YOLO V3:多尺度预测与残差网络优化的实时目标检测
需积分: 0 175 浏览量
更新于2024-07-09
2
收藏 2.61MB PPTX 举报
YOLO V3是Joseph Redmon和Ali Farhadi在华盛顿大学进行的研究工作,针对目标检测领域提出的一项重要改进。这份PPTX文件旨在分享关于YOLOv3(You Only Look Once version 3)的深入理解,它是在YOLOv2基础上的一个重大迭代,专注于提高检测速度和精度。
首先,YOLOv3在多尺度预测方面做出了显著改进。它利用Darknet-53这一强大的残差网络结构,相比于SSD 321模型,不仅实现了约3倍的速度提升,而且在mAP精度上接近,AP50精度也优于RetinaNet,同时速度更快。为了实现这一目标,YOLOv3采用了C-B-L Res_Block结构,其中包含多个不同分辨率的检测卷积核,如13x13、26x26和52x52,分别对应不同的检测任务,小、中、大物体的检测能力得到了优化。
YOLOv3利用K-means聚类技术,设置9个聚类中心来生成不同形状的先验框,这些先验框根据大小分配给不同尺度的特征图。这使得网络能够更好地适应各种尺寸的目标检测。每个网格单元生成的先验框数量与目标物体的检测范围相关,小物体用3个,中等物体用3个,大物体同样用3个,以确保精确度和效率的平衡。
在特征提取部分,YOLOv3采用了Darknet-53,相较于YOLOv1的Darknet-19,具有更深的网络层次。残差网络的引入解决了深度网络中可能出现的梯度消失和梯度爆炸问题,使得YOLOv3能够更有效地学习深层特征。网络设计上,深层特征经过上采样放大尺寸并与浅层特征融合,确保了信息的高效传递。深层特征由于尺寸小,会经过2倍上采样;而浅层特征维度较大,则通过1x1卷积降低维度,以保持特征的维度匹配。
总结来说,YOLOv3通过优化的多尺度预测、残差网络结构以及特征融合策略,提升了目标检测的性能,实现了更高的精度和更快的速度,使其在实际应用中显示出极高的竞争力。这个PPTX文档提供了深入研究YOLOv3背后原理和技术细节的宝贵资料,对于理解和实践目标检测任务具有很高的参考价值。
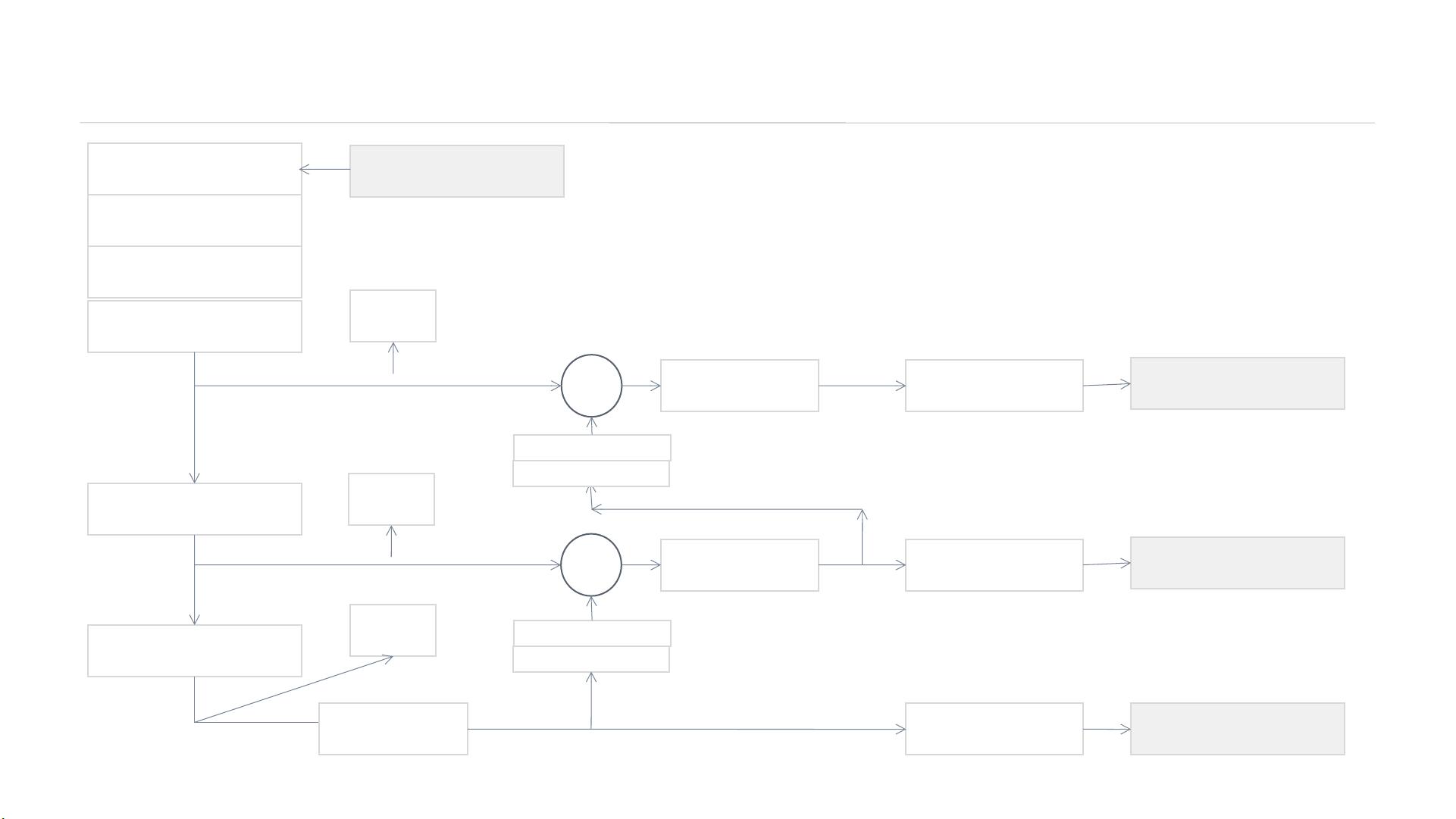
Improvement — 多尺度预测
4
C-B-L
Res_Block1
Res_Block2
Res_Block8
Res_Block8
Res_Block4
5 * C-B-L
检测卷积核 c Y3: 13*13*255
+
C-B-L
2 倍上采样
5 * C-B-L
检测卷积核 b
Y2: 26*26*255
C-B-L
2 倍上采样
+
5 * C-B-L
检测卷积核 a
Y1: 52*52*255
R1
R3
R2
Input: 416*416*3
剩余16页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-10-15 上传
155 浏览量
2023-12-11 上传
2024-11-26 上传
2024-11-26 上传









