GAN与Mesh模型驱动的弱监督手部姿态估计与物体识别提升
181 浏览量
更新于2024-06-20
收藏 1.57MB PDF 举报
标题:“基于GAN和Mesh模型的弱监督域自适应物体估计”探讨了一个针对手部姿态估计(HPE)在复杂场景如手-物体交互(HOI)中的提升方法。在这个领域,传统的RGB HOI数据集,如Dexter-Object、Ego-Dexter和HO3D,由于数据量有限且缺乏真实3D标注,特别是对于遮挡情况,限制了模型的性能。作者团队提出了一个创新的端到端学习框架,利用生成对抗网络(GAN)和三维网格模型(Mesh Model)来解决这些问题。
首先,通过GAN技术,该研究旨在在图像空间内实现域自适应,通过对2D像素级别的指导,使得模型能够更好地处理遮挡和复杂背景。GAN的优势在于其能够精确对齐手部,而Mesh模型则擅长填充被遮挡的像素,从而提高3D手部姿态的准确性。这种方法允许模型仅使用带姿势标签的纯手图像和无标签的HOI图像进行训练,显著改进了在遮挡场景下的估计性能。
在介绍部分,文章指出,尽管深度学习方法和大规模数据集对传统手部姿态估计有显著贡献,但在处理手部与物体交互的复杂情况时,仍面临遮挡和背景干扰的挑战。作者强调,他们的方法不仅提升了3D HPE的精度,还实现了HOI输入图像的分割和去遮挡,生成更清晰的仅手图像,这对于后续的手部动作和物体识别至关重要。
实验部分展示了在Dexter-Object、Ego-Dexter和HO3D数据集上的实验结果,证实了新方法相较于仅使用手部数据训练的现有技术具有明显优势。这表明,通过结合GAN和Mesh模型的弱监督域自适应策略,可以在无需大量3D标注的情况下,有效提升手部姿态估计在实际应用中的鲁棒性和准确性。
这项工作为解决RGB HOI场景中的手部姿态估计问题提供了新的视角和解决方案,展示了如何通过混合不同技术手段,提升模型在难以处理的遮挡和背景复杂的场景中的性能。这种弱监督学习策略有望在未来的手部追踪和物体交互研究中发挥重要作用。
6123
X
xy
GT
D
R
HOI3D
L热
L热
特征和姿势
估计量
g
FPE
特征和姿态估计
器
g
FPE
GAN
发生器
g
GAN
特征和姿态估计
器
g
FPE
X
''
网格
渲染器
g
MR
LImg
Ld
网格渲染
器
g
MR
L阳
性
L阳
性
y
X
'
训练数据
X
甘
D
GAN
x对
z
(选择
x
s
H
和
d
y
GT
X
x
s
H
和
d
y
GT
X
x
s
HOI
x
s
HOI
x
s
H
和
d
+
D
R
手
D
S
手
D
R
海
D
S
配对
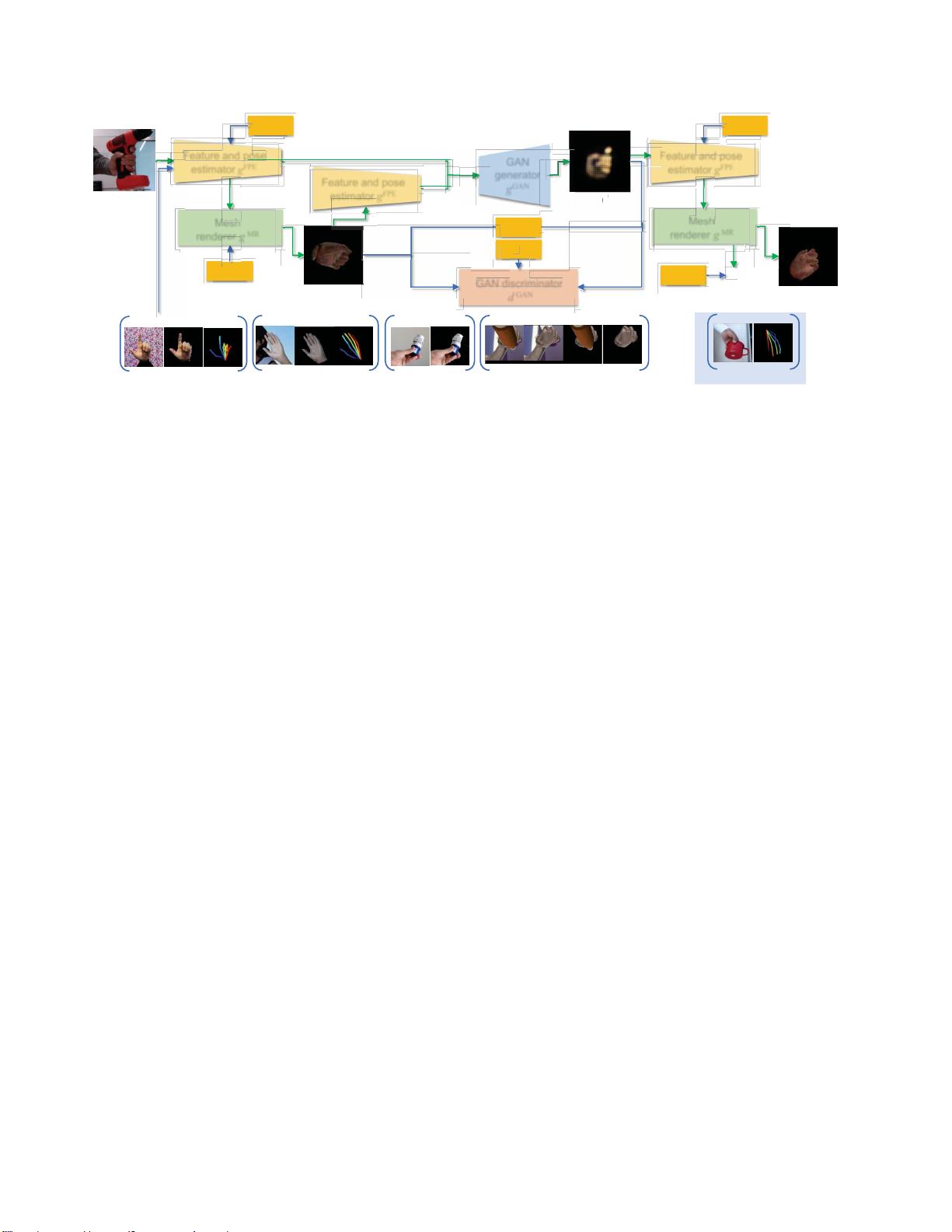
图2:通过域自适应提出的3D手部网格和姿态估计框架的示意图 我们的域自适应网络接收输入HOI RGB图像x并提
取2D特征图f和联合热图h(通过2D特征和
姿态估计器
g
FPE
)。基于它们,网格渲染器
g
MR
重建对应的
3D
网格m
和纹理t,并且此后将这些渲染为初始的仅手图像估计x
′
。分别提取的二维映射{f
,
h}和{f
′
,
h
′
}
然后,x和x
′
被馈送到
GAN
生成器
g GAN
,
GAN
生成
器
g
GAN
合成精细的仅手图像x
″
。最后,将
g
FPE
和
g
MR
应用于
x
“”
以生成免提网格m
"“
,其然后
1
)被渲染到对应的仅手图像z,以及
2
)被
用于生成骨骼关节姿态y。绿色和蓝色
箭头分别代表数据处理和监督流程
动作识别[57,3]。但是,它们缺乏数量。
最先进的:
Oberweger等人[41]建议 反馈环框架,
其嵌入深度图生成器并使用其迭代地细化估计的骨
架。Wei等人。[78]开发了一种基于部分的人体姿势估
计方法,该方法使用全局场景上下文来补偿被遮挡的
关节。该算法生成并逐渐细化中间2D热图响应。 类似
的想法也已经在3D HOI手部姿势估计中被运用(例
如,[35])。然而,它们需要构建大型HOI手部姿势数
据集。我们的算法建立在魏等人的架构[78]并且在不使
用HOI数据的3D标签的情况下,它与我们的方法类
似,Goudie et al.的算法[16]采用两阶段方法,并使用
来自HOI图像的手部分割掩模。然而,与我们的方法
不 同 , 该 方 法 不 执 行 被 遮 挡 部 分 的 去 遮 挡 ( 或 修
复),因此当手部严重遮挡时会失败。
也 有 一 些 作 品 处理 两只 手之 间 的 相 互 作 用 [74,
36]。
HPE
的域适配。已经开发了几种方法来减少真实和合
成手部数据之间的差距(只有孤立的手出现)[50,58]
或RGB和深度数据之间的差距[49,82]。然而,据我
们所知,没有一个先前的工作已经解决了适应HOI和
只手域。
3.
我们的手域适应框架
构建与对象(HOI)交互的手(HPE)的姿态估计
器是一个具有挑战性的问题:现有的HPE在仅用手的
数据集上训练,由于对象遮挡而挣扎。此外,在HOI
场景下训练新的HPE并不简单,因为带注释的真实世
界HOI数据集有限。我们建议通过将输入HOI图像映射
到相应的无对象(仅手)图像来缓解这一挑战,仅利
用易于访 问的 数 据集:仅用手 和HOI 场 景 中 的 输入
RGB图像、用于仅用手图像的骨架注释以及用于仅用
手和HOI图像的2D二进制分割掩模(其可以基于伴随
的深度图来提取;我们使用的训练数据集和数据类型的
总结见表2)。
虽然这需要恢复(或修复)被遮挡的手部区域,这
并没有一个普遍认同的解决方案,我们证明,我们的
框架往往忠实地恢复被遮挡的手,通过这样做,它可
以提供显着的性能改善现有的手姿态估计方法。
概况
.
我们的域自适应网络(
DAN
)
f
DAN
接收输
入的
256×256
大小的
RGB HOI
图像
x
∈
X
,并生成
相应的手部图像x
′
∈
X
和
21
个
3D
骨骼关节y∈
Y
估计。
表
1
提供
了符号的摘要。
受最近成功的手
剩余14页未读,继续阅读
2022-06-02 上传
2021-09-17 上传
2021-05-06 上传
2023-06-11 上传
2023-04-06 上传
2023-04-06 上传
2023-04-06 上传
2023-06-06 上传
2023-03-27 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
