苏宁实时日志分析实践:基于SparkStreaming的系统构建
137 浏览量
更新于2024-08-29
1
收藏 568KB PDF 举报
苏宁基于SparkStreaming的实时日志分析系统实践
苏宁的日志分析系统在面临当前数据多样化、业务需求复杂以及系统稳定性的挑战时,选择了基于SparkStreaming的实时日志分析方案。随着Hadoop技术栈的成熟,计算能力不再是主要难题,而是转向满足软性需求,例如数据可靠性和系统稳定性。为了实现智慧零售战略,苏宁易购的实时日志分析系统承担了数据分析的关键角色,处理大量流量日志,确保低延迟和数据完整性。
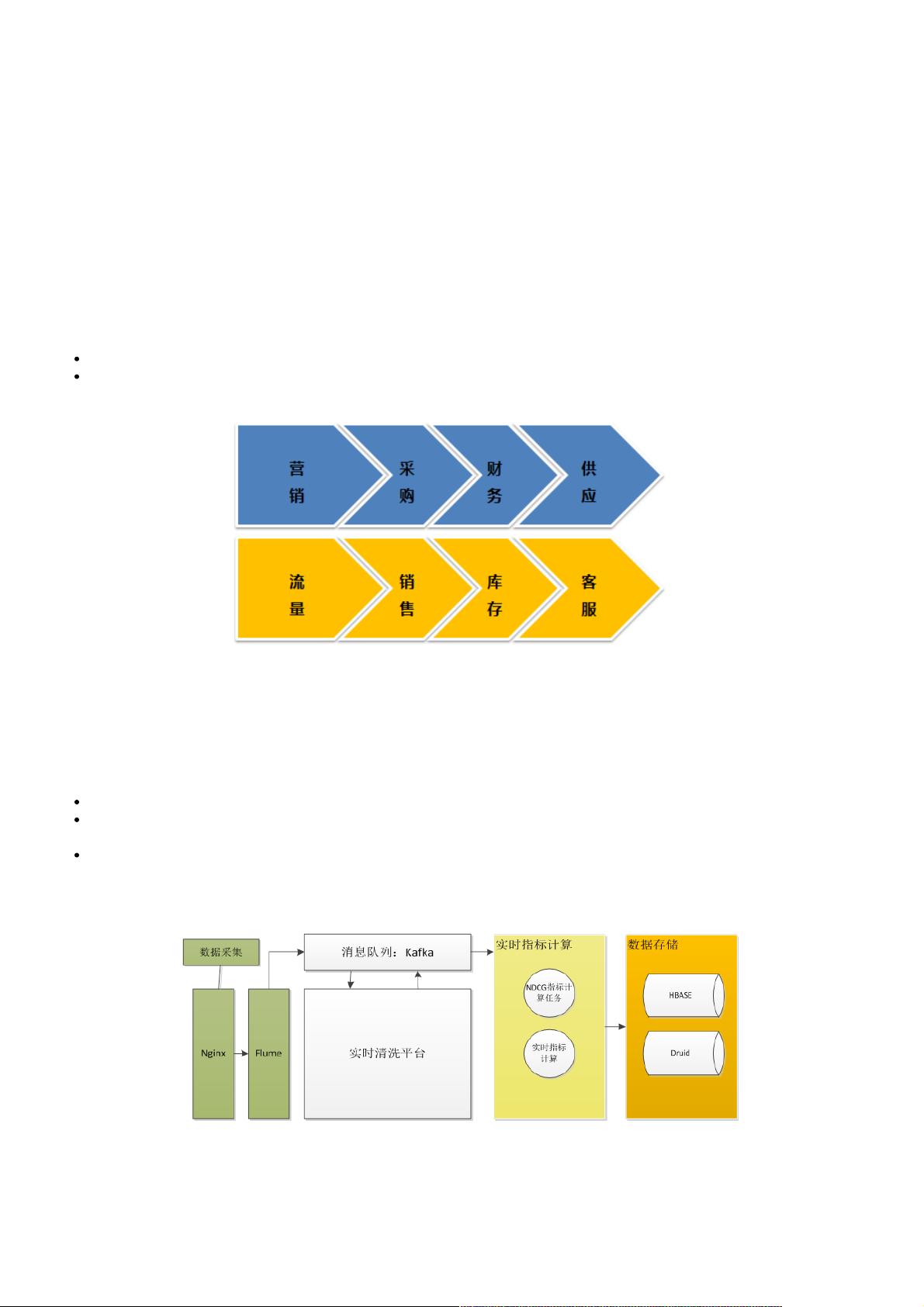
在数据分析流程上,苏宁的系统分为三个主要部分:采集、清洗和指标计算。采集阶段通过Flume收集各种数据源的日志,并将其发送到Kafka。清洗阶段由Storm实现,对日志数据进行处理、转换和清洗,然后再次发送到Kafka。清洗后的结构化数据进入指标计算阶段,这里既有Storm任务也有SparkStreaming任务。Storm适用于实时计算,而SparkStreaming则因其高吞吐量、支持SQL、开发简便和窗函数计算的特性,在准实时场景中表现出色。
苏宁的数据云平台集成了多种大数据组件,如Hive、Spark、Storm、Druid、ES、Hbase和Kafka,为集团的大数据计算和存储需求提供了全面的支持。指标计算后的数据存储在HBase和Druid等数据存储引擎中,供业务系统实时访问,为运营人员提供决策支持。
SparkStreaming是Spark的一个扩展,它通过微批处理的方式实现流处理,提供近实时的计算能力。它的设计思路是将数据流拆分成小批次,然后用Spark的批处理机制来处理。这样既能利用Spark的高效计算,又能在一定程度上满足实时性要求。SparkStreaming支持窗口操作,可以处理时间滑动窗口和会话窗口,适应不同类型的实时分析需求。
在这个系统实践中,SparkStreaming的优势在于它的高吞吐量,使得处理大规模数据流变得可能。同时,由于SparkStreaming与Spark的核心API兼容,开发人员可以使用熟悉的Spark SQL进行查询,降低了开发复杂度。此外,SparkStreaming还支持复杂的数据处理逻辑,包括状态管理和复杂的窗口函数,这对于日志分析中的实时指标计算至关重要。
总结来说,苏宁的日志分析系统通过引入SparkStreaming,有效地应对了实时分析的挑战,实现了高效、稳定的日志处理和数据分析,为智慧零售提供了强大的数据支持。这个系统的设计和实施展示了如何将大数据工具与实际业务需求相结合,构建出一个满足现代零售业需求的实时日志分析平台。
苏宁基于苏宁基于SparkStreaming的实时日志分析系统实践的实时日志分析系统实践
前言
目前业界基于 Hadoop 技术栈的底层计算平台越发稳定成熟,计算能力不再成为主要瓶颈。 多样化的数据、复杂的业务分析
需求、系统稳定性、数据可靠性, 这些软性要求, 逐渐成为日志分析系统面对的主要问题。2018 年线上线下融合已成大势,
苏宁易购提出并践行双线融合模式,提出了智慧零售的大战略,其本质是数据驱动,为消费者提供更好的服务, 苏宁日志分
析系统作为数据分析的第一环节,为数据运营打下了坚实基础。
数据分析流程与架构介绍
业务背景
苏宁线上、线下运营人员,对数据分析需求多样化、时效性要求越来越高。目前实时日志分析系统每天处理数十亿条流量日
志,不仅需要保证:低延迟、数据不丢失等要求,还要面对复杂的分析计算逻辑,这些都给系统建设提出了高标准、高要求。
如下图所示:
数据来源丰富:线上线下流量数据、销售数据、客服数据等
业务需求多样: 支撑营销、采购、财务、供应链商户等数据需求
更多干货内容请关注微信公众号更多干货内容请关注微信公众号“AI 前线前线”,(,(ID::ai-front))
流程与架构
苏宁实时日志分析系统底层数据处理分为三个环节:采集、清洗、指标计算,如图 1 所示。
采集模块:收集各数据源日志,通过 Flume 实时发送 Kafka。
清洗模块:实时接收日志数据,进行数据处理、转换,清洗任务基于 Storm 实现,目前每天处理十亿级别流量数据,经
过清洗任务处理后的结构化数据将再次发送到 Kafka 队列
指标计算:从 Kafka 实时接收结构化流量数据,实时计算相关指标, 指标计算任务主要分两种:Storm 任务、Spark
Streaming 任务,两种方式都有各自的应用场景, 其中 Spark Streaming 适合准实时场景,其优点是:吞吐量高、支持
标准 SQL、开发简单、支持窗函数计算Storm、Spark 得益于苏宁数据云平台提供的支撑,目前苏宁数据云平台集成
了:Hive、Spark、Storm、Druid、ES、Hbase、Kafka 等大数据开发组件,支撑了集团大数据计算、存储需求。
指标计算后数据主要存储到 HBase、Druid 等存储引擎,业务系统读取实时计算好的指标数据,为运营人员提供数据分析服
务。
Spark Streaming 在指标分析实践
Spark Streaming 介绍
下载后可阅读完整内容,剩余4页未读,立即下载
2017-04-14 上传
点击了解资源详情
2019-01-20 上传
2021-10-14 上传
2021-09-10 上传
2022-06-18 上传
2021-10-24 上传
2021-09-16 上传
2010-02-02 上传

weixin_38618315
- 粉丝: 1
- 资源: 920
 我的内容管理
展开
我的内容管理
展开







最新资源
- cake-php-source:在2007-2008年期间使用CakePHP框架定制开发的Ponniyin Selvan网站的初始版本-Source website php
- C#-Leetcode编程题解之第20题有效的括号.zip
- prometheus-json_exporter-config-files-for-oracle-ic:一个Prometheus-communityjson_exporter配置文件,以Prometheus文本协议格式从Oracle Integration Cloud REST API导出指标
- sphinx_adc_theme:苹果开发人员连接的狮身人面像外观主题
- odin-calculator:TheOdinProject的作业
- FoodSafetyApplication
- matlab中的频谱图代码-dereverberate:GilbertSoulodre实现的声音去混响算法
- PTT-API-解决方案:使用ptt api解决方案的最终用户手册
- genetic_1,c语言编写的计时器源码,c语言
- angular-simple-chat:AngularJS聊天指令
- RobotArm:基于STM32芯片的简易机械臂
- 精选_基于JSP实现的校园师生交流系统_源码打包
- esencial_html_y_css:proyecto creado对边的thml和scss
- Deobfusctor:用于阅读大片提交的 unobfuscator 功能。-matlab开发
- MB91520_Series_32-bit_FR81S_Microcontr,车型识别算法源码c语言,c语言
- 机器学习:머신러닝공부내용저장저장
