使用Smart3D生成倾斜数据正射影像与DSM教程
版权申诉
138 浏览量
更新于2024-06-20
收藏 1.09MB PDF 举报
"Smart3D系列教程6详细介绍了如何利用倾斜数据生成正射影像和DSM,以及如何使用ArcGIS进行影像拼接。教程适用于已掌握基础照片三维重建技术的用户,通过Smart3D软件处理垂直拍摄的多角度、重叠度适中的像片,生成的成果包括Orthophoto和DSM,最终通过ArcGIS完成镶嵌和拼接工作。教程内容分为前言、工具材料、方法步骤和小结四个部分,旨在提升用户在三维建模和地理信息处理方面的能力。"
在本教程中,首先强调了Smart3D软件不仅能生成三维模型,还能进一步生产正射影像图和数字表面模型(DSM)。正射影像图提供了一种无透视失真的鸟瞰视图,而DSM则记录了地表所有物体的海拔信息,两者在地理信息系统(GIS)中有着广泛应用。生成这些成果的关键在于先创建三维模型,再基于模型生成正射影像和DSM。
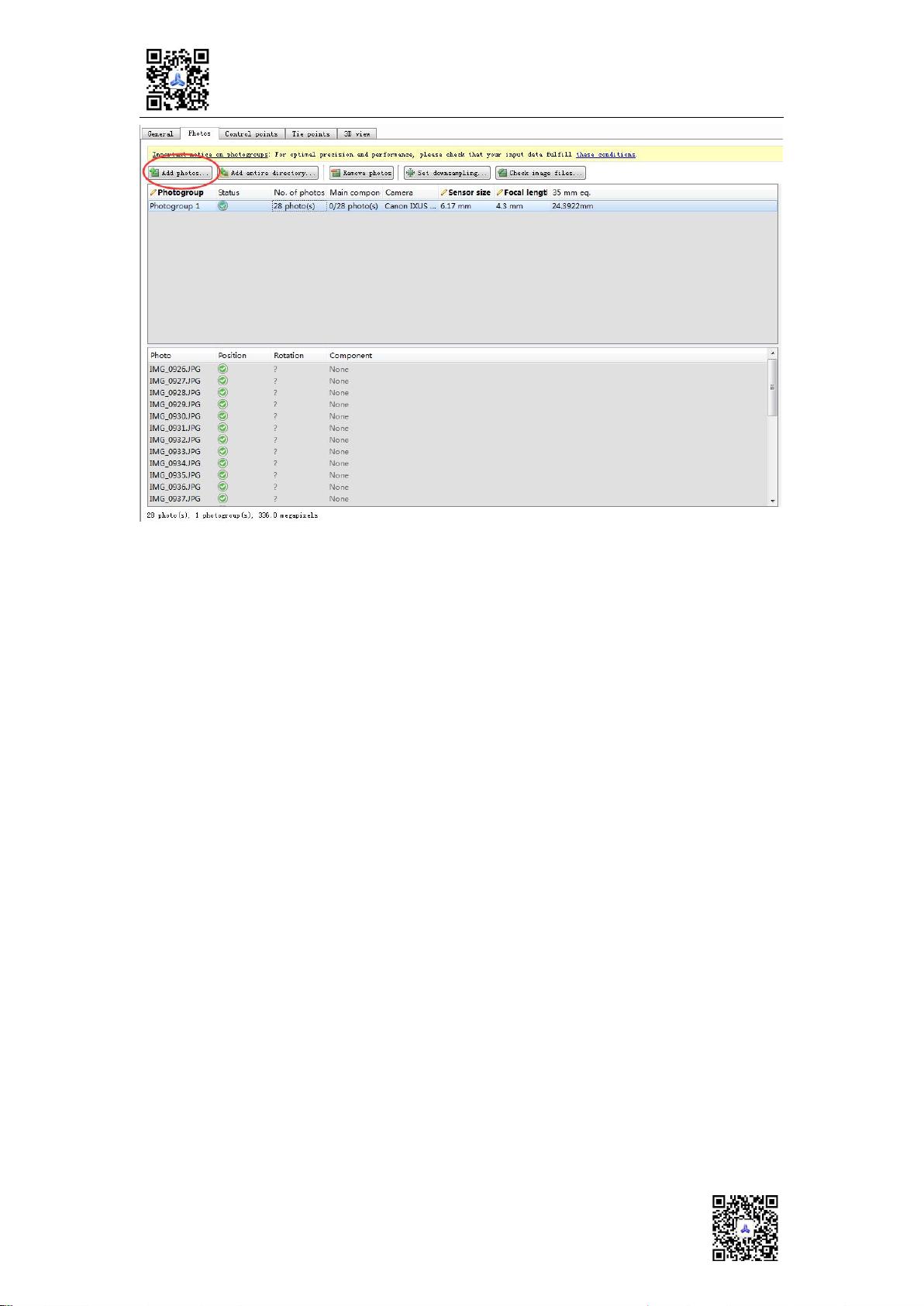
生成模型的步骤包括导入照片、检查照片质量和在3Dview中确认照片分布。导入照片时,确保使用一组满足重建要求的垂直拍摄且多角度重叠的像片。在3Dview中检查照片分布,确保照片覆盖全面且无明显缺失。
生成正射影像图和DSM后,由于生成的成果通常会分块,因此需要使用GIS软件进行拼接。教程推荐使用ArcGIS 10.1,利用其镶嵌功能将分块的正射影像图和DSM合并为一个连续的地理信息产品。这一步骤对于集成和分析大面积的地理信息至关重要。
教程最后的小结部分总结了整个流程,强调了Smart3D与ArcGIS结合使用的高效性和实用性。通过这个系列教程的学习,用户不仅能够掌握Smart3D的基本操作,还能了解如何将生成的三维模型成果转化为更便于分析和展示的正射影像和DSM,从而增强其在地理信息领域的实践能力。
www.Wish3D.com 版权所有,禁止转载
Smart3D QQ 交流群:516635556 微信公众号:
别忘记检查一下照片:
剩余14页未读,继续阅读
2023-10-21 上传
2021-10-06 上传
2023-10-21 上传
2023-11-15 上传
2023-08-29 上传
2023-06-22 上传
2023-10-30 上传
2023-03-25 上传
2023-05-28 上传

普通网友
- 粉丝: 1264
- 资源: 5619
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
