Kudu:Hadoop生态的快速分析新存储解决方案
149 浏览量
更新于2024-08-27
收藏 508KB PDF 举报
"Kudu是Cloudera开源的列式存储系统,旨在支持快速分析和处理快速变化的数据,作为Hadoop生态系统中的新成员。Kudu填补了Hadoop存储层的空白,提供快速插入、修改和查询功能,以应对混合架构的需求。在传统的HDFS/Parquet+HBase混合架构中,数据处理流程复杂且易出错,Kudu的出现解决了这些问题,提供高性能的计算能力和简单的数据模型,支持原地修改和扩展。随着硬件技术的进步,如RAM的发展,Kudu能够更好地利用硬件资源,实现高效的数据操作。"
Kudu是针对现代数据分析需求设计的,它的主要目标是提供一个既支持快速写入和更新,又具备高效分析性能的存储解决方案。与HDFS相比,Kudu在设计时考虑了实时和频繁更新的数据场景,而HDFS更适合批处理和静态数据。同时,相比于HBase,Kudu更侧重于分析工作负载,而不是键值存储。
Kudu的核心特性包括:
1. **列式存储**:如同Parquet一样,Kudu使用列式存储格式,优化了数据分析的效率,因为列式存储在读取特定列时可以减少不必要的I/O操作。
2. **快速插入与更新**:Kudu支持对数据的实时插入和更新,这使得它在需要频繁修改数据的应用场景下比HDFS和Parquet更有优势。
3. **分布式架构**:Kudu的分布式架构设计确保了高可用性和容错性,通过副本机制保证数据的安全性和一致性。
4. **多版本并发控制(MVCC)**:Kudu使用MVCC来支持并发读写操作,保证在读写操作之间的一致性,适合OLAP(在线分析处理)和部分OLTP(在线事务处理)工作负载。
5. **灵活的数据模型**:Kudu支持丰富的数据类型和灵活的表结构,允许用户根据业务需求创建复杂的表模式。
6. **高效的资源利用**:Kudu优化了CPU和I/O资源的使用,特别是在处理大量数据时,能够有效利用硬件资源,提高整体性能。
7. **易于集成**:Kudu可以无缝集成到Hadoop生态系统中,与Impala、Hive、Presto等查询引擎配合使用,简化数据分析流程。
由于Kudu的设计初衷是为了弥补Hadoop生态系统的空白,它在许多实际应用中已经替代了传统的混合架构,简化了数据处理流程,提高了数据分析的时效性和准确性。随着硬件技术的持续进步,Kudu在未来有望在大数据分析领域发挥更大的作用,为企业提供更加高效、灵活的数据存储和分析平台。
Kudu:支持快速分析的新型支持快速分析的新型Hadoop存储系统存储系统
Kudu 是 Cloudera 开源的新型列式存储系统,是 Apache Hadoop 生态圈的新成员之一( incubating ),专门为了对快速变化
的数据进行快速的分析,填补了以往 Hadoop 存储层的空缺。
背景——功能上的空白
Hadoop 生态系统有很多组件,每一个组件有不同的功能。在现实场景中,用户往往需要同时部署很多 Hadoop 工具来解决同
一个问题,这种架构称为 混合架构 (hybrid architecture) 。 比如,用户需要利用 Hbase 的快速插入、快读 random access 的
特性来导入数据, HBase 也允许用户对数据进行修改, HBase 对于大量小规模查询也非常迅速。同时,用户使用
HDFS/Parquet + Impala/Hive 来对超大的数据集进行查询分析,对于这类场景, Parquet 这种列式存储文件格式具有极大的
优势。
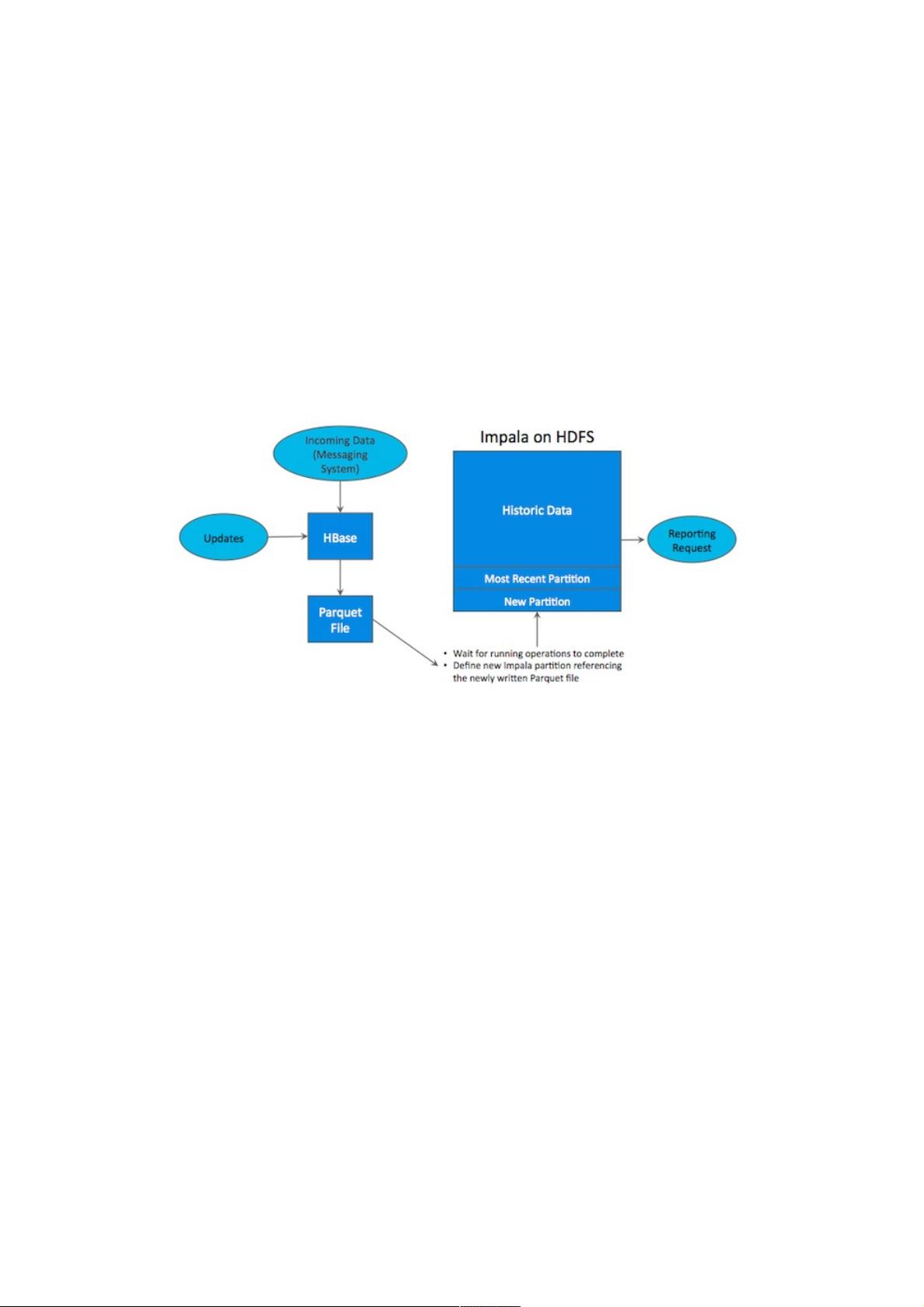
很多公司都成功地部署了 HDFS/Parquet + HBase 混合架构,然而这种架构较为复杂,而且在维护上也十分困难。首先,用
户用 Flume 或 Kafka 等数据 Ingest 工具将数据导入 HBase ,用户可能在 HBase 上对数据做一些修改。然后每隔一段时间 (
每天或每周 ) 将数据从 Hbase 中导入到 Parquet 文件,作为一个新的 partition 放在 HDFS 上,最后使用 Impala 等计算引擎
进行查询,生成最终报表。
这样一条工具链繁琐而复杂,而且还存在很多问题,比如:
1.如何处理某一过程出现失败?
2.从 HBase 将数据导出到文件,多久的频率比较合适?
3.当生成最终报表时,最近的数据并无法体现在最终查询结果上。
4.维护集群时,如何保证关键任务不失败?
5.Parquet 是 immutable ,因此当 HBase 中删改某些历史数据时,往往需要人工干预进行同步。
这时候,用户就希望能够有一种优雅的存储解决方案,来应付不同类型的工作流,并保持高性能的计算能力。 Cloudera 很早
就意识到这个问题,在 2012 年就开始计划开发 Kudu 这个存储系统,终于在 2015 年发布并开源出来。 Kudu 是对 HDFS 和
HBase 功能上的补充,能提供快速的分析和实时计算能力,并且充分利用 CPU 和 I/O 资源,支持数据原地修改,支持简单
的、可扩展的数据模型。
背景——新的硬件设备
RAM 的技术发展非常快,它变得越来越便宜,容量也越来越大。 Cloudera 的客户数据显示,他们的客户所部署的服务器,
2012 年每个节点仅有 32GB RAM ,现如今增长到每个节点有 128GB 或 256GB RAM 。存储设备上更新也非常快, 在很多
普通服务器中部署 SSD 也是屡见不鲜。 HBase 、 HDFS 、以及其他的 Hadoop 工具都在不断自我完善,从而适应硬件上的
升级换代。然而,从根本上, HDFS 基于 03 年 GFS , HBase 基于 05 年 BigTable ,在当时系统瓶颈主要取决于底层磁盘
速度。当磁盘速度较慢时, CPU 利用率不足的根本原因是磁盘速度导致的瓶颈,当磁盘速度提高了之后, CPU 利用率提
高,这时候 CPU 往往成为系统的瓶颈。 HBase 、 HDFS 由于年代久远,已经很难从基本架构上进行修改,而 Kudu 是基于
全新的设计,因此可以更充分地利用 RAM 、 I/O 资源,并优化 CPU 利用率。我们可以理解为, Kudu 相比与以往的系统,
CPU 使用降低了, I/O 的使用提高了, RAM 的利用更充分了。
简介
Kudu 设计之初,是为了解决一下问题:
下载后可阅读完整内容,剩余5页未读,立即下载

weixin_38642349
- 粉丝: 2
- 资源: 895
 我的内容管理
展开
我的内容管理
展开







最新资源
- Axure简单搜索原型.zip
- hatienl0i261299.github.io
- 医学治疗展示响应式网页模板
- svm多分类matlab程序.rar.rar
- VirtualGlass_NguyenDucTho
- Java源码查看器-VncThumbnailViewer:连接到多台服务器的VNC客户端,可从https://code.google.com/
- VS2022 DonetCore6.0 Ajax数据交易
- docker-Postfix-AD:具有Microsoft AD后端的CentOS 7上的邮件服务器
- Miniature-Wind-Turbine:ELEC 391设计项目-具有180°风向的微型风力发电机。 带有3D打印涡轮叶片的手动上链发电机。 配备由Arduino控制的MPPT升压转换器
- ColorSchaffMomentumTrendCycle_HTF - MetaTrader 5脚本.zip
- 社区用户信息组件响应式网页模板
- evernote:创建Evernote Docker映像
- 5G终端行业报告(24页).zip
- stock_trading_app
- 最终软件测试
- SVMcgForClass.rar
