Apache Spark 2入门:大数据处理与机器学习
需积分: 9 170 浏览量
更新于2024-07-18
收藏 5.56MB PDF 举报
" Beginning Apache Spark 2 大数据:这本书详细介绍了如何使用Apache Spark 2进行大数据应用程序的开发,包括利用Hadoop和云技术。书中涵盖了Resilient Distributed Datasets (RDD)、Spark SQL、Structured Streaming以及Spark Machine Learning库的基础知识和应用实践。作者Hien Luu通过本书引导读者深入理解Spark的原理和功能。"
Apache Spark 2是大数据处理领域的关键工具,以其高效、易用和灵活性著称。这本书主要分为几个核心部分,深入浅出地讲解了以下几个关键知识点:
1. **Resilient Distributed Datasets (RDD)**: RDD是Spark的基本数据抽象,它是不可变的、分区的记录集合,可以在集群中并行操作。RDD提供了容错机制,即使在节点故障时也能恢复数据,确保计算的可靠性。通过RDD,开发者可以编写高效的分布式数据处理程序。
2. **Spark SQL**: Spark SQL是Spark的一个模块,它允许用户使用SQL或DataFrame API来查询数据。DataFrame API提供了一种统一的方式来处理结构化和半结构化数据,可以与多种数据源(如Hive、Parquet、JSON等)集成。Spark SQL的出现使得Spark更易于与现有的SQL系统集成,提高了开发者的生产力。
3. **Structured Streaming**: Structured Streaming是Spark 2引入的流处理框架,它扩展了Spark SQL的概念,允许开发者以类似批处理的方式处理连续的数据流。Structured Streaming提供了强大的容错性和精确一次的状态一致性保证,使得实时数据分析变得更加简单和可靠。
4. **Spark Machine Learning Library (MLlib)**: MLlib是Spark的机器学习库,提供了各种机器学习算法和实用工具,包括分类、回归、聚类、协同过滤等。MLlib支持管道和模型选择,有助于简化机器学习工作流程,同时提供了跨语言的API,方便不同背景的开发者使用。
5. **Spark与Hadoop的结合**:Spark可以与Hadoop生态系统紧密集成,充分利用HDFS作为数据存储,MapReduce作为任务调度。这使得开发者能够利用Spark的快速处理能力来处理Hadoop集群中的大数据集。
6. **云计算集成**:Spark也支持在云环境中运行,如Amazon Web Services (AWS)、Microsoft Azure等,这使得开发者能够轻松扩展计算资源,应对不断增长的数据量和复杂度。
本书不仅覆盖了理论概念,还包括实际操作示例,帮助读者理解和应用这些技术。无论是初学者还是经验丰富的开发者,都能从中受益,提升在大数据领域的技能和实践能力。通过深入学习和实践,读者将能够利用Spark 2构建高性能、可扩展的大数据解决方案。
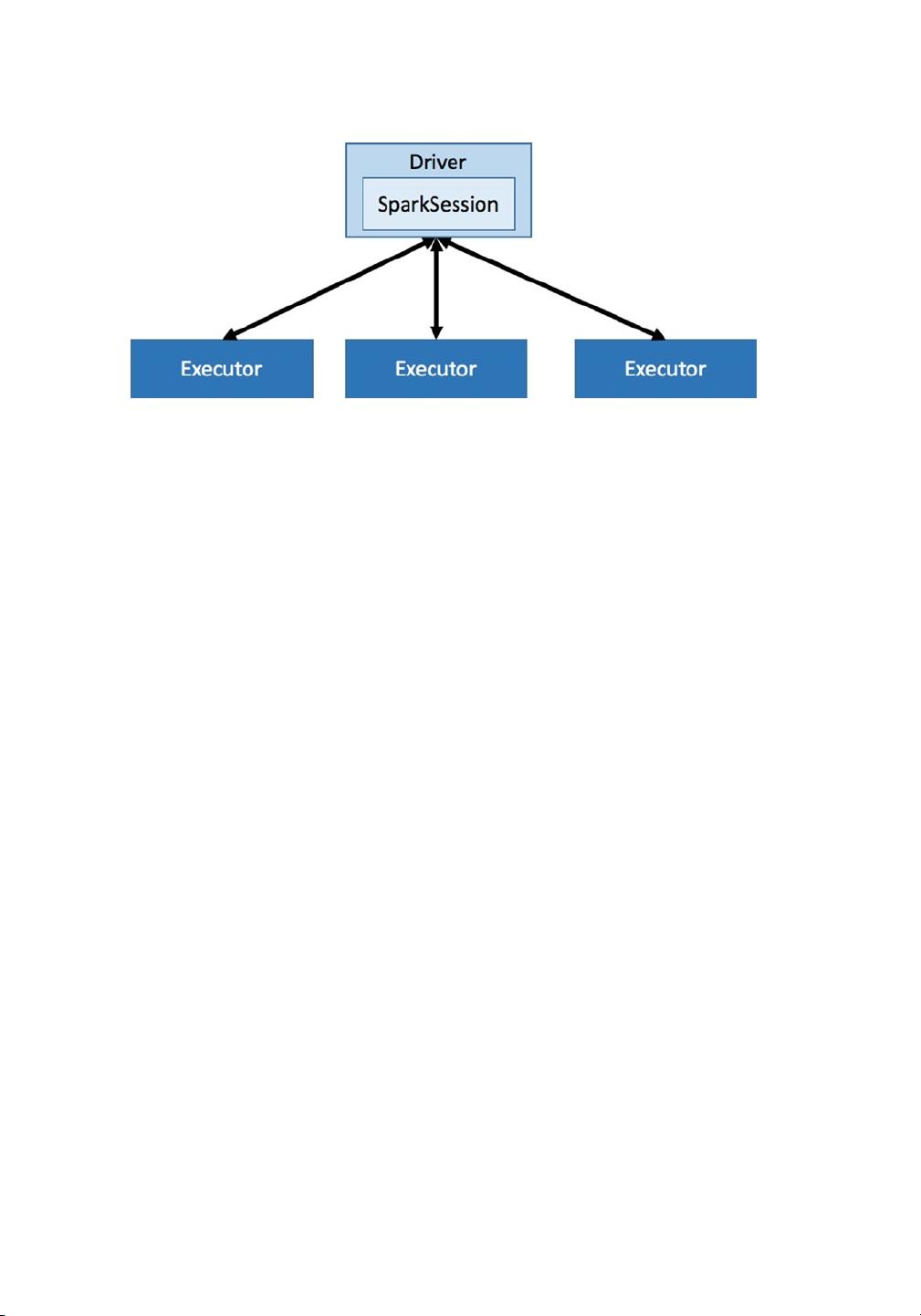
6
At the time of launching a Spark application, you can request how many Spark
executors an application needs and how much memory and the number of CPU cores
each executor should have. Figuring out an appropriate number of Spark executors,
the amount of memory, and the number of CPU requires some understanding of the
amount of data that will be processed, the complexity of the data processing logic, and
the desired duration by which a Spark application should complete the processing logic.
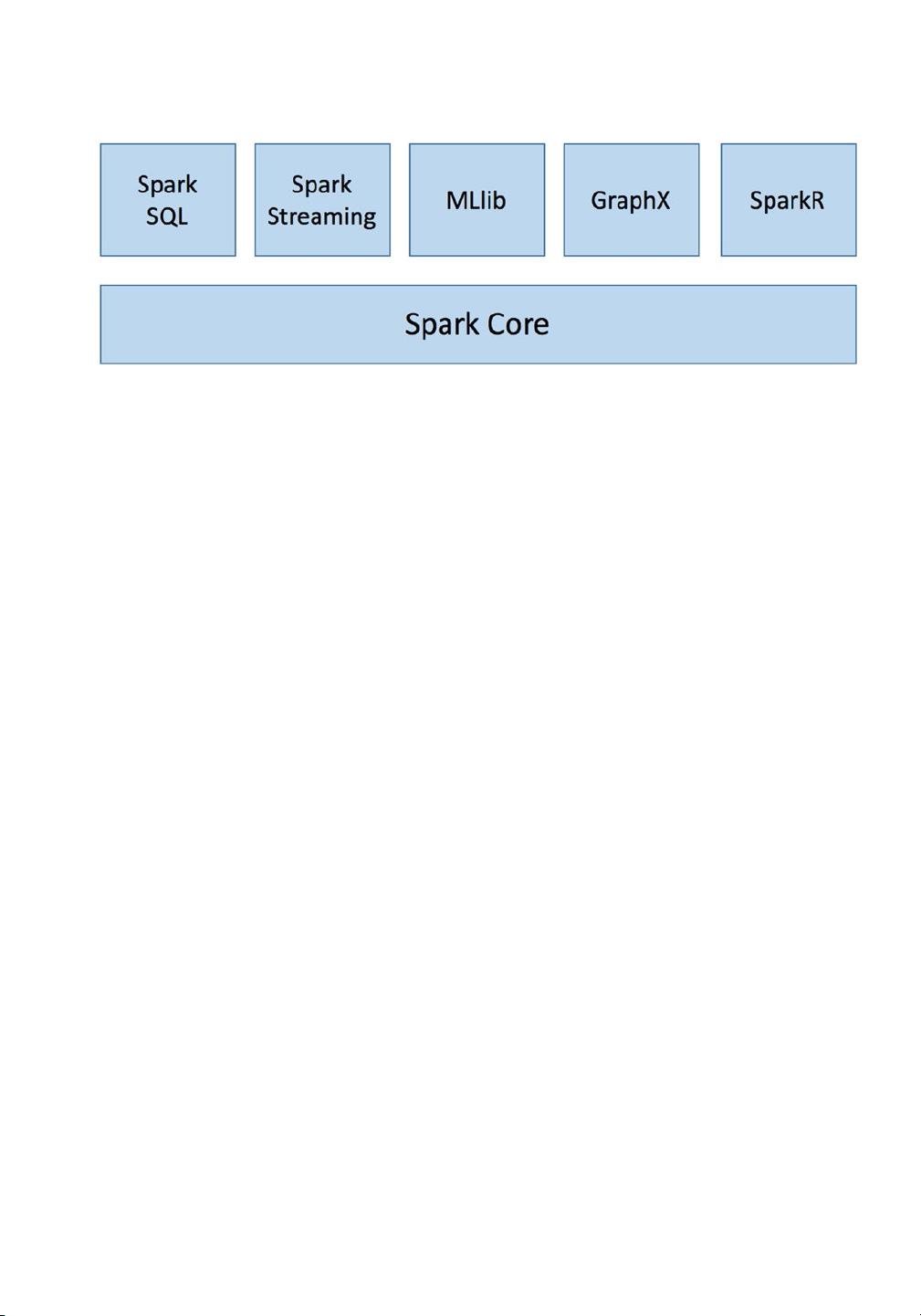
Spark Unified Stack
Unlike its predecessors, Spark provides a unified data processing engine known as the
Spark stack. Similar to other well-designed systems, this stack is built on top of a strong
foundation called Spark Core, which provides all the necessary functionalities to manage
and run distributed applications such as scheduling, coordination, and fault tolerance.
In addition, it provides a powerful and generic programming abstraction for data
processing called resilient distributed datasets (RDDs). On top of this strong foundation
is a collection of components where each one is designed for a specific data processing
workload, as shown in Figure1-3. Spark SQL is for batch as well as interactive data
processing. Spark Streaming is for real-time stream data processing. Spark GraphX is for
graph processing. Spark MLlib is for machine learning. Spark R is for running machine
learning tasks using the R shell.
Figure 1-2. A small Spark cluster with three executors
Chapter 1 IntroduCtIon toapaChe Spark



剩余397页未读,继续阅读
110 浏览量
175 浏览量
2024-01-04 上传
217 浏览量
点击了解资源详情
110 浏览量
199 浏览量
点击了解资源详情

dusong7
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Subclipse 1.8.2版:Eclipse IDE的Subversion插件下载
- Spring框架整合SpringMVC与Hibernate源码分享
- 掌握Excel编程与数据库连接的高级技巧
- Ubuntu实用脚本合集:提升系统管理效率
- RxJava封装OkHttp网络请求库的Android开发实践
- 《C语言精彩编程百例》:学习C语言必备的PDF书籍与源代码
- ASP MVC 3 实例:打造留言簿教程
- ENC28J60网络模块的spi接口编程及代码实现
- PHP实现搜索引擎技术详解
- 快速香草包装技术:速度更快的新突破
- Apk2Java V1.1: 全自动Android反编译及格式化工具
- Three.js基础与3D场景交互优化教程
- Windows7.0.29免安装Tomcat服务器快速部署指南
- NYPL表情符号机器人:基于Twitter的图像互动工具
- VB自动出题题库系统源码及多技术项目资源
- AndroidHttp网络开发工具包的使用与优势
