深度学习架构在人工智能中的应用
“Learning Deep Architectures for AI - Yoshua Bengio - Foundations and Trends in Machine Learning”
在人工智能领域,深度学习已经成为一种强大的工具,特别是在理解和解决复杂的功能表示方面,比如视觉、语言和其他高级任务。《Learning Deep Architectures for AI》这篇论文由Yoshua Bengio撰写,探讨了构建和学习深度架构的关键概念和理论。
深度架构是由多层非线性操作组成的,如具有多个隐藏层的神经网络或复杂的命题公式,它们重用许多子公式。这些层次结构的设计目的是模拟人类大脑的分层信息处理机制,从而更好地捕捉数据中的抽象特征。尽管深度学习模型的参数空间极其庞大,使得学习过程极具挑战性,但近年来已经开发出如深度信念网络(Deep Belief Networks, DBNs)等学习算法,成功地解决了这一问题,并在某些领域超越了传统方法,创下了新的性能纪录。
论文深入讨论了设计深度学习算法的动机和原则,特别是利用单层无监督学习模型(如受限玻尔兹曼机,Restricted Boltzmann Machines, RBMs)作为构建块的方法。无监督学习在预训练阶段可以帮助初始化深层网络的权重,这可以极大地提高后续的监督学习阶段的效率和性能。预训练与微调相结合的策略,已经成为深度学习中一个关键步骤,它能够有效地避免过拟合,同时提升模型的泛化能力。
此外,论文还探讨了深度学习中的其他重要技术,如反向传播(Backpropagation)在优化过程中的作用,以及如何通过正则化和dropout策略来控制模型的复杂性,防止过拟合。在实际应用中,这些技术对于构建能够处理大量数据并从中学习复杂模式的系统至关重要。
深度学习不仅限于神经网络,还包括其他类型的深度模型,如卷积神经网络(Convolutional Neural Networks, CNNs)在图像识别和处理中的应用,以及递归神经网络(Recurrent Neural Networks, RNNs)在自然语言处理中的使用。这些模型能够处理序列数据,捕获时间依赖性,并在序列预测任务中展现出卓越的性能。
《Learning Deep Architectures for AI》这篇论文为理解深度学习的基本原理和实践提供了全面的视角,强调了深度架构在AI领域的潜力,并为研究者和从业者提供了探索和改进深度学习模型的指导框架。随着计算能力的增强和大数据集的可用性,深度学习将继续推动人工智能的边界,促进更加智能和自主的系统的发展。

In the above equation, f(x) could be for example the discriminant function of a classifier, or the output of a
regression predictor.
A kernel is local when K(x, x
i
) > ρ is true only for x in some connected region around x
i
(for some
threshold ρ). The size of that region can usually be controlled by a hyper-parameter of the kernel function.
An example of local kernel is the Gaussian kernel K(x, x
i
) = e
−||x−x
i
||
2
/σ
2
, where σ controls the size of
the region around x
i
. We can see the Gaussian kernel as computing a soft conjunction, because it can be
written as a product of one-dimensional conditions: K(u, v) =
Q
j
e
−(u
j
−v
j
)
2
/σ
2
. If |u
j
− v
j
|/σ is small
for all dimensions j, then the pattern matches and K(u, v) is large. If |u
j
− v
j
|/σ is large for a single j,
then there is no match and K(u, v) is small.
Well-known examples of kernel machines include Support Vector Machines (SVMs) (Boser, Guyon, &
Vapnik, 1992; Cortes & Vapnik, 1995) and Gaussian processes (Williams & Rasmussen, 1996)
3
for classifi-
cation and regression, but also classical non-parametric learning algorithms for classification, regression and
density estimation, such as the k-nearest neighbor algorithm, Nadaraya-Watson or Parzen windows density
and regression estimators, etc. Below, we discuss manifold learning algorithms such as Isomap and LLE that
can also be seen as local kernel machines, as well as related semi-supervised learning algorithms also based
on the construction of a neighborhood graph (with one node per example and arcs between neighboring
examples).
Kernel machines with a local kernel yield generalization by exploiting what could be called the smooth-
ness prior: the assumption that the target function is smooth or can be well approximated with a smooth
function. For example, in supervised learning, if we have the training example (x
i
, y
i
), then it makes sense
to construct a predictor f (x) which will output something close to y
i
when x is close to x
i
. Note how this
prior requires defining a notion of proximity in input space. This is a useful prior, but one of the claims
made in Bengio, Delalleau, and Le Roux (2006) and Bengio and LeCun (2007) is that such a prior is often
insufficient to generalize when the target function is highly-varying in input space.
The limitations of a fixed generic kernel such as the Gaussian kernel have motivated a lot of research in
designing kernels based on prior knowledge about the task (Jaakkola & Haussler, 1998; Sch¨olkopf, Mika,
Burges, Knirsch, M¨uller, R¨atsch, & Smola, 1999b; G¨artner, 2003; Cortes, Haffner, & Mohri, 2004). How-
ever, if we lack sufficient prior knowledge for designing an appropriate kernel, can we learn it? This question
also motivated much research (Lanckriet, Cristianini, Bartlett, El Gahoui, & Jordan, 2002; Wang & Chan,
2002; Cristianini, Shawe-Taylor, Elisseeff, & Kandola, 2002), and deep architectures can be viewed as a
promising development in this direction. It has been shown that a Gaussian Process kernel machine can
be improved using a Deep Belief Network to learn a feature space (Salakhutdinov & Hinton, 2008): after
training the Deep Belief Network, its parameters are used to initialize a deterministic non-linear transfor-
mation (a multi-layer neural network) that computes a feature vector (a new feature space for the data), and
that transformation can be tuned to minimize the prediction error made by the Gaussian process, using a
gradient-based optimization. The feature space can be seen as a learned representation of the data. Good
representations bring close to each other examples which share abstract characteristics that are relevant fac-
tors of variation of the data distribution. Learning algorithms for deep architectures can be seen as ways to
learn a good feature space for kernel machines.
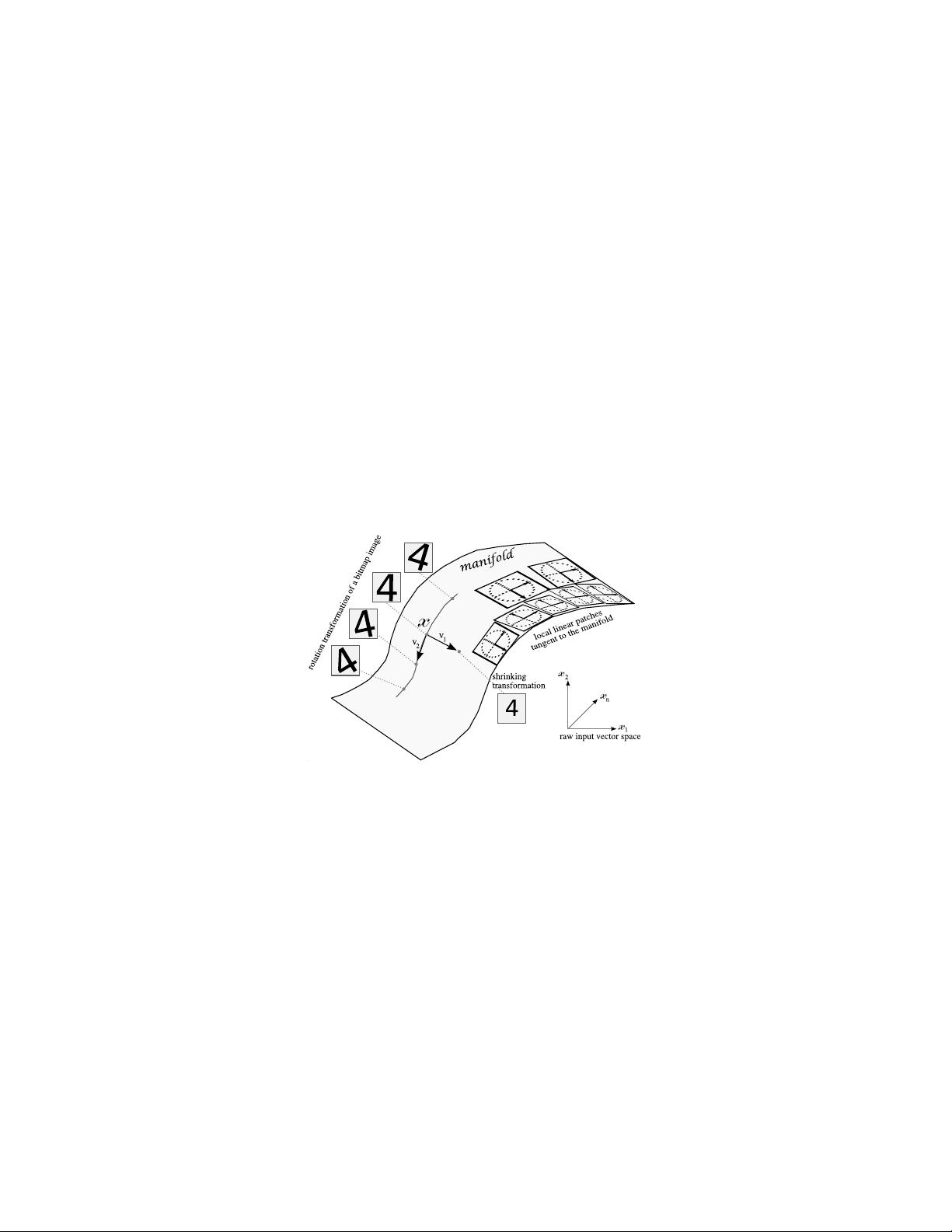
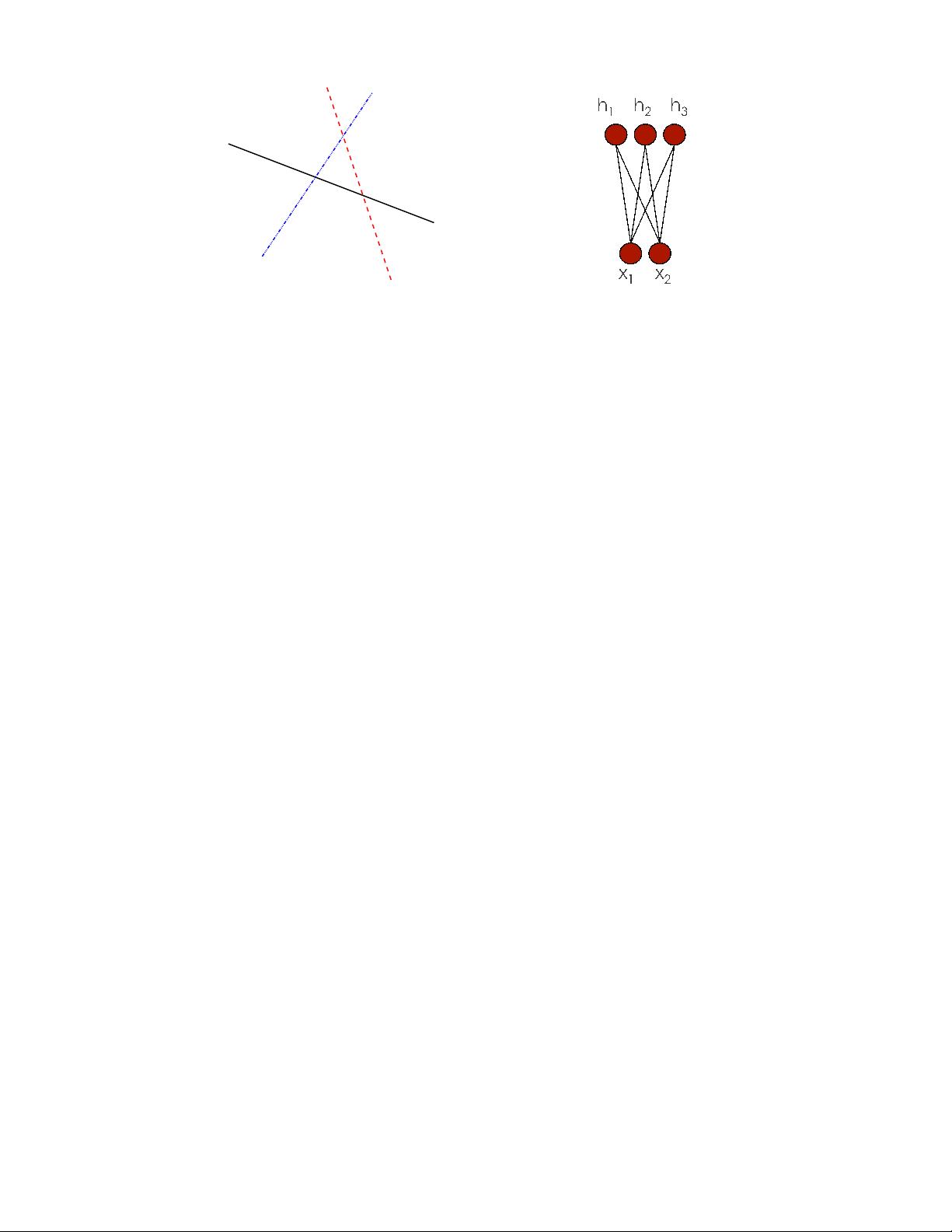
Consider one direction v in which a target function f (what the learner should ideally capture) goes
up and down (i.e. as α increases, f (x + αv) − b crosses 0, becomes positive, then negative, positive,
then negative, etc.), in a series of “bumps”. Following Schmitt (2002), Bengio et al. (2006), Bengio and
LeCun (2007) show that for kernel machines with a Gaussian kernel, the required number of examples
grows linearly with the number of bumps in the target function to be learned. They also show that for a
maximally varying function such as the parity function, the number of examples necessary to achieve some
error rate with a Gaussian kernel machine is exponential in the input dimension. For a learner that only relies
on the prior that the target function is locally smooth (e.g. Gaussian kernel machines), learning a function
with many sign changes in one direction is fundamentally difficult (requiring a large VC-dimension, and a
3
In the Gaussian Process case, as in kernel regression, f(x) in eq. 2 is the conditional expectation of the target variable Y to predict,
given the input x.
12

剩余70页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-04-18 上传
2010-10-14 上传
2019-10-25 上传
2018-04-22 上传
2023-12-28 上传
2018-09-17 上传

机器再学习
- 粉丝: 80
- 资源: 25
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
