"大数据工程实战:实时数据流处理方案与实践"
 已收录资源合集
已收录资源合集
需积分: 0 47 浏览量
更新于2024-03-13
收藏 4.61MB PDF 举报
本文是关于大数据工程实践的参考方案。在本文中,我们将介绍一个实际的大数据工程案例,着重介绍了实时数据流处理的相关内容。首先,我们将介绍案例的需求、背景及架构,并且明确实验的目的和任务。接着,我们将讨论时间安排和实验环境的搭建,这包括安装java、Hadoop、HBase、Spark、Flume、Kafka、Maven、Tomcat和Mysql等相关软件的步骤。最后,我们将详细介绍实验的具体步骤,包括编写python脚本、设置Ubuntu定时器、利用Flume与Kafka进行日志数据采集、在HBase中创建项目需要的表,以及构建后端项目等。通过本文的介绍,读者能够全面地了解大数据工程实践的全部流程和相关技术细节。
首先,让我们来看一下案例的需求和背景及架构。在这个案例中,我们需要处理大规模的实时数据流,对数据进行采集、清洗、存储和分析,并且实现数据可视化。针对这一需求,我们将构建一个包括Hadoop、HBase、Spark、Flume、Kafka、Maven、Tomcat和Mysql等组件的大数据处理架构,用于实时数据流处理和数据分析。
接下来,我们明确了实验的目的和任务。实验的目的是搭建一个实时数据流处理的大数据工程,并且实现数据的完整流程,从数据的采集到存储、处理和展示。在实验任务中,我们需要完成一系列的步骤和操作,包括安装环境、编写脚本、设置定时器、进行数据采集、创建数据表和构建项目等等。通过这些实验任务,我们将能够全面地掌握大数据工程实践的全部流程和技术要点。
在时间安排方面,我们需要充分考虑各种环境的安装和配置时间,以及实验步骤的具体操作时间,合理安排实验所需要的时间。在实验环境搭建方面,我们需要依次安装java、Hadoop、HBase、Spark、Flume、Kafka、Maven、Tomcat和Mysql等软件,并且进行相应的环境变量配置。这些步骤需要严格按照文中所列的步骤进行操作,以确保环境搭建的顺利进行。
当环境搭建完成后,我们将进入实验的具体步骤。首先,我们将编写python脚本,用于数据的处理和分析。然后,我们将设置Ubuntu定时器,实现定时进行数据处理的功能。接着,我们将利用Flume与Kafka进行日志数据的采集,这包括创建Flume日志文件和创建kafka主题等步骤。在HBase中,我们将创建项目需要的表,并且启动HBase等操作。最后,我们将对后端项目进行构建,包括引入相关依赖和具体的代码实现。通过这些具体的步骤,我们将逐步完成整个实验的流程,最终实现实时数据流的处理和分析。
综上所述,本文介绍了一个实际的大数据工程实践案例,详细介绍了实时数据流处理的相关内容。通过本文的阅读,读者将能够全面地了解大数据工程实践的全部流程和相关技术要点,从而为自己的大数据工程实践提供参考和指导。
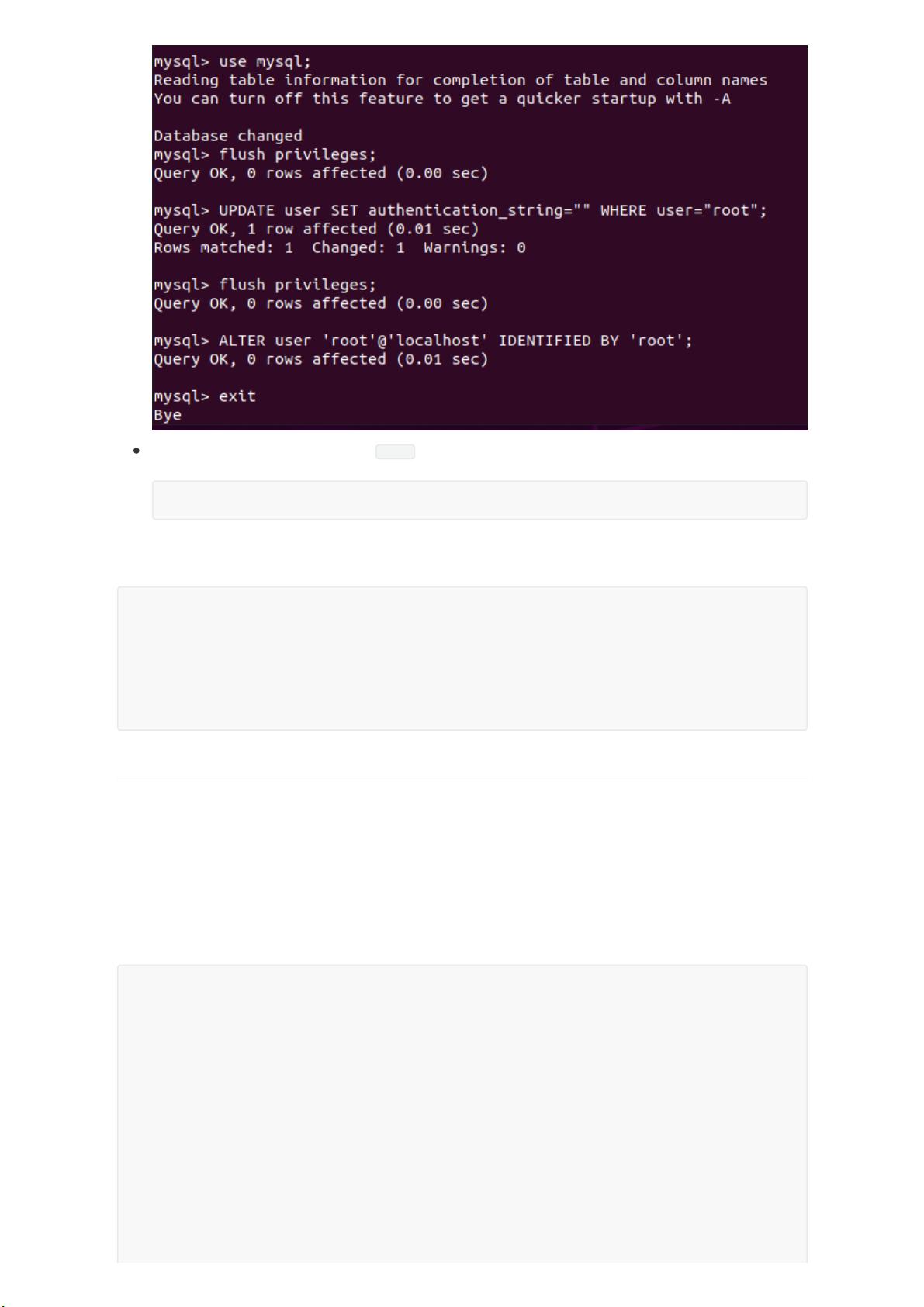
进入mysql交互模式,此时密码为 root ,修改成功。
4.10 下载JDBC驱动包
五、实验步骤
5.1 编写python脚本
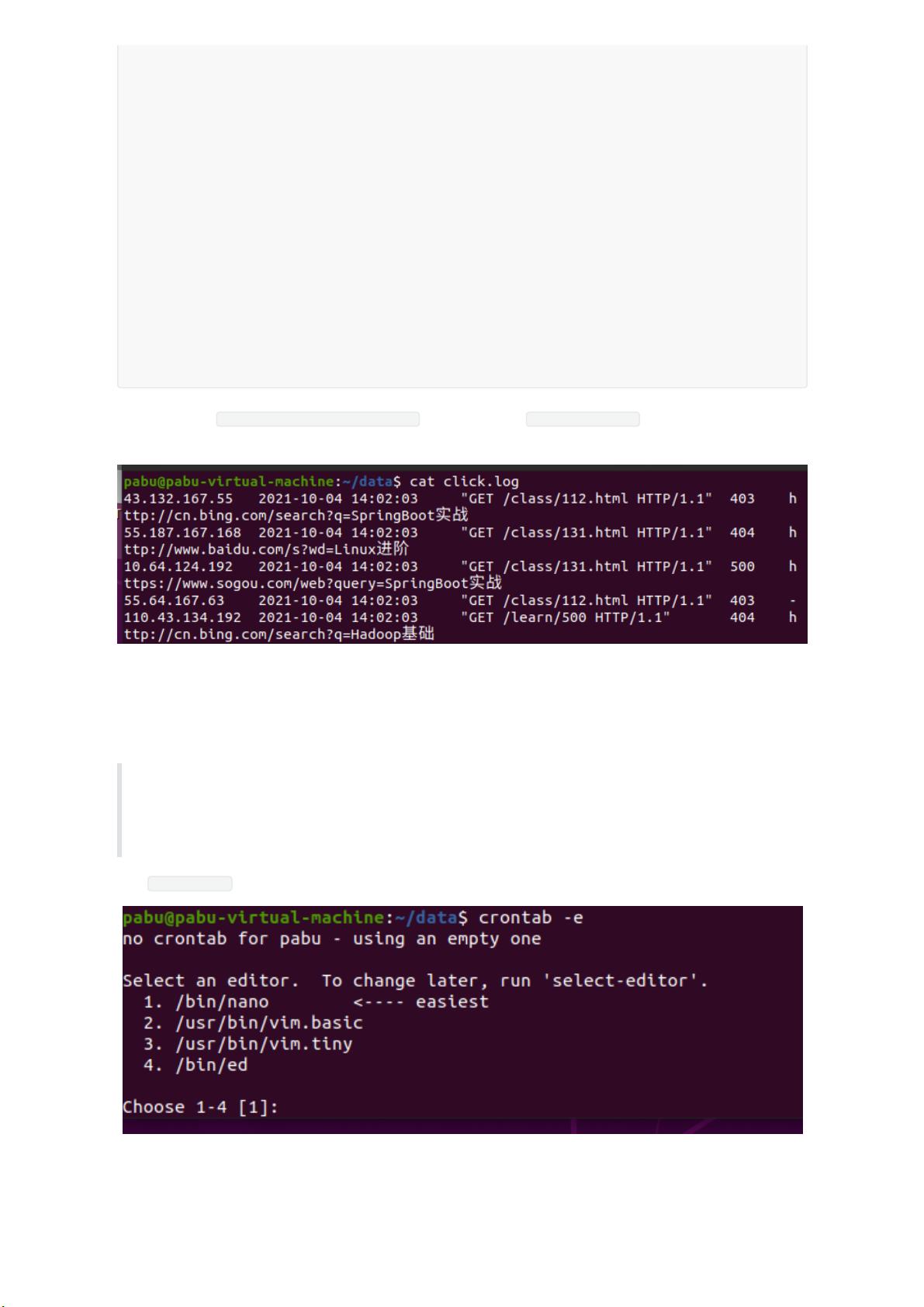
编写一个python脚本,命名为 generate_log.py,用于产生用户日志,每执行一次生成100条数据,日志
保存在/usr/你的用户名/data下面,日志文件为click.log:
在数据模块产生这一部分可以自由发挥,可以使用循环不断产生数据,也可以不断的执行该脚本,在数
据的量上也可以自由发挥。
$ mysql -u root -p
$ cd /usr/local
$ sudo wget -c http://res.aihyzh.com/大数据技术原理与应用3/15/mysql-connector-java-
5.1.40.tar.gz
$ sudo tar -zxvf mysql-connector-java-5.1.40.tar.gz -C ./
$ sudo mv mysql-connector-java-5.1.40 mysql
$ sudo chown -R pabu:pabu mysql
import random
import time
url_paths = [
"class/112.html",
"class/128.html",
"class/145.html",
"class/146.html",
"class/500.html",
"class/250.html",
"class/131.html",
"class/130.html",
"class/271.html",

剩余61页未读,继续阅读
2024-01-25 上传
2021-04-13 上传
2021-10-14 上传
2024-01-08 上传
2021-10-14 上传
2021-11-29 上传

好好学习的汉堡
- 粉丝: 24
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- flexloan:flexloan项目存储库
- innervate:网站innervate.in的源文件
- react-ts-eslint:使用启用了TS和ESLint的create-react-app创建的React应用
- Spider Search-crx插件
- legacy-sal:这是旧版存储库。 请在此处找到维护的sal回购:https:github.comsalopensourcesal
- py_project
- shizihebingwenti.rar_数值算法/人工智能_Visual_C++_
- Convenient Redmine-crx插件
- 【创新创业材料】农业相关可行性报告.rar
- CNN_LSTM_CTC_Tensorflow:使用Tensorflow实现的基于CNN + LSTM + CTC的OCR
- mytcg-f3-plugins:MyTCG-f3插件注册表
- Card Color Titles for Trello-crx插件
- matlab拟合差值代码-dissonant:音乐和弦不和谐模型
- CodesForPlacement
- smithchart.rar_matlab例程_matlab_
- congresstweets:国会每日Twitter输出的数据集
