Spark on Yarn模式部署指南
需积分: 45 181 浏览量
更新于2024-08-05
收藏 1.17MB DOCX 举报
"Spark on Yarn模式部署文档详细介绍了如何在Hadoop集群中配置和运行Spark。文档涵盖了从基础环境设置到Spark配置的所有关键步骤,旨在确保Spark作业可以在YARN资源管理器的协调下顺利执行。"
在分布式计算环境中,Spark on Yarn模式允许Spark应用程序利用Hadoop的YARN (Yet Another Resource Negotiator) 来管理和调度资源,提供了一个统一的管理和监控平台。以下是按照文档中的步骤详细解释每个环节:
1. **修改主机名和IP地址映射**:
这是集群环境的基本配置,确保节点间可以正确通信。在Ubuntu系统中,编辑`/etc/hostname`来设置主机名,然后在`/etc/hosts`中添加主机名与IP地址的对应关系,确保网络连通性。
2. **配置免密码登录**:
使用SSH密钥对实现主机间的无密码登录,提高管理效率。在master节点生成公钥并将其复制到其他节点的authorized_keys文件中,确保master节点能无密码访问所有节点,反之亦然。
3. **安装和配置JDK8**:
JDK是运行Spark所必需的,因为Spark是用Java编写的。从Oracle官网下载JDK8的Linux版本,通过SCP传输到master节点,解压缩后将其路径添加到系统环境变量`JAVA_HOME`,同时更新`JRE_HOME`、`CLASSPATH`和`PATH`。通过`java -version`命令验证安装成功。
4. **配置Hadoop**:
要在YARN上运行Spark,需要确保Hadoop已经正确配置并启动。这包括设置Hadoop的相关环境变量,如`HADOOP_CONF_DIR`,以及启动HDFS和YARN服务。
5. **配置Spark**:
Spark的配置文件通常位于`conf`目录下,主要涉及`spark-defaults.conf`和`spark-env.sh`。在`spark-defaults.conf`中设置Spark应用的全局属性,如内存分配、日志级别等。而在`spark-env.sh`中,配置与Hadoop相关的环境变量,如`HADOOP_CONF_DIR`,以及Spark的工作模式(此处为`yarn-client`或`yarn-cluster`)。
6. **启动和测试Spark on Yarn**:
在完成以上步骤后,启动Spark的YARN客户端,提交一个简单的Spark作业,如WordCount,以验证Spark是否能在YARN上正确运行。在YARN的ResourceManager界面上,可以观察作业的进度和资源使用情况。
通过这些步骤,你可以成功地在Hadoop YARN环境中部署Spark,使其能够充分利用集群资源,高效执行大数据处理任务。务必注意,每个步骤都需要仔细执行,确保配置正确无误,以避免后续可能出现的问题。
Spark on Yarn 模式部署
部署步骤:
一、修改主机名,添加主机名到 地址映射。
二、配置免密码登录
三、安装并配置
四、配置
五、配置
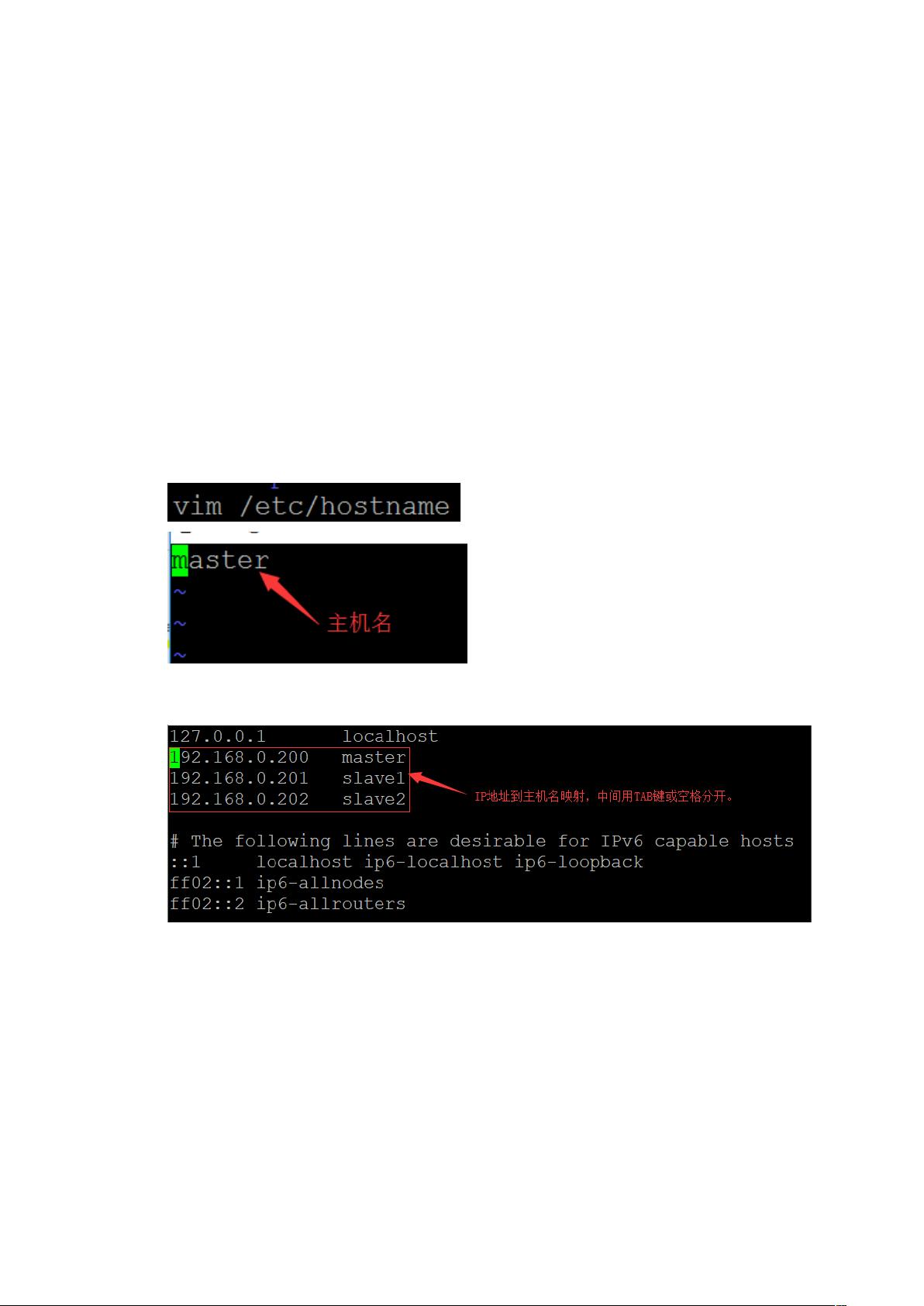
一、 修改主机名,添加主机名到 地址映射
新建三台 虚拟机,并安装好 !" 系统。
# 编辑$%$&' ,修改虚拟机名,将 三台 虚 拟 机名分别 改 为 ' 、 ( 和
(#,' 主机名修改如下图,( 和 (# 主机名修改类似。
编辑$%$&,在三台虚拟机上分别添加 地址到主机名映射,如下图,注意把 地
址改为虚拟机实际地址。
重启 '、( 和 (#。
二、配置免密码登录
配置 ' 免密码登录 '、( 和 (#,配置过程参见之前的实验文档。
注意:必须配置 ' 免密码登录 ' 自身,即 &'无需输入密码。
注意:以下操作步骤若无特别说明,均在 master 上进行。
三、安装并配置
到 )%( 网 站 ( &*+$$,,,%(%'$%&,$-$-$,($-.
,(.# /&'()下载 JDK8(注意下载 -.#.(01.123 版本),把
下载后可阅读完整内容,剩余9页未读,立即下载
2022-08-03 上传
2020-06-15 上传
2020-02-24 上传
2021-12-07 上传
2020-04-03 上传
2021-11-20 上传
2020-09-17 上传
2022-12-24 上传

一枚菜鸟~
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源通讯录备份系统项目,易于复刻与扩展
- 探索NX二次开发:UF_DRF_ask_id_symbol_geometry函数详解
- Vuex使用教程:详细资料包解析与实践
- 汉印A300蓝牙打印机安卓App开发教程与资源
- kkFileView 4.4.0-beta版:Windows下的解压缩文件预览器
- ChatGPT对战Bard:一场AI的深度测评与比较
- 稳定版MySQL连接Java的驱动包MySQL Connector/J 5.1.38发布
- Zabbix监控系统离线安装包下载指南
- JavaScript Promise代码解析与应用
- 基于JAVA和SQL的离散数学题库管理系统开发与应用
- 竞赛项目申报系统:SpringBoot与Vue.js结合毕业设计
- JAVA+SQL打造离散数学题库管理系统:源代码与文档全览
- C#代码实现装箱与转换的详细解析
- 利用ChatGPT深入了解行业的快速方法论
- C语言链表操作实战解析与代码示例
- 大学生选修选课系统设计与实现:源码及数据库架构
