深度3D卷积网络(C3D):学习时空特征
需积分: 16 138 浏览量
更新于2024-07-15
收藏 72.27MB PDF 举报
“C3D(Convolutional 3D)是一种使用3D卷积网络学习时空特征的方法,它在大规模有监督的视频数据集上进行训练。研究发现3D卷积网络比2D卷积网络更适合捕捉时空信息,最优的3D卷积网络架构是所有层都采用3×3×3的小卷积核。C3D特征通过简单的线性分类器学习得到,性能在多个基准测试中超越现有方法。”
本文介绍了一种基于3D卷积网络(3D ConvNets)学习时空特征的新方法,该方法对于视频理解和动作识别等领域具有重要意义。研究的核心在于对比2D和3D卷积网络在捕捉视频数据中的时空信息时的差异。作者发现,3D ConvNets在处理视频数据时,能更有效地捕获空间和时间上的连续变化,从而提供更为丰富的特征表示。
首先,作者指出3D ConvNets相较于2D ConvNets在时空特征学习上有显著优势。2D卷积网络主要设计用于处理静态图像,无法直接处理时间维度的信息。而3D卷积网络通过增加时间维度的滤波器,能够同时对空间和时间信息进行建模,更好地理解视频序列中的动态变化。
其次,他们发现使用3×3×3的小卷积核构建的同构架构是3D ConvNets中表现最佳的。小卷积核可以降低模型复杂度,减少计算量,同时保持较高的特征表达能力。这表明,尽管3D ConvNets增加了额外的时间维度,但通过适当的设计,仍能在保持高效的同时,获取强大的时空特征提取能力。
研究中提出的C3D特征是通过3D ConvNets训练后,结合简单的线性分类器得到的。这些特征在四个不同的基准测试(如UCF101)中超越了当前的最优方法,并在另外两个基准测试中表现与之相当。这表明C3D特征具有广泛的应用潜力,可以在多种视频理解任务中取得良好的性能。
此外,C3D特征还表现出紧凑性和高效性。在UCF101数据集上,仅使用10维的C3D特征就能达到52.8%的准确率,这展示了其高效的特征表示能力。由于3D ConvNets的快速推理特性,计算效率也非常高,使得C3D特征在实际应用中更具优势。
C3D(Convolutional 3D)通过3D卷积网络学习的时空特征不仅在性能上优于传统方法,而且在模型复杂度、计算效率和实用性方面都有显著优势。这种方法的提出,为视频分析和理解领域提供了新的思路和工具,有助于推动相关技术的进步。
0 2 4 6 8 10 12 14 16
0.2
0.25
0.3
0.35
0.4
0.45
0.5
# epoch
clip accuracy
depth−1
depth−3
depth−5
depth−7
0 2 4 6 8 10 12 14 16
0.3
0.32
0.34
0.36
0.38
0.4
0.42
0.44
0.46
# epoch
clip accuracy
depth−3
increase
descrease
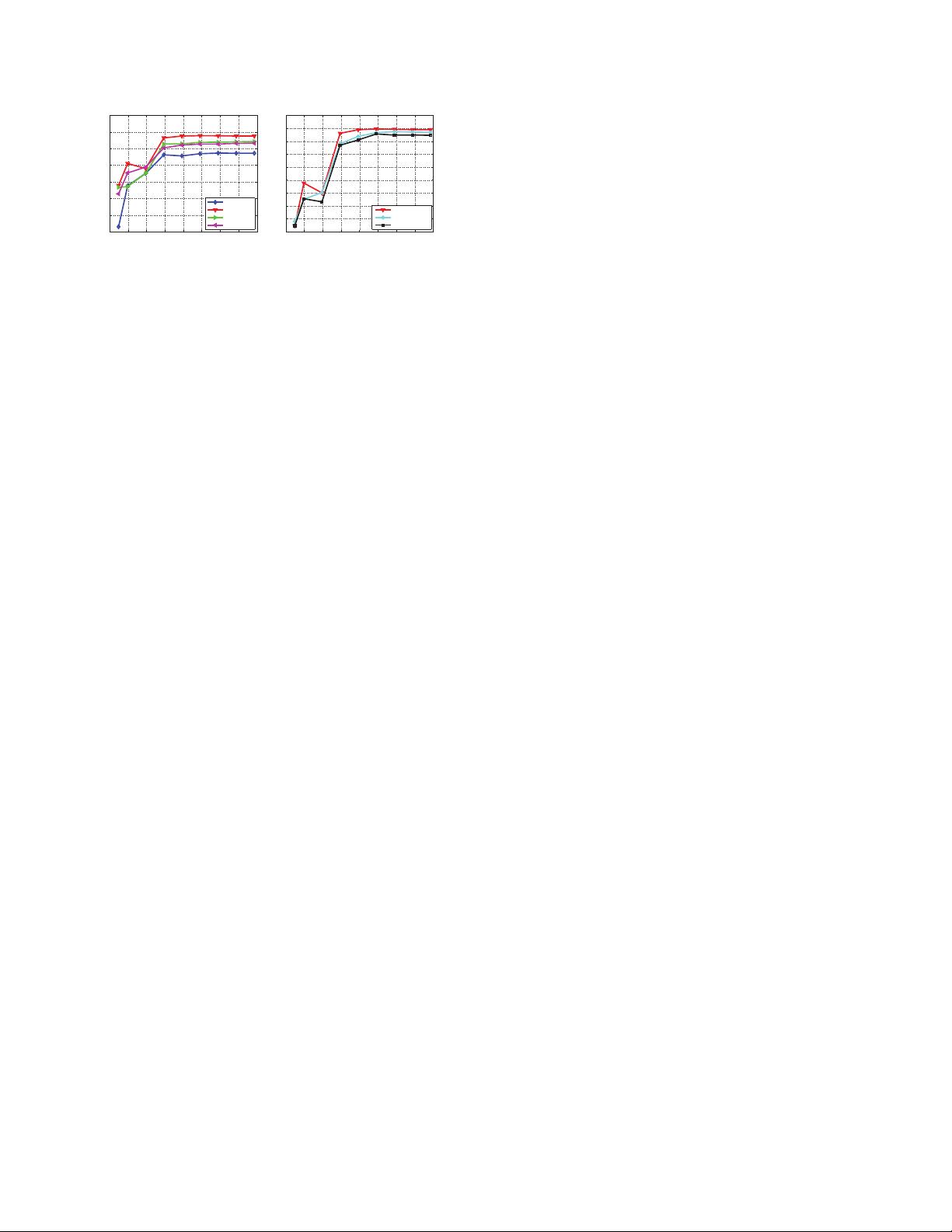
Figure 2. 3D convolution kernel temporal depth search. Action
recognition clip accuracy on UCF101 test split-1 of different ker-
nel temporal depth settings. 2D ConvNet performs worst and 3D
ConvNet with 3 × 3 × 3 kernels performs best among the experi-
mented nets.
17K parameters fewer or more from each other. The biggest
difference in number of parameters is between depth-1 net
and depth-7 net where depth-7 net has 51K more parame-
ters which is less than 0.3% of the total of 17.5 millions pa-
rameters of each network. This indicates that the learning
capacity of the networks are comparable and the differences
in number of parameters should not affect the results of our
architecture search.
3.2. Exploring kernel temporal depth
We train these networks on the train split 1 of UCF101.
Figure 2 presents clip accuracy of different architectures on
UCF101 test split 1. The left plot shows results of nets with
homogeneous temporal depth and the right plot presents re-
sults of nets that changing kernel temporal depth. Depth-
3 performs best among the homogeneous nets. Note that
depth-1 is significantly worse than the other nets which we
believe is due to lack of motion modeling. Compared to the
varying temporal depth nets, depth-3 is the best performer,
but the gap is smaller. We also experiment with bigger spa-
tial receptive field (e.g. 5 × 5) and/or full input resolution
(240 × 320 frame inputs) and still observe similar behav-
ior. This suggests 3 × 3 × 3 is the best kernel choice for
3D ConvNets (according to our subset of experiments) and
3D ConvNets are consistently better than 2D ConvNets for
video classification. We also verify that 3D ConvNet con-
sistently performs better than 2D ConvNet on a large-scale
internal dataset, namely I380K.
3.3. Spatiotemporal feature learning
Network architecture: Our findings in the previous sec-
tion indicate that homogeneous setting with convolution
kernels of 3 × 3 × 3 is the best option for 3D ConvNets.
This finding is also consistent with a similar finding in 2D
ConvNets [37]. With a large-scale dataset, one can train a
3D ConvNet with 3×3×3 kernel as deep as possible subject
to the machine memory limit and computation affordability.
With current GPU memory, we design our 3D ConvNet to
have 8 convolution layers, 5 pooling layers, followed by two
fully connected layers, and a softmax output layer. The net-
work architecture is presented in figure 3. For simplicity,
we call this net C3D from now on. All of 3D convolution
filters are 3 × 3 × 3 with stride 1 × 1 × 1. All 3D pooling
layers are 2 × 2 × 2 with stride 2 × 2 × 2 except for pool1
which has kernel size of 1 × 2 × 2 and stride 1 × 2 × 2
with the intention of preserving the temporal information in
the early phase. Each fully connected layer has 4096 output
units.
Dataset. To learn spatiotemproal features, we train
our C3D on Sports-1M dataset [18] which is currently the
largest video classification benchmark. The dataset consists
of 1.1 million sports videos. Each video belongs to one
of 487 sports categories. Compared with UCF101, Sports-
1M has 5 times the number of categories and 100 times the
number of videos.
Training: Training is done on the Sports-1M train split.
As Sports-1M has many long videos, we randomly extract
five 2-second long clips from every training video. Clips are
resized to have a frame size of 128 × 171. On training, we
randomly crop input clips into 16× 112× 112 crops for spa-
tial and temporal jittering. We also horizontally flip them
with 50% probability. Training is done by SGD with mini-
batch size of 30 examples. Initial learning rate is 0.003,
and is divided by 2 every 150K iterations. The optimization
is stopped at 1.9M iterations (about 13 epochs). Beside the
C3D net trained from scratch, we also experiment with C3D
net fine-tuned from the model pre-trained on I380K.
Sports-1M classification results: Table 2 presents
the results of our C3D networks compared with Deep-
Video [18] and Convolution pooling [29]. We use only a
single center crop per clip, and pass it through the network
to make the clip prediction. For video predictions, we av-
erage clip predictions of 10 clips which are randomly ex-
tracted from the video. It is worth noting some setting dif-
ferences between the comparing methods. DeepVideo and
C3D use short clips while Convolution pooling [29] uses
much longer clips. DeepVideo uses more crops: 4 crops per
clip and 80 crops per video compared with 1 and 10 used by
C3D, respectively. The C3D network trained from scratch
yields an accuracy of 84.4% and the one fine-tuned from
the I380K pre-trained model yields 85.5% at video top-
5 accuracy. Both C3D networks outperform DeepVideo’s
networks. C3D is still 5.6% below the method of [29].
However, this method uses convolution pooling of deep
image features on long clips of 120 frames, thus it is not
directly comparable to C3D and DeepVideo which oper-
ate on much shorter clips. We note that the difference in
top-1 accuracy for clips and videos of this method is small
(1.6%) as it already uses 120-frame clips as inputs. In prac-
tice, convolution pooling or more sophisticated aggregation
schemes [29] can be applied on top of C3D features to im-
prove video hit performance.
C3D video descriptor: After training, C3D can be used
as a feature extractor for other video analysis tasks. To
剩余15页未读,继续阅读
2021-10-18 上传
2022-12-04 上传
2019-11-15 上传
2021-08-08 上传
2021-09-29 上传
2019-02-17 上传
2023-04-22 上传

普通网友
- 粉丝: 1w+
- 资源: 81
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
