优化Spark应用:GC调优实战与内存管理策略
102 浏览量
更新于2024-08-27
收藏 769KB PDF 举报
GC调优在Spark应用中的实践是大数据计算框架Spark中不可或缺的一部分。Spark作为内存计算的基石,处理海量数据时需要频繁在内存中存储和操作数据,这就对JVM的垃圾回收机制(Garbage Collection, GC)提出了高要求。由于Spark同时支持批处理和流式处理,对程序的吞吐量和延迟敏感,优化GC参数对于提高整体性能至关重要。
Spark的性能优势吸引了工业界的广泛关注,其独特的架构和丰富的分析计算库使得它在大数据处理领域脱颖而出。然而,随着Spark应用的广泛部署,垃圾回收带来的问题,如长时间的GC暂停、程序响应延迟乃至系统崩溃,成为了优化的重点。为了解决这些问题,开发人员需要理解并熟练掌握不同类型的垃圾收集器,如ParallelGC(注重吞吐量)和CMS GC(注重低延迟)的选择原则。
在实际应用中,选择哪种GC策略取决于特定场景的需求。对于需要实时响应的流式计算任务,CMS GC可能更为合适;而对于离线批处理任务,吞吐量优先的Parallel GC可能是更好的选择。然而,Spark作为一个多功能的计算框架,是否能找到一种通用的GC配置策略来平衡两者,是许多开发者探索的问题。
在企业级实践中,CMS GC(Concurrent Mark Sweep GC)因其在长时间运行任务中的稳定性和较低的暂停时间,往往被选为默认或首选的垃圾回收器。然而,具体配置还需要根据Spark应用的具体情况,如数据规模、任务类型、硬件资源等因素进行调整。
在进行GC调优时,除了选择适当的垃圾收集器,还需要关注其他关键参数,如堆大小(Heap Size)、新生代和老年代的大小分配、并发收集器的数量等。通过监控和调整这些参数,可以最大化利用内存资源,减少GC对性能的影响,从而提升Spark应用的整体效率和稳定性。
GC调优是Spark应用优化的重要环节,深入理解GC机制,合理配置垃圾收集器,是确保Spark在大数据处理中发挥最佳性能的关键。在实际操作中,需要根据具体业务场景灵活选择和调整,才能实现高效、稳定的Spark应用程序。
GC调优在调优在Spark应用中的实践应用中的实践
摘要:Spark立足内存计算,常常需要在内存中存放大量数据,因此也更依赖JVM的垃圾回收机制。与此同时,它也兼容批处
理和流式处理,对于程序吞吐量和延迟都有较高要求,因此GC参数的调优在Spark应用实践中显得尤为重要。
Spark是时下非常热门的大数据计算框架,以其卓越的性能优势、独特的架构、易用的用户接口和丰富的分析计算库,正在工
业界获得越来越广泛的应用。与Hadoop、HBase生态圈的众多项目一样,Spark的运行离不开JVM的支持。由于Spark立足于
内存计算,常常需要在内存中存放大量数据,因此也更依赖JVM的垃圾回收机制(GC)。并且同时,它也支持兼容批处理和
流式处理,对于程序吞吐量和延迟都有较高要求,因此GC参数的调优在Spark应用实践中显得尤为重要。本文主要讲述如何
针对Spark应用程序配置JVM的垃圾回收器,并从实际案例出发,剖析如何进行GC调优,进一步提升Spark应用的性能。
问题介绍
随着Spark在工业界得到广泛使用,Spark应用稳定性以及性能调优问题不可避免地引起了用户的关注。由于Spark的特色在于
内存计算,我们在部署Spark集群时,动辄使用超过100GB的内存作为Heap空间,这在传统的Java应用中是比较少见的。在
广泛的合作过程中,确实有很多用户向我们抱怨运行Spark应用时GC所带来的各种问题。例如垃圾回收时间久、程序长时间
无响应,甚至造成程序崩溃或者作业失败。对此,我们该怎样调试Spark应用的垃圾收集器呢?在本文中,我们从应用实例出
发,结合具体问题场景,探讨了Spark应用的GC调优方法。
按照经验来说,当我们配置垃圾收集器时,主要有两种策略——Parallel GC和CMS GC。前者注重更高的吞吐量,而后者则
注重更低的延迟。两者似乎是鱼和熊掌,不能兼得。在实际应用中,我们只能根据应用对性能瓶颈的侧重性,来选取合适的垃
圾收集器。例如,当我们运行需要有实时响应的场景的应用时,我们一般选用CMS GC,而运行一些离线分析程序时,则选用
Parallel GC。那么对于Spark这种既支持流式计算,又支持传统的批处理运算的计算框架来说,是否存在一组通用的配置选项
呢?
通常CMS GC是企业比较常用的GC配置方案,并在长期实践中取得了比较好的效果。例如对于进程中若存在大量寿命较长的
对象,Parallel GC经常带来较大的性能下降。因此,即使是批处理的程序也能从CMS GC中获益。不过,在从1.6开始的
HOTSPOT JVM中,我们发现了一个新的GC设置项:Garbage-First GC(G1 GC)。Oracle将其定位为CMS GC的长期演进,
这让我们重燃了鱼与熊掌兼得的希望!那么,我们首先了解一下GC的一些相关原理吧。
GC算法原理
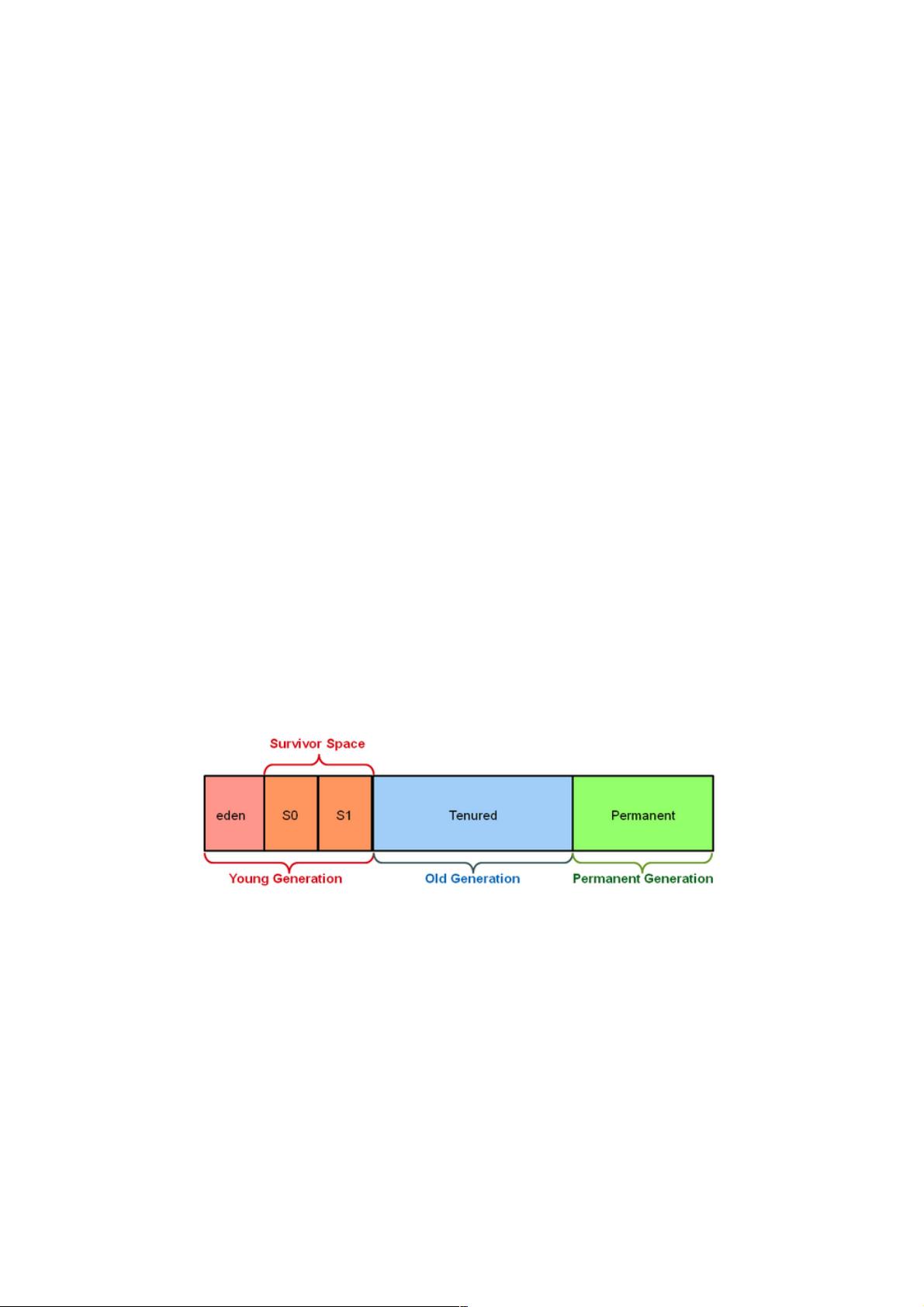
在传统JVM内存管理中,我们把Heap空间分为Young/Old两个分区,Young分区又包括一个Eden和两个Survivor分区,如图1
所示。新产生的对象首先会被存放在Eden区,而每次minor GC发生时,JVM一方面将Eden分区内存活的对象拷贝到一个空的
Survivor分区,另一方面将另一个正在被使用的Survivor分区中的存活对象也拷贝到空的Survivor分区内。在此过程中,JVM
始终保持一个Survivor分区处于全空的状态。一个对象在两个Survivor之间的拷贝到一定次数后,如果还是存活的,就将其拷
入Old分区。当Old分区没有足够空间时,GC会停下所有程序线程,进行Full GC,即对Old区中的对象进行整理。这个所有线
程都暂停的阶段被称为Stop-The-World(STW),也是大多数GC算法中对性能影响最大的部分。
图 1 分年代的Heap结构
而G1 GC则完全改变了这一传统思路。它将整个Heap分为若干个预先设定的小区域块(如图2),每个区域块内部不再进行新
旧分区, 而是将整个区域块标记为Eden/Survivor/Old。当创建新对象时,它首先被存放到某一个可用区块(Region)中。当
该区块满了,JVM就会创建新的区块存放对象。当发生minor GC时,JVM将一个或几个区块中存活的对象拷贝到一个新的区
块中,并在空余的空间中选择几个全新区块作为新的Eden分区。当所有区域中都有存活对象,找不到全空区块时,才发生Full
GC。而在标记存活对象时,G1使用RememberSet的概念,将每个分区外指向分区内的引用记录在该分区的RememberSet
中,避免了对整个Heap的扫描,使得各个分区的GC更加独立。在这样的背景下,我们可以看出G1 GC大大提高了触发Full
GC时的Heap占用率,同时也使得Minor GC的暂停时间更加可控,对于内存较大的环境非常友好。这些颠覆性的改变,将给
GC性能带来怎样的变化呢?最简单的方式,我们可以将老的GC设置直接迁移为G1 GC,然后观察性能变化。
下载后可阅读完整内容,剩余7页未读,立即下载
2018-12-01 上传
2018-12-10 上传
点击了解资源详情
2018-11-18 上传
2024-07-18 上传
2018-05-22 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38708223
- 粉丝: 5
- 资源: 915
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
