微型 RTS 第四次实验报告:QLearning 改进与优化的探讨
需积分: 0 194 浏览量
更新于2024-03-22
收藏 1.46MB DOCX 举报
MicroRts 第四次实验报告
前言:在最后几周的工作中,我们针对上一次实验中提出的问题进行了深入的优化和改进。首先,我们对Qlearning的核心reward函数进行了重新设计,重新定义reward的获取方式,以提高AI的学习效率和表现。其次,我们调整了学习和决策的时间间隔,并完善了基础AI,以优化整体的游戏体验。尽管新版AI还未经过充分训练和Q矩阵未收敛,暂时无法打败旧版AI,但我们在本次实验报告中将详细介绍我们对QLearning算法的改进,并给出部分实验结果的分析。
PART I 对 QLearning 的改进
一、改进了reward的获取方式
正如我们在第三次实验报告中所提到的,Qlearning算法的核心在于reward的获取。事实上,reward也是强化学习算法的主要特征,而我们之前的AI存在的主要问题之一就是reward获取方式过于僵化和不够合理。因此,新版AI的核心优化方向之一即是对reward的获取方式进行改进。我们的改进思路如下:
首先,我们参考了QLearning算法的相关文献和研究成果,借鉴了一些优秀的reward获取方式。在此基础上,我们重新设计了AI的reward机制,使其更加灵活和智能化。通过引入更多的游戏状态和动态信息,我们实现了对reward的实时分析和动态调整,以更加准确地反映AI在游戏中的操作效果和表现。
其次,我们结合了实际游戏场景和AI的运行逻辑,优化了reward的计算方式。我们考虑到游戏中的各种因素和变量,如资源获取、单位建造、敌军进攻等,通过合理设定reward的权重和计算方式,使AI能够更加全面地评估游戏局势和自身行动,从而做出更加明智的决策和策略。
最后,我们对新的reward获取方式进行了实际测试和验证,并与旧版AI进行了对比实验。实验结果表明,经过改进后的AI在reward获取方面表现出更加优秀的性能和效果,能够更好地适应游戏环境和变化,为AI的学习和决策提供了更加精准的指导和奖励。
通过以上改进,我们对QLearning算法的reward获取方式进行了有效优化,为AI的整体表现和学习效果奠定了坚实的基础。
结语:在本次实验中,我们针对QLearning算法的核心问题进行了深入的优化和改进,特别是在reward获取方面取得了显著的进展。我们相信通过不懈的努力和持续的探索,我们的AI系统将在未来的比赛和应用中展现出更加优秀的表现和成绩。感谢您的关注和支持!
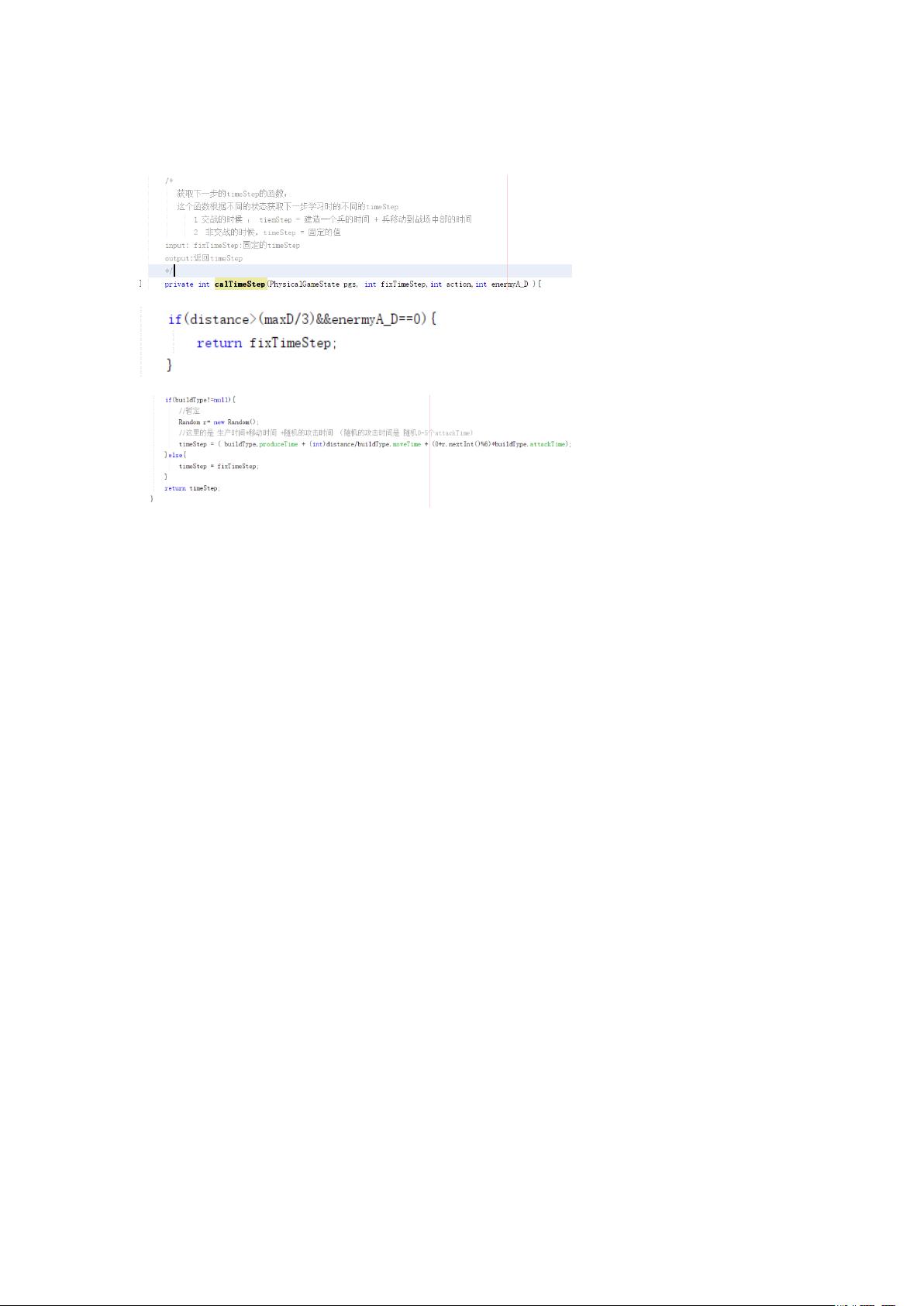
略获取动态的 timeStep,能够让 reward 反映的更加科学。对应到代码中:
(设置 calTimeStep 计算 timeStep,以针对不同的情况采用不同的 timeStep 计算方式)
三 增加了更多的状态
正 如我 们 在 报 告 三 中 所 述 , 状 态 过 少 将 会 导 致 矛 盾 地 出 现 , 由 于 我 们 采 用 的
QLearning,状态是离散的,这是 QLearning 这一经典的强化学习算法的固有特点,我们
无法改变,因此直观、直接的做法就是,增加更多的状态,在上一个版本的 AI 中我们值考
虑了 1 局势(5 个) 2 敌方的攻防状态(2 个) 3 敌方主要兵种(10 个) 一共是 5*2*10 =
100 个 state。在这一个版本的 AI,我们除了考虑对方的战场信息,我们还考虑了己方的
战场信息,并且并且将局势状态增加到了 10 个,在这一个版本中 1 局势(9) 2 敌方攻防
(2)3 我方攻防(2)4 敌方主要兵种(5) 5 我方主要兵种(5) 一共有 9*2*2*5*5 = 3600
个 state。State 的大量增加,带来的好处是决策更加灵活,比如我多次看到了己方出现
(light+ranged)的兵力配合(light+ranged 很强,因为 light 可以在前面给 ranged 当
挡箭牌)碾压对面,这就是综合考虑己方的 state 的结果,但这也带来了一个问题,state 太
多,收敛太慢,大多都还是 0,由于时间原因以及临近考试周,我们并未完成对 ai 的调试,
剩余21页未读,继续阅读
2021-04-30 上传
2021-06-05 上传
2024-11-16 上传
2024-11-16 上传
2024-11-16 上传
2024-11-16 上传
2024-11-16 上传

余青葭
- 粉丝: 44
- 资源: 303
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
