优化缓存与批量查询:策略与布隆过滤器应用
需积分: 0 57 浏览量
更新于2024-08-05
收藏 754KB PDF 举报
在IT行业中,缓存问题和批量查询优化是至关重要的性能优化策略。本篇文章主要关注两个核心问题的解决方案:缓存空数据和BloomFilter(布隆过滤器)的应用。
首先,面对缓存穿透问题,即恶意用户请求不存在的数据导致数据库压力过大,解决方案包括:
1.1 缓存空数据处理
- 设置短生命周期的过期时间:对空值的缓存设置较短的过期时间,自动剔除,避免占用过多内存。这样在数据真正添加到数据库前,缓存已自动清除。
- 数据一致性管理:通过消息队列或其他机制,当存储层数据更新后,及时清理缓存中的空对象,确保缓存与数据库同步。
其次,布隆过滤器作为一种高效的数据结构,用于减少空间消耗,检测元素是否存在。它的核心原理是:
- 使用位数组作为基础数据结构,每个元素映射到固定长度的哈希值,存储0或1表示是否存在。
- 哈希函数确保输入任意长度的数据能生成固定长度的输出,且分布均匀,如MD5或SHA-1等。
- 当要存储元素时,通过多个哈希函数计算结果并更新位数组。查询时同样应用相同的哈希函数,检查对应位置是否为1来判断元素可能存在的概率。
- 布隆过滤器虽然不能100%确定元素是否存在,但误报率较低,适用于大规模数据的去重和查询加速,适合于那些允许一定误报率的场景。
通过上述解决方案,可以有效缓解缓存问题,提高系统性能,并在面对海量数据时提供高效的查询手段。数据库如Redis通过缓存和布隆过滤器技术,实现了高效的数据管理和查询优化,是现代IT架构中的关键组件之一。理解并熟练运用这些策略,有助于提升系统的稳定性和响应速度。
1、缓存问题解决方案
1.1 缓存穿透
缓存没有,数据库也没有,业务系统访问压根就不存在的数据,导致每次访问都将压力挂到了数据库服
务器上导致服务崩溃,一般来说都是恶意访问导致
解决方案:
1、缓存空数据
第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间 ( 如果是攻击,问题更严重
),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设
置为 5 分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此
时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
2、BloomFilter(布隆过滤器):在缓存之前再加一道屏障,里面存储目前redis数据库中存在的所有
key
在讲布隆过滤器之前我们思考下:
有些同学可能会在想,我使用集合行不行呢:比如在海量元素中(例如 10 亿无序、不定长、不重复)
快速 判断一个元素是否存在?好,我们最简单的想法就是把这么多数据放到数据结构里去,比如List、
Map、Tree,一搜不就出来了吗,比如map.get(),我们假设一个元素1个字节的字段,10亿的数据大概
需要 900G 的内存空间,这个对于普通的服务器来说是承受不了的,当然面试官也不希望听到你这个答
案,因为太笨了吧,我们肯定是要用一种好的方法,巧妙的方法来解决,这里引入一种节省空间的数据
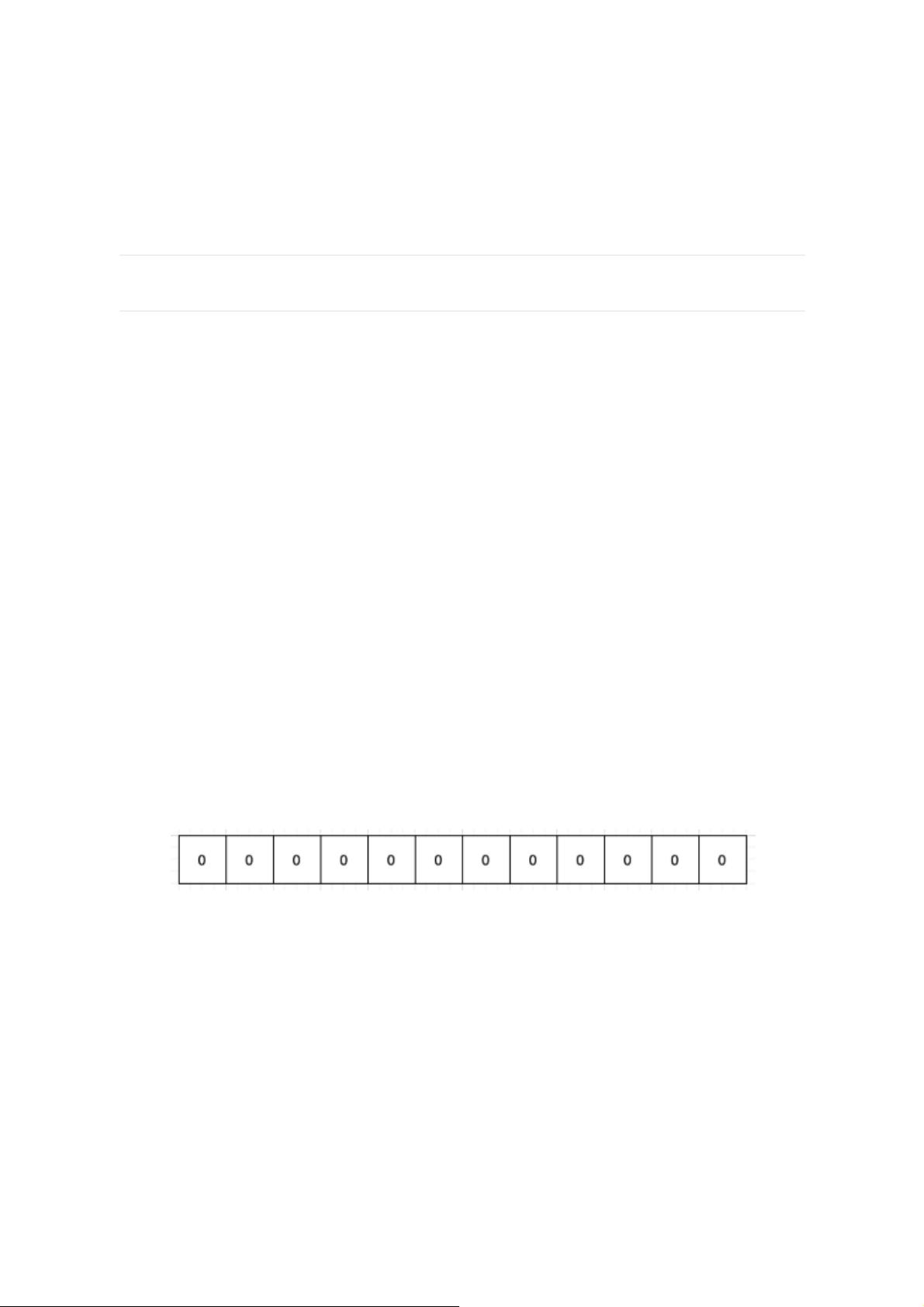
结构 --- 位数组 ,它是一个有序的数组,只有两个值,0 和 1。0代表不存在,1代表存在。
有了这个厉害的东西,现在我们还需要一个映射关系,你总得知道某个元素在哪个位置上吧,然后在去
看这个位置上是0还是1,怎么解决这个问题呢,那就要用到哈希函数,用哈希函数有两个好处,第一是
哈希函数无论输入值的长度是多少,得到的输出值长度是固定的,第二是他的分布是均匀的,如果全挤
的一块去那还怎么区分,比如MD5、SHA-1这些就是常见的哈希算法。
下载后可阅读完整内容,剩余8页未读,立即下载
2022-04-11 上传
2011-05-21 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

maXZero
- 粉丝: 31
- 资源: 303
 我的内容管理
展开
我的内容管理
展开







最新资源
- CoreOS部署神器:configdrive_creator脚本详解
- 探索CCR-Studio.github.io: JavaScript的前沿实践平台
- RapidMatter:Web企业架构设计即服务应用平台
- 电影数据整合:ETL过程与数据库加载实现
- R语言文本分析工作坊资源库详细介绍
- QML小程序实现风车旋转动画教程
- Magento小部件字段验证扩展功能实现
- Flutter入门项目:my_stock应用程序开发指南
- React项目引导:快速构建、测试与部署
- 利用物联网智能技术提升设备安全
- 软件工程师校招笔试题-编程面试大学完整学习计划
- Node.js跨平台JavaScript运行时环境介绍
- 使用护照js和Google Outh的身份验证器教程
- PHP基础教程:掌握PHP编程语言
- Wheel:Vim/Neovim高效缓冲区管理与导航插件
- 在英特尔NUC5i5RYK上安装并优化Kodi运行环境
