分布式流处理框架:Spark、Flink、Storm等性能对比与评估
版权申诉
100 浏览量
更新于2024-07-06
收藏 1.44MB PDF 举报
《分布式流式数据处理框架:功能对比以及性能评估》是一篇由王华峰、毛玮和张天伦在2016年10月27日发布的研究论文,主要关注于当时流行的分布式流式数据处理框架的比较和性能评估。该报告针对的是大数据技术领域,特别关注了Apache Spark Streaming、Apache Flink、Apache Storm(包括Trident API)、Apache Gearpump、Twitter Heron等关键框架。
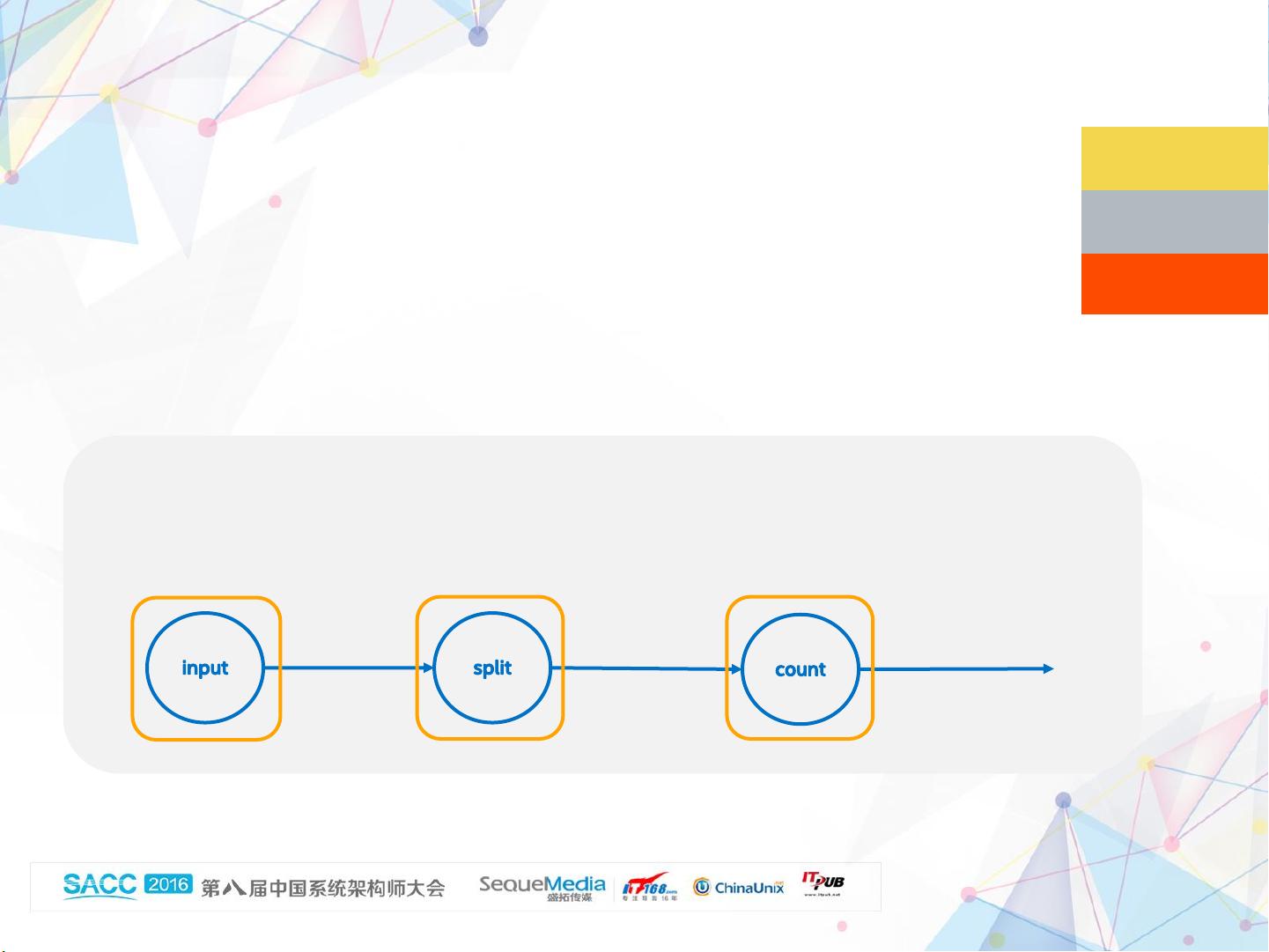
文章的核心部分首先介绍了执行模型,包括StreamCore和MISC(可能指的是基础架构和中间件组件)。执行模型是数据处理流程的基础,它定义了数据如何在系统中流动,以及故障恢复机制是如何设计的。这些框架各有其独特的优势,例如:
1. **Apache Spark Streaming**:提供了一种基于微批处理的连续流处理方式,允许用户定义时间窗口进行聚合操作。其执行模型支持批量处理,但具有较高的延迟,适合对实时性要求相对较低的应用场景。
2. **Apache Flink**:强调低延迟和高吞吐量,采用精确一次(Exactly-once)处理,提供了细粒度的时间控制,支持微批处理和真正的实时流处理。
3. **Apache Storm** 和 **Apache Storm Trident**:两者都是基于消息传递的实时流处理框架,Trident API 提供了更高级别的接口来处理复杂的数据流逻辑。它们支持持续流处理,并通过每批次检查点实现故障恢复。
4. **Apache Gearpump**:Intel研发的框架,注重高效并发和资源管理,提供了一种灵活的执行模型,适用于实时数据处理。
5. **Twitter Heron**:Twitter的下一代流处理系统,设计上强调可扩展性和容错性,用于处理Twitter的实时数据流。
性能评估部分着重于这些框架在数据源(如事件生产者)、操作符(如过滤、转换)和sink(数据接收端)上的性能表现,以及它们在检查点策略(如批次检查点和记录级别的确认)上的差异。这些指标对于选择合适的框架以及优化工作负载至关重要。
这篇论文为理解不同分布式流式数据处理框架的功能特性、执行效率以及在实际应用中的性能优劣提供了有价值的信息,帮助开发者根据项目需求选择最适合的工具。对于从事大数据处理和实时计算的工程师来说,深入理解和分析这篇报告的内容是提升技术水平和做出明智决策的关键。

API
剩余48页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-08-23 上传
2017-10-11 上传
2021-08-08 上传
2021-08-15 上传
2021-08-15 上传
2023-03-21 上传









