Transformer中的归一化再探索:批量归一化与层归一化的对比
需积分: 16 76 浏览量
更新于2024-07-16
收藏 672KB PDF 举报
"这篇论文《再思考Transformer中的Batch Normalization》深入探讨了自然语言处理(NLP)领域中,为何通常使用层归一化(Layer Normalization, LN)而非批量归一化(Batch Normalization, BN)。BN在计算机视觉领域广泛应用,但在NLP任务中效果不佳,原因是BN在训练过程中可能会导致性能显著下降。作者通过系统性研究Transformer模型,揭示了BN表现不佳的根本原因,并提出了一种新的归一化方法——Power Normalization (PN)来解决这个问题。"
在神经网络中,归一化技术是非常关键的一环,它有助于加速训练过程、提高模型稳定性和泛化能力。层归一化和批量归一化是两种主要的归一化策略。
**批量归一化(BN)** 是在2015年由Ioffe和Szegedy提出的,其核心思想是在每个mini-batch的数据上进行标准化操作,即计算均值和方差,然后对数据进行缩放和平移。BN在图像识别等计算机视觉任务中表现出色,因为它可以有效地缓解内部协变量位移问题,即随着网络深度增加,每一层输入分布的变化。
**层归一化(LN)** 则是针对NLP任务设计的,由Ba等人在2016年提出。与BN不同,LN对每个序列元素的隐藏状态进行归一化,而不是整个批次。这种做法避免了BN在处理变长序列时的挑战,因为NLP任务中的序列长度通常不固定。
然而,尽管LN在NLP中更受欢迎,但BN在NLP任务中为何表现不佳的问题尚未得到充分解释。论文指出,NLP数据在批次维度上的统计特性存在大幅波动,这在训练过程中可能导致BN的不稳定。这些波动使得BN在处理NLP数据时难以维持恒定的统计特性,从而影响模型的训练。
为了解决这个问题,论文提出了**Power Normalization (PN)** 方法。PN通过放松BN中的均值和方差计算,降低了对批次大小敏感性的依赖,从而在保持BN优势的同时,解决了在NLP任务中BN性能下降的问题。PN的引入旨在改善BN的稳定性,并且可能适用于其他对批次大小变化敏感的领域。
这篇研究不仅揭示了NLP中BN表现不佳的原因,还提供了一种新的归一化策略,以适应NLP任务的特性,有望推动NLP模型的进一步优化。未来的研究可能还会探索如何将PN与其他归一化技术结合,以实现更高效、更稳定的模型训练。
20% 40% 60% 80% 100%
Percent of Training Epochs
0.00
0.01
0.02
0.03
0.04
0.05
0.06
0.07
1
d
||
B
||
CIFAR10
IWSLT14
20% 40% 60% 80% 100%
Percent of Training Epochs
0
1
2
3
4
5
6
1
d
||
2 2
B
||
CIFAR10
IWSLT14
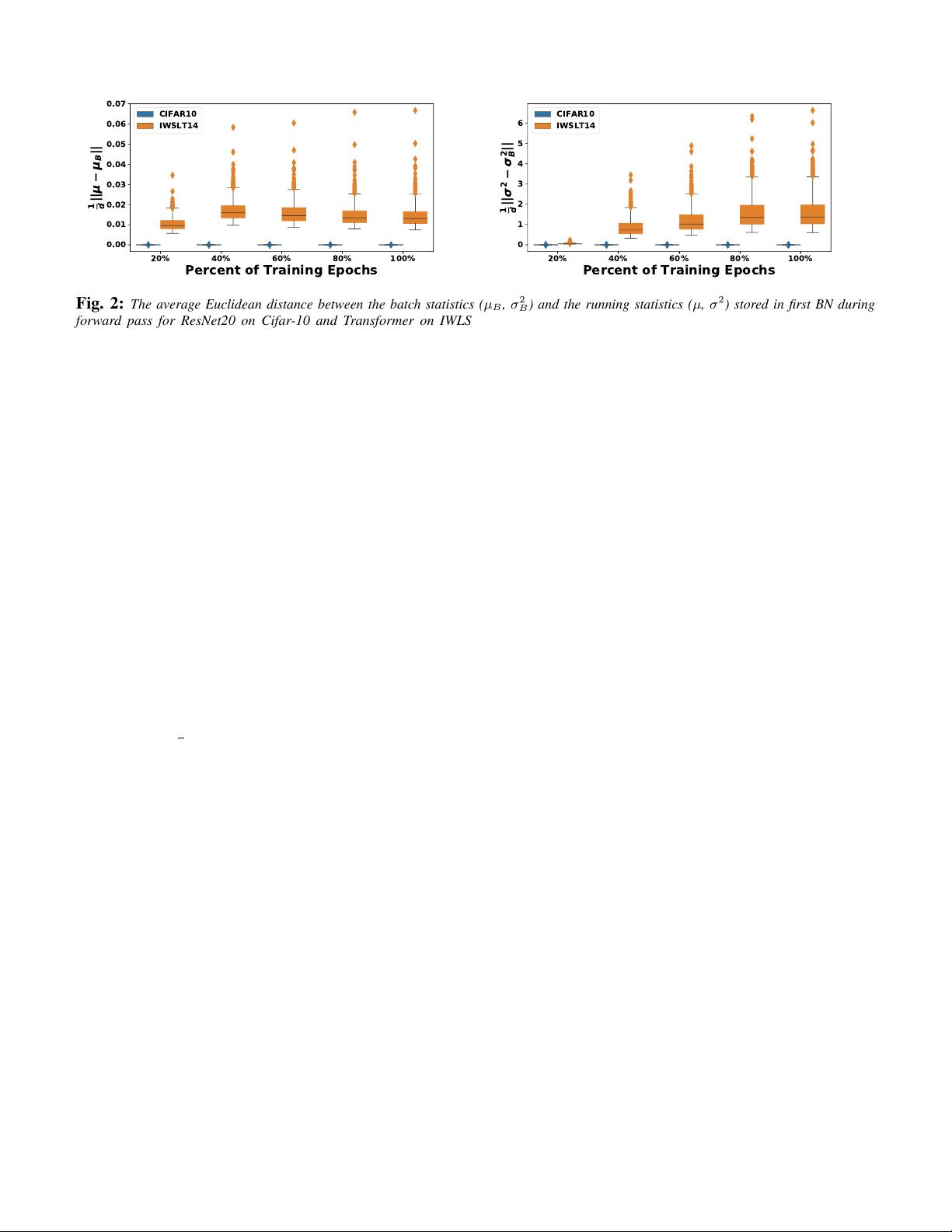
Fig. 2:
The average Euclidean distance between the batch statistics (
µ
B
,
σ
2
B
) and the running statistics (
µ
,
σ
2
) stored in first BN during
forward pass for ResNet20 on Cifar-10 and Transformer on IWLST14. We can clearly see that the ResNet20 statistics have orders of
magnitude smaller variation than the running statistics throughout training. However, the corresponding statistics in Transformer
BN
exhibit
very high variance with extreme outliers. This is true both for the mean (shown in left) as well as variance (shown in right). This is one of
the contributing factors to the low performance of BN in transformers.
This is a significant performance degradation, and
it stems from instabilities associated with the above
four batch statistics. To analyze this, we studied the
batch statistics using the standard setting of ResNet20
on Cifar-10 and Transformer
BN
on IWSLT14 (using a
standard batch size of 128 and tokens of 4K, respectively).
In the first experiment, we probed the fluctuations
between batch statistics,
µ
B
/
σ
B
, and the corresponding
BN running statistics,
µ
/
σ
, throughout training. This is
shown for the first BN layer of ResNet20 on Cifar-10
and Transformer
BN
on IWSLT14 in Figure 2. Here, the
y-axis shows the average Euclidean distance between
batch statistics (
µ
B
,
σ
B
) and the running statistics
(
µ
,
σ
), and the x-axis is different epochs of training,
where we define the average Euclidean distance as
distpµ
B
, µq “
1
d
}µ
B
´ µ}.
The first observation is that Transformer
BN
shows
significantly larger distances between the batch statistics
and the running statistics than ResNet20 on Cifar-10,
which exhibits close to zero fluctuations. Importantly,
this distance between
σ
B
and
σ
significantly increases
throughout training, but with extreme outliers. During
inference, we have to use the running statistics. However,
such large fluctuations would lead to a large inconsistency
between statistics of the testing data and the BN’s
running statistics.
The second observation comes from probing the norm
of
g
µ
and
g
σ
2
defined in Eq. 3, which contribute to
the gradient backpropagation of input. These results
are shown in Figure 3, where we report the norm of
these two parameters for ResNet20 and Transformer
BN
.
For Transformer
BN
, we can see very large outliers,
that actually persist throughout training. This is in
contrast to ResNet20, for which the outliers vanish as
training proceeds.
IV. POWER NORMALIZATION
Based on our empirical observations, we propose
Power Normalization (PN), which effectively resolves
the performance degradation of BN. This is achieved
by incorporating the following two changes to BN.
First, instead of enforcing unit variance, we enforce
unit quadratic mean for the activations. The reason
for this is that we find that enforcing zero-mean and
unit variance in BN is detrimental due to the large
variations in the mean, as discussed in the previous
section. However, we observe that unlike mean/variance,
the unit quadratic mean is significantly more stable for
transformers. Second, we incorporate running statistics
for the quadratic mean of the signal, and we incorporate
an approximate backpropagation method to compute the
corresponding gradient. We find that the combination of
these two changes leads to a significantly more effective
normalization, with results that exceed LN, even when
the same training hyper-parameters are used. Below we
discuss each of these two components.
A. Relaxing Zero-Mean and Enforcing Quadratic Mean
Here, we describe the first modification in PN. As
shown in Figure 2 and 3,
µ
B
and
g
µ
exhibit significant
number of large outliers, which leads to inconsistencies
between training and inference statistics. We first address
this by relaxing the zero-mean normalization, and we use
the quadratic mean of the signal, instead of its variance.
The quadratic mean exhibits orders of magnitude smaller
fluctuations, as shown in Figure 4. We refer to this
4
剩余18页未读,继续阅读
297 浏览量
338 浏览量
398 浏览量
160 浏览量
550 浏览量
2021-08-31 上传
2021-09-01 上传
2023-08-25 上传
2022-02-19 上传

syp_net
- 粉丝: 158
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python大数据应用教程:基础教学课件
- Android事件分发库:对象池与接口回调实现指南
- C#开发的斗地主网络版游戏特色解析
- 微信小程序地图功能DEMO展示:高德API应用实例
- 构建游戏排行榜API:Azure Functions和Cosmos DB的结合
- 实时监控系统进程CPU占用率方法与源代码解析
- 企业商务谈判网站模板及技术源码资源合集
- 实现Webpack构建后自动上传至Amazon S3
- 简单JavaScript小计算器的制作教程
- ASP.NET中jQuery EasyUI应用与示例解析
- C语言实现AES与DES加密算法源码
- 开源项目实现复古游戏机控制器输入记录与回放
- 掌握Android与iOS异步绘制显示工具类开发
- JAVA入门基础与多线程聊天售票系统教程
- VB API实现串口通信的调试方法及源码解析
- 基于C#的仓库管理系统设计与数据库结构分析
