使用KMeans发现数据聚类模式
版权申诉
192 浏览量
更新于2024-08-04
收藏 186KB PDF 举报
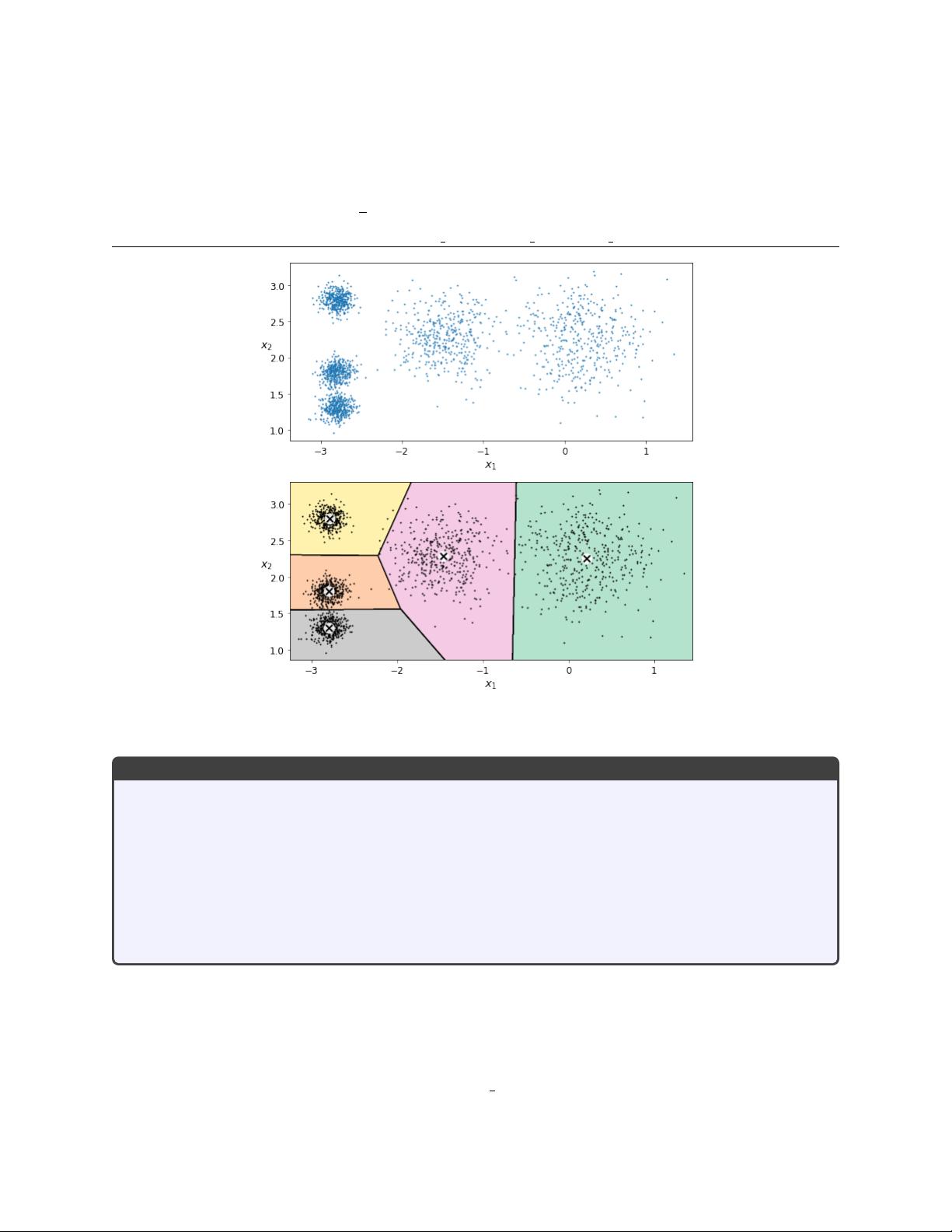
"cluster_lab.pdf 是一个关于机器学习中聚类实验的文档,特别是关注KMeans算法在数据聚类中的应用。文档强调了通过减少方差来发现数据的聚类模式,并介绍了如何评估聚类的紧密程度。文档还提到了在多维数据中使用协方差矩阵来分析数据的变异、独立性和相关性。对于存在多个中心的情况,KMeans是一个更优的选择,选择合适的簇数量是关键,可以通过观察惯性(inertia)来指导。文档提供了几个数据集的链接供用户下载进行练习。"
在机器学习领域,聚类是一种无监督学习方法,用于将数据分组到不同的类别或簇中,使得相同簇内的数据点彼此相似,而不同簇的数据点差异较大。KMeans是最常用的聚类算法之一,其工作原理是迭代地分配每个数据点到最近的簇中心,并在每次迭代后更新这些中心。
**Variance and KMeans**:
- 方差是衡量数据点在簇内分布的紧密程度的一个指标。如果方差较小,说明数据点聚集得更紧密,聚类效果较好。
- 在假设数据只属于单个簇的情况下,可能需要先对数据进行标准化,使所有特征在同一尺度上,以便于比较。
- 对于多维数据,协方差矩阵能够提供每个特征的变异情况,以及特征之间的相互独立性和相关性。这有助于理解数据的结构和簇的形态。
**KMeans的使用**:
- KMeans算法的核心是确定簇的数量(k值)。选择合适的k值对聚类结果至关重要,通常需要试验不同k值并分析结果。
- 惯性是KMeans的一种评估指标,它表示各个簇内部的总平方误差之和,反映了簇的紧凑程度。惯性的变化可以指示最佳的簇数量。
**数据集**:
文档中提到了几个数据集供练习,例如:
1. `hwdata.txt`
2. `faithfuldata.txt`
3. `ruspinidata.txt`
4. `blobsdata.txt`
5. `blobsclusters.txt`
6. `blobscenters.txt`
这些数据集涵盖了不同的场景,比如`blobsdata.txt`可能包含人为生成的多簇数据,而`faithfuldata.txt`可能是基于真实世界现象(如间歇泉的喷发间隔)的数据。
通过这些练习,读者可以实践KMeans算法,理解如何根据数据的特性选择合适的聚类方法,以及如何分析聚类结果的有效性。同时,这也是提高数据分析和机器学习技能的重要步骤。
Variance and KMeans
ML 2022: Machine Learning
https://people.sc.fsu.edu/∼jburkardt/classes/ml 2022/cluster lab/cluster lab.pdf
Using KMeans, we can discover how data has formed cluster patterns.
Variance reduction!
We are interested in how much our data clusters around one or more centers.
• variance measures the tightness of the clustering;
• If we suspect a single cluster, we may want to standardize the data first;
• For multidimensional data, the covariance matrix reports variance, independence, and correla-
tion of the data;
• If there are multiple centers, a better model is available through kmeans;
• To use kmeans, we need to choose the number of clusters;
• The behavior of the inertia suggests the right number of clusters;
1 Copying the data
Each of the exercises will be carried out on a particular datafile. These datafiles are available on the datasets
page at the class website:
https://people.sc.fsu.edu/∼jburkardt/classes/ml 2022/datasets/datasets.html
You might go ahead now and download them all:
1
下载后可阅读完整内容,剩余4页未读,立即下载
2021-10-02 上传
2024-03-31 上传
2021-10-30 上传
2021-10-20 上传
2021-10-30 上传
2021-09-30 上传
点击了解资源详情
2024-11-27 上传
2024-11-27 上传
2024-11-27 上传

卷积神经网络
- 粉丝: 364
- 资源: 8440
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
