Hypertable:C++实现的Bigtable开源版,分布式结构化数据处理
136 浏览量
更新于2024-08-29
收藏 1.17MB PDF 举报
"Hypertable是一个开源的分布式数据库系统,用C++编写,其设计灵感来源于Google的Bigtable。它旨在处理大规模的结构化数据,尤其是在云计算平台中,为PB级别的数据提供高效的存储和访问解决方案。Hypertable通过分布式并行文件系统如GFS、HDFS和KFS来解决大数据存储问题,并在此基础上构建了一个面向表格的分布式数据组织模型,允许用户以类似SQL的方式访问数据。
1. 数据模型与Tablet Location
Hypertable的数据模型采用了多维稀疏矩阵的概念,类似于表格结构。每个矩阵的行代表了Row,由RowKey(主键)唯一标识,可以按字典顺序排序。列族(ColumnFamily)是第二维度,它是一组具有相同类型属性的列(ColumnQualifier)的集合。列族内的列数量理论上无限制,命名方式为family:qualifier。时间戳作为第四维度,记录了每个值(Value)的插入时间,使得数据具有时间版本管理的能力。
2. 行键(RowKey)
RowKey是任意长度不超过64Kbyte的字符序列,作为数据的主键。所有的行操作都基于RowKey进行,且这些操作是原子性的,确保了数据一致性。例如,插入、更新和删除操作都会以整个行为单位执行。
3. 分布式架构
Hypertable的设计考虑了高可用性和可扩展性。数据被分割成逻辑上的单元——Tablets,这些Tablets分布在整个集群中,可根据负载动态调整。每个Tablet在节点间可以平滑迁移,以应对数据增长和节点变化。这种设计使得Hypertable能够轻松处理大量并发请求,并在集群规模扩大时保持性能。
4. 存储与查询
Hypertable使用列式存储,优化了数据分析和检索效率,特别是对于大数据量的扫描操作。此外,虽然不支持完整的SQL,但Hypertable提供了类似SQL的查询接口,便于用户进行数据查询和操作。
5. 数据版本控制
Hypertable的时间戳特性允许保留历史版本,用户可以根据时间戳选择查看或删除特定版本的数据,这在审计跟踪和数据恢复场景中非常有用。
6. 高性能与可靠性
通过复制和故障恢复机制,Hypertable保证了数据的可靠性和服务的连续性。数据在多个节点间冗余,即使部分节点失败,也能保证服务的正常运行。
综上,Hypertable是一个强大的分布式数据库解决方案,尤其适合需要处理大规模结构化数据的应用场景,如互联网服务、数据分析和大数据处理等。其设计理念和功能特性使得它在云环境中的表现优秀,能够满足高吞吐量、低延迟以及灵活扩展的需求。"
Hypertable简介简介(一个一个C++的的Bigtable开源实现开源实现)
1.Introduction
随着互联网技术的发展,尤其是云计算平台的出现,分布式应用程序需要处理大量的数据(PB级)。在一个或多个云计算平台中
(成千上万的计算主机),如何保证数据的有效存储和组织,为应用提供高效和可靠的访问接口,并且保持良好的伸缩性和可扩
展性,成为云计算平台需要解决的关键问题之一。分布式并行文件系统,为云计算平台解决了海量数据存储问题,并且提供了
统一的文件系统命令空间,如GFS、Hadoop HDFS、KFS等,在此基础上, Hypertable实现了分布式结构化的数据组
织,Hypertable可以对海量的结构化的数据(PB级)提供面向表形式的组织方式,并向应用提供类似表访问的接口(如SQL接口)
2 Structured Data and Tablet Location
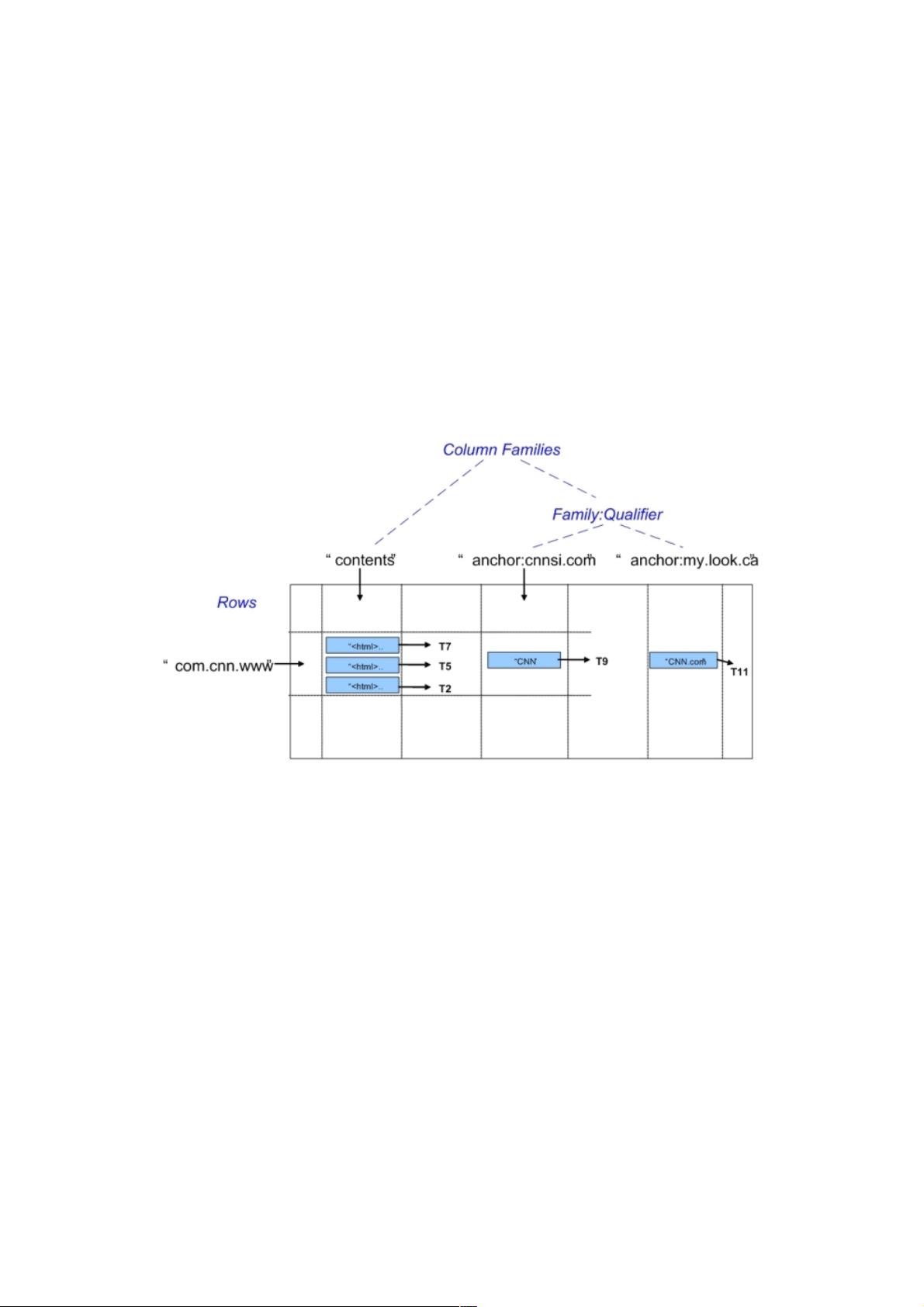
2.1 数据模型(Data Model)
Hypertable采用类似表的形式组织数据,但目前Hypertable并不支持关系数据库中丰富的关系属性。Hypertable将数据组织成
一个多维稀疏矩阵。该矩阵中的所有行信息可以基于主键(Primary Key)进行排序。在该多维矩阵中第一维称为行
(Row),行键值(Row Key)即为Primary Key;第二维即列族(Column Family),一个列族包含多个列(Column
Qualifier)的集合,它们一般具有相同的类型属性,系统在存储和访问表时,都是以Column Family为单元组织;第三维即列
(Column Qualifier),理论上,一个列族中列的个数不受限制,列的命名方式通常采用family:qualifier的方式;最后一维就是
时间戳(Timetstamp),它通常是系统在插入一项数据时自动赋予。如果我们把行和列族看成三维矩阵的行和列,那么我们
可以将“时间戳”看成是纵向深度坐标。如图2-1所示,Tn就是每项值(Value)的“深度”标签。
Figure 2-1 A Multi-Dimensional Table
2.1.1 行键(Row Key)
Hypertable中Row Key定义为任意的字符序列(长度不超过64Kbyte,通常的应用也就百个字节左右),所有行以Row key为
主键进行字典排序。在Hypertable中队行的操作保持原子性,对行的插入(Insert)、更新(Update)、删除(Delete)等都
保持整行的原子操作,无论行操作涉及到的列的个数。在Hypertable中保持行操作的原子性,对应用程序来说显然具有积极的
意义,它使得Hypertable对应用程序来说,行的一致性得到保证。
在Hypertable中,所有的行数据按照Row Key的字典序排列,如图2-1,随着数据量的不断增长(不断的有新的数据插入),
该多维数据表会不断增长,在一个并行的云计算平台中,当该表增长到一定大小时,系统会将该表一分为二,分别由平台中不
同的主机维护,分裂后的表可以独立增长,再进行分裂,由此反复,最终一个多维的Hypertable表实际上是以大量的“小表
(Tablet)”的形式存在于云计算平台中,它们具有完全对等的属性,分别维护表中的部分数据;一个小表(Tablet)由一台主
机维护,一台主机可以维护多个小表。在Hypertable中,表的分裂沿行区间(Row Range)切分,如图2-2所示,一张表在生
长过程中,在一定的行区间被分裂为多个行区间(Row Range),每一个行区间成文一个新的小表(Tablet)。在Hypertable
中缺省是一个Tablet增长到200M左右分裂,同时由于系统在并行处理平台上运行,会根据负载均衡原则进行调解。在云计算
平台中,分裂出来的Tablet基于Load Balance原则被分布在不同的主机上维护,从而,对表的操作演化成对各小表(Tablet)
的操作,处理效率显然高于对整个大表的操作。用户在使用Hypertable时合理的选择Row Key,可以得到更好的数据处理效
率。例如在处理大量网页数据时(网页crawler获取的网页数据),通常把网页URL作为Row Key,其中URL的主机域名被反
序处理(如maps.google.com/index.html被反置为com.google.maps/index.html),如此具有相同域的网页被尽可能的组织在
相同或相邻的Tablet中,因此应用程序在处理这些数据时能得到更好的效率。
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
2012-04-19 上传
2013-07-22 上传
2012-04-24 上传
2015-08-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38500117
- 粉丝: 5
- 资源: 998
 我的内容管理
展开
我的内容管理
展开







最新资源
- 搜索引擎-原理、技术与系统.pdf
- mysql视图简介.pdf
- SEO Book By:Google
- iphone cook book
- MIMO及智能天线技术简介
- Quick.Recipes.On.Symbian.OS-Mastering.CPP.Smartphone.Development
- 进销存管理系统(开发文档)
- Tornado使用指南
- 基于Delphi技术的图书管理系统设计
- Oracle9i SQL Reference官方文档
- UNIX 环境高级编程
- 需求规格说明书(Volere版)
- ExtJs中文帮助文档
- VMwareWorkstation6基本使用
- 华南理工电子电子考研试卷
- 2008 acm 个人赛
