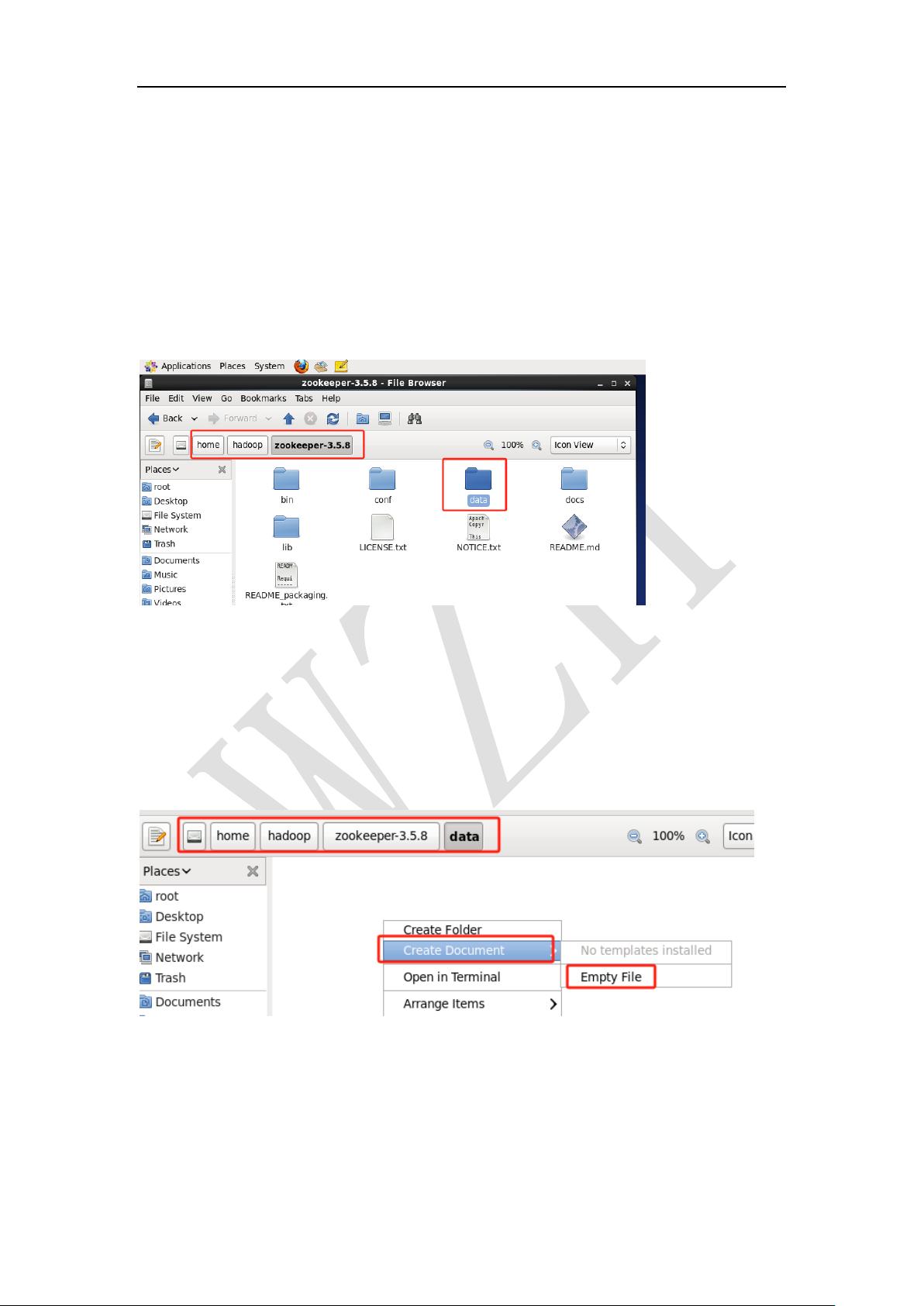
1.5.1 添加 data 文件夹
打开/home/hadoop/zookeeper-3.5.8,在空白处右键->create folder(新建文件
夹)->文件夹命名为“data”
1.5.2 添加 myid 文件
步骤 1 打开/home/hadoop/zookeeper-3.5.8/data 目录
步骤 2 空白处鼠标右键->Create Document->empty file。
步骤 3 将新文件命名为“myid”
步骤 4 使用 gedit 打开 myid,输入:1,然后保存
剩余11页未读,继续阅读
2021-08-21 上传
2020-04-16 上传
2023-12-20 上传
2022-10-22 上传
2020-10-18 上传
2023-03-03 上传
2019-03-08 上传
2018-11-11 上传
2021-10-14 上传

wangz_h
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- WordPress作为新闻管理面板的实现指南
- NPC_Generator:使用Ruby打造的游戏角色生成器
- MATLAB实现变邻域搜索算法源码解析
- 探索C++并行编程:使用INTEL TBB的项目实践
- 玫枫跟打器:网页版五笔打字工具,提升macOS打字效率
- 萨尔塔·阿萨尔·希塔斯:SATINDER项目解析
- 掌握变邻域搜索算法:MATLAB代码实践
- saaraansh: 简化法律文档,打破语言障碍的智能应用
- 探索牛角交友盲盒系统:PHP开源交友平台的新选择
- 探索Nullfactory-SSRSExtensions: 强化SQL Server报告服务
- Lotide:一套JavaScript实用工具库的深度解析
- 利用Aurelia 2脚手架搭建新项目的快速指南
- 变邻域搜索算法Matlab实现教程
- 实战指南:构建高效ES+Redis+MySQL架构解决方案
- GitHub Pages入门模板快速启动指南
- NeonClock遗产版:包名更迭与应用更新
