Java PriorityQueue详解:数据结构与实现
20 浏览量
更新于2024-06-18
收藏 2.76MB PDF 举报
【优先级队列详解】
在数据结构的学习中,优先级队列(PriorityQueue)是一种特殊类型的队列,它并不遵循一般的先进先出(FIFO)原则,而是根据元素的优先级来决定出队的顺序。本节笔记的重点在于理解堆(Heap)这一数据结构在实现优先级队列中的核心作用。
堆是一种特殊的完全二叉树,根据元素的关键码(key)值,分为最大堆(最大键值节点在根部)和最小堆(最小键值节点在根部)。堆的主要特性包括:
1. 堆的定义:
- 堆是一组按照特定规则排列的元素集合,每个节点的关键码值要么不大于其父节点,要么不小于(对于最大堆),这被称为堆的“大顶堆”或“完全二叉树”性质。
- 在最大堆中,根节点的键值最大,而在最小堆中,根节点的键值最小。
2. 堆的存储:
- 因为堆是完全二叉树,所以可以利用顺序存储的方式高效地实现。通过数组表示,每个节点的索引与树结构中的关系可以通过二叉树的性质5来确定,即计算左、右子节点的索引。
3. 堆的创建与调整:
- 对于一组初始数据,创建堆的过程通常涉及“堆化”操作,即将数据逐个插入到堆中,同时保持堆的性质。例如,对于非初始堆化的数据,可能需要从最后一个元素开始,通过“堆向下调整”(也叫下沉操作)来确保整个堆仍满足堆的性质。
- 当添加新元素时,如果它大于(或小于)其父节点,就需要将其与父节点交换位置,然后继续与兄弟节点比较,直到达到正确的位置,从而保持堆的性质。
4. Java实现:
- Java标准库中的`PriorityQueue`类就是基于最大堆实现的。底层使用数组表示堆,当添加新元素或删除最小元素时,它自动维护堆的结构,使得获取最小(或最大)优先级的元素变得非常高效。
5. 应用示例:
- 优先级队列在很多场景中有重要作用,如游戏中的事件处理(电话处理),任务调度,网络路由选择等,它们都能根据元素的优先级来优化算法的性能。
理解并掌握堆及其在优先级队列中的应用,对于解决具有优先级问题的算法设计至关重要。通过模拟实现和实际编程练习,可以更好地掌握这一数据结构,并在实际项目中灵活运用。
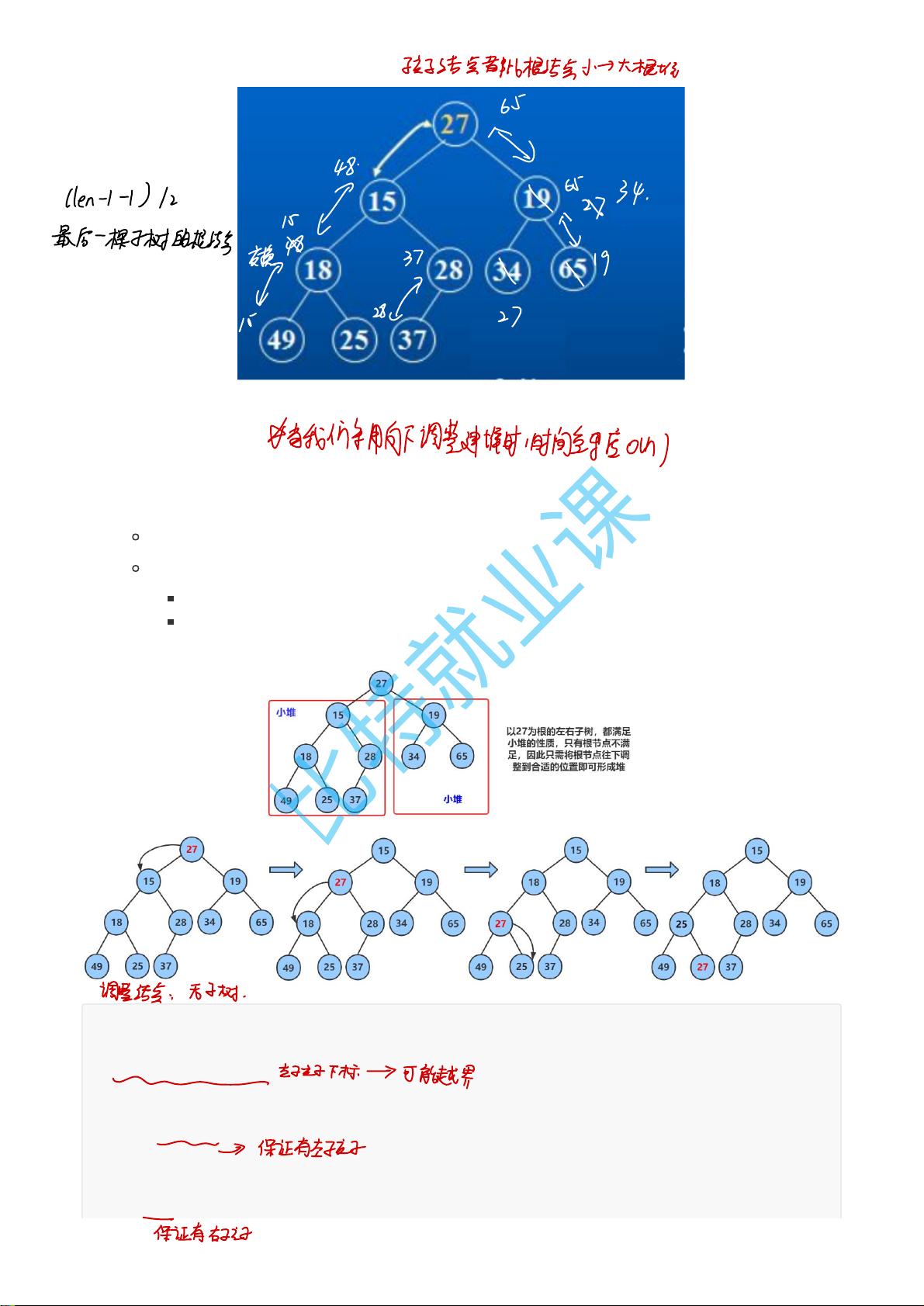
仔细观察上图后发现:根节点的左右子树已经完全满足堆的性质,因此只需将根节点向下调整好即可。
向下过程(以小堆为例):
1. 让parent标记需要调整的节点,child标记parent的左孩子(注意:parent如果有孩子一定先是有左孩子)
2. 如果parent的左孩子存在,即:child < size, 进行以下操作,直到parent的左孩子不存在
parent右孩子是否存在,存在找到左右孩子中最小的孩子,让child进行标
将parent与较小的孩子child比较,如果:
parent小于较小的孩子child,调整结束
否则:交换parent与较小的孩子child,交换完成之后,parent中大的元素向下移动,可能导致子
树不满足对的性质,因此需要继续向下调整,即parent = child;child = parent*2+1; 然后继续2。
public void shiftDown(int[] array, int parent) {
// child先标记parent的左孩子,因为parent可能右左没有右
int child = 2 * parent + 1;
int size = array.length;
while (child < size) {
// 如果右孩子存在,找到左右孩子中较小的孩子,用child进行标记
if(child+1 < size && array[child+1] < array[child]){
⽐特就业课
孩⼦
结点
都
⽐
棍
弦
⼩
⼀
⼤
根
堆
6
5
⼈
lkn
-
1
-
1
)
1
2
1
5
Y
\
"
汉
3
4
,
它
最后
棵⼦
树
的
桕
坊
曾
为
3
7
\
\
1
9
-
1
5
2
7
4
当
我们
绷
下
调整
雠
时
时间
鲟
庄
州
调整
结点
,
⽆
⼦
树
,
vrrrrs
古
拉
⼦
下
标
→
可能
越界
-0ns
保证
有
五
⼦
之
⼦
原
证
有
矷
之
⼦
剩余14页未读,继续阅读
113 浏览量
174 浏览量
109 浏览量
160 浏览量
2016-11-15 上传
2024-06-21 上传
142 浏览量

muyierfly
- 粉丝: 1861
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- LanYaAPP.zip
- rino-status:oca Ocavue的正常运行时间监控器和状态页面,由@upptime提供支持
- Simple Task Management App in JavaScript Free Source Code.zip
- 25个经典网站源代码.zip
- button style.rar
- kafka-service-interface:公开Kafka生产者和消费者API的Docker服务
- 西门子Safety电子学习解决方案.rar
- repmgr:PostgreSQL最受欢迎的复制管理器(Postgres)-最新版本5.2.1(2020-12-07)
- nvp-accessor:smple模块,用于访问名称-值对数组中的值
- Matlab_optical.zip_MATLAB 物理_MATLAB光学_matlab 几何光学_光学_物理光学
- 马修斯网站
- 基于python开发的中国关单数据查询免费软件v1.0下载
- Sticky Note Apps using JavaScript with Source Code.zip
- presentation-Website:演示的好网站
- spring.zip
- 高斯白噪声matlab代码-DDWD:数据驱动的小波
