Radware LinkProof 6.10 配置与负载均衡指南
需积分: 10 152 浏览量
更新于2024-07-06
收藏 4.47MB DOC 举报
"Radware LinkProof 6.10 配置指导书"
这本配置指导书详细介绍了如何配置和管理Radware LinkProof 6.10,这是一款用于链路负载均衡和网络地址转换(NAT)的解决方案。Radware LinkProof旨在提供高可用性和性能优化,确保网络连接的稳定性和效率。
在第1章中,读者可以了解到LinkProof产品的基本信息和一些关键术语。产品介绍涵盖了LinkProof的核心功能,包括它如何通过智能地分配网络流量来提升网络服务的可靠性。基本术语部分则解释了与配置相关的专业词汇,帮助用户更好地理解后续章节的内容。
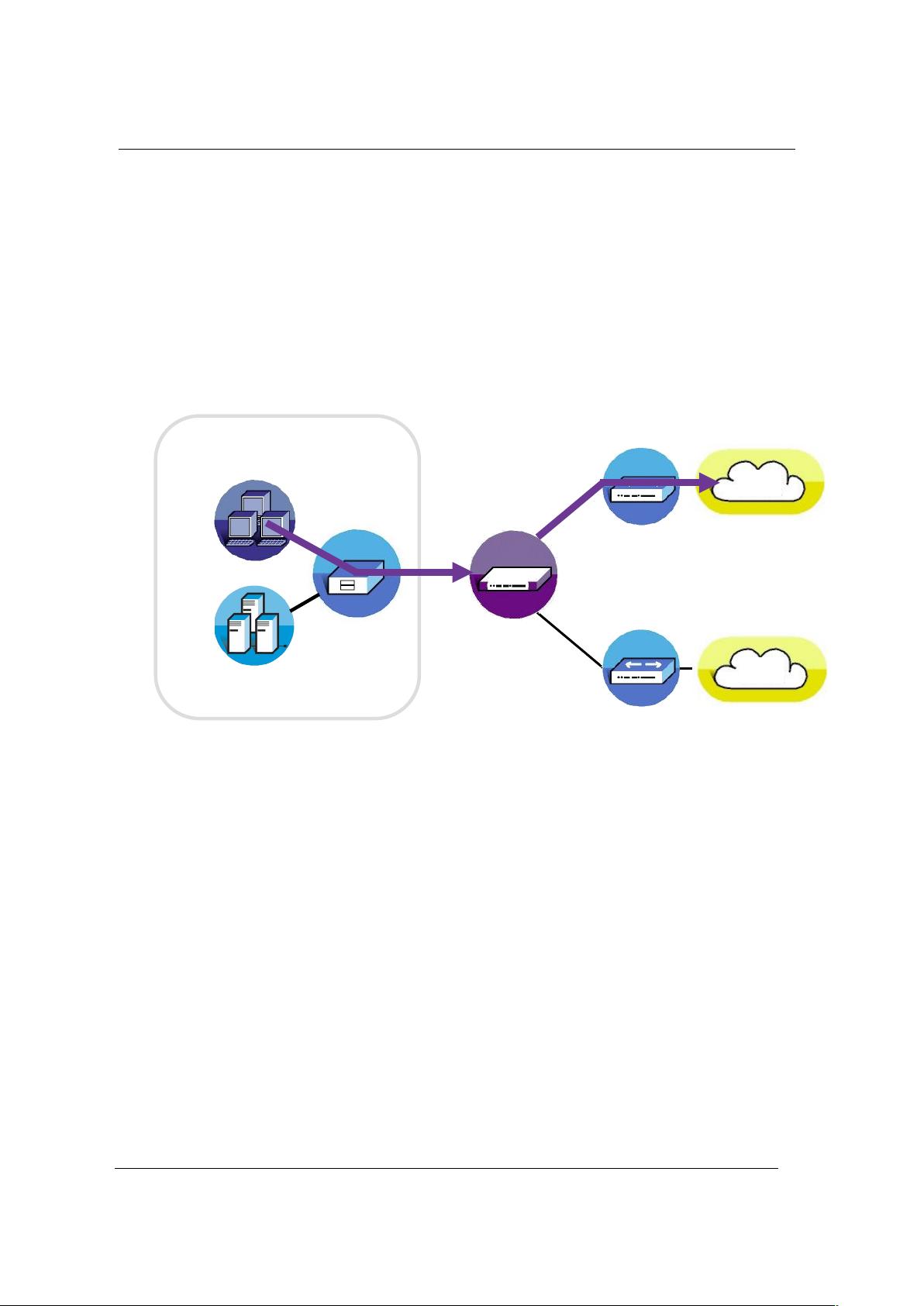
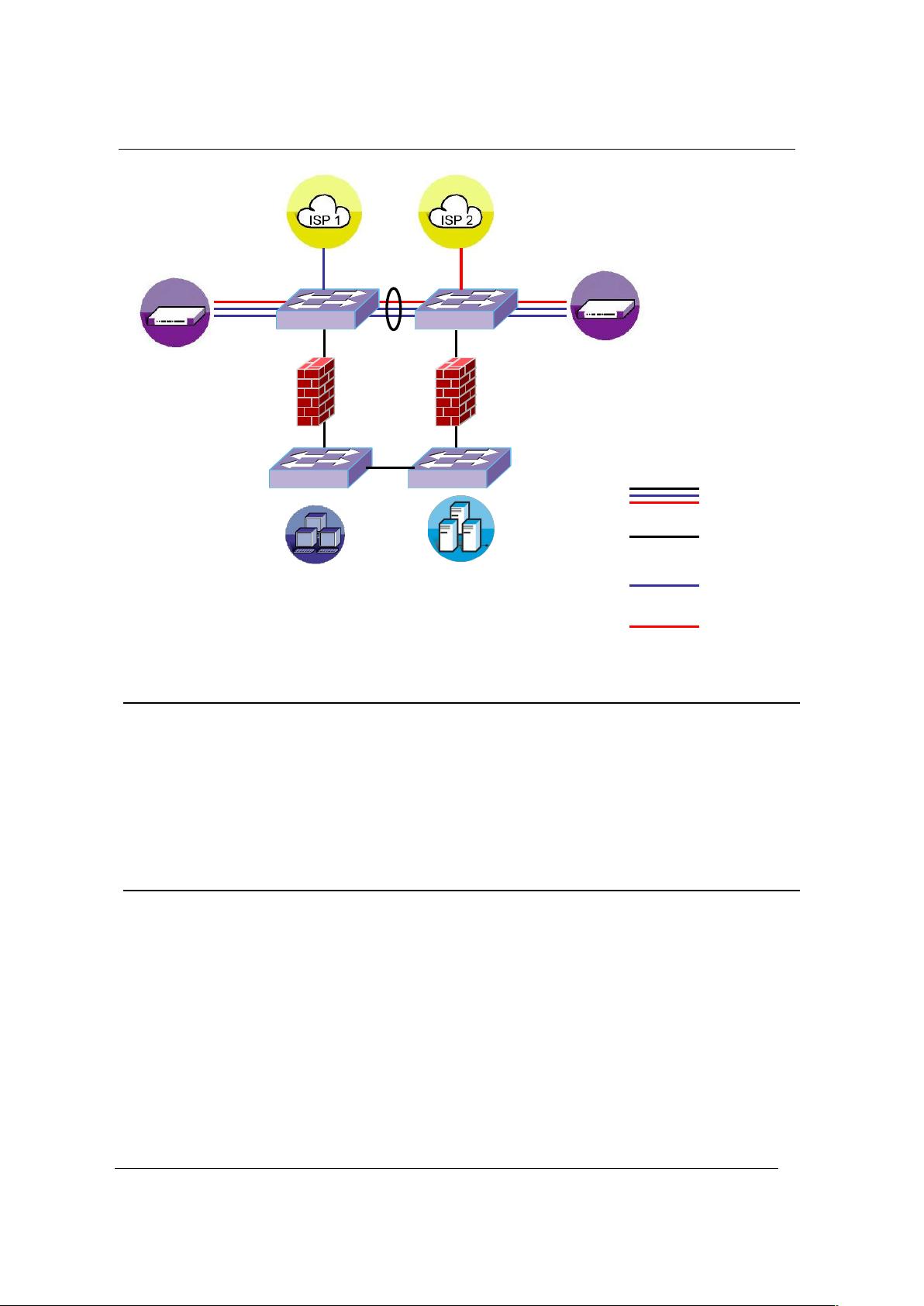
第2章详述了LinkProof的组网和配置流程。这部分包含了不同部署模式,如单机直连、双机旁挂的配置示例,并指导用户如何规划LP地址、NAT地址、路由策略以及DNS设置。这些规划是确保LinkProof有效运行的基础。
第3章重点在于LinkProof的基本配置,包括如何通过console线连接设备、登录、初始化配置,以及如何查看设备版本和License。此外,还讨论了命令行界面可能出现的乱码问题以及如何设置设备名称和管理界面。
第4章涉及双机配置,讲解了主机和备机的虚拟路由冗余协议(VRRP)配置。VRRP是确保高可用性的关键,它能在主设备故障时自动切换到备用设备,保持服务连续性。
第5章详细介绍了Flow配置,这是负载均衡的核心部分。Flow管理涉及到Farm(应用服务器集合)、服务器和FlowPolicy的创建和配置,以实现流量的智能分发。
第6章涵盖SmartNAT配置,包括静态NAT、动态NAT和静态PAT。这些NAT技术有助于转换和管理网络中的IP地址,确保数据包正确路由。
第7章专门讲解DNS配置,包括设置TTL(生存时间)、配置Host记录,以及针对BIND DNS服务器和Windows DNS服务器的修改方法,以支持LinkProof的负载均衡功能。
最后,第8章介绍了“就近性”配置,这是一种根据用户位置优化流量路由的方法,可以提高用户体验和网络性能。
总体而言,这份指导书是管理员进行Radware LinkProof 6.10配置的宝贵参考资料,提供了详细的步骤和最佳实践,以确保用户能够充分利用LinkProof的功能,建立高效且可靠的网络环境。

Radware LinkProof 负载均衡器指导书
中继段(NHR)
在传输过程中,IP 数据包会经历一个路由器又一个路由器。每两个路由器之间的距离被称
为一个中继段。Radware 的就近性检测方法可测量客户端和服务之间的中继段数。
多宿主
通过多个ISP 连接将一个局域网接入Internet 的方法。
网络就近性
为确定最快速的网络访问路径而使用的方法。该方法考虑了资源和客户端之间的中继段数
和延时,并且可由管理员进行加权。
就近性检测试探
Radware LinkProof 用来测量客户端和服务之间的中继段数和延时的方法。
静态(就近性)表
LinkProof 利用该表的参数将客户端引导到服务,管理员可对这些参数进行配置。静态表中
的条目包括IP 地址范围和三个用于将客户端引导到服务的参数。
Redundancy
主备冗余,用于LP的双机配置和通信,防止设备单点故障。两种方法来保证可用性:ARP
和VRRP,一般使用VRRP。
第2章 LinkProof组网和配置流程
2010-06-22
第 6 页, 共142
页
剩余63页未读,继续阅读
2019-06-19 上传
2014-07-05 上传
2013-02-20 上传
2020-11-26 上传
点击了解资源详情
2013-02-20 上传
2013-06-08 上传
2012-08-29 上传
点击了解资源详情

mingxuanju
- 粉丝: 2
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular程序高效加载与展示海量Excel数据技巧
- Argos客户端开发流程及Vue配置指南
- 基于源码的PHP Webshell审查工具介绍
- Mina任务部署Rpush教程与实践指南
- 密歇根大学主题新标签页壁纸与多功能扩展
- Golang编程入门:基础代码学习教程
- Aplysia吸引子分析MATLAB代码套件解读
- 程序性竞争问题解决实践指南
- lyra: Rust语言实现的特征提取POC功能
- Chrome扩展:NBA全明星新标签壁纸
- 探索通用Lisp用户空间文件系统clufs_0.7
- dheap: Haxe实现的高效D-ary堆算法
- 利用BladeRF实现简易VNA频率响应分析工具
- 深度解析Amazon SQS在C#中的应用实践
- 正义联盟计划管理系统:udemy-heroes-demo-09
- JavaScript语法jsonpointer替代实现介绍
