Zookeeper双数据中心容灾机制探索
需积分: 0 53 浏览量
更新于2024-08-05
1
收藏 507KB PDF 举报
"本文主要探讨了Zookeeper在双数据中心的容灾策略,并分析了其内部的工作机制,特别是客户端连接和线程模型。"
Zookeeper是一个分布式协调服务,它为分布式应用程序提供可靠的原子服务,如命名服务、配置管理、组服务和锁服务等。在双数据中心的容灾研究中,Zookeeper通过设置独立的集群来确保在一个数据中心出现故障时,另一个数据中心仍能继续提供服务,从而提高系统的可用性和韧性。
首先,Zookeeper的容错机制依赖于其内置的领导者(Leader)选举算法。在正常运行时,每个Zookeeper节点都是平等的,但其中一个节点会成为领导者,负责处理所有的更新操作。如果某个数据中心的服务器宕机,且宕机数量不超过集群总数的一半,Zookeeper可以通过选举新的领导者继续保持集群的正常运行。通常,为了最大化容错能力,会选择奇数台服务器进行部署。
跨数据中心的容灾方案通常采用独立集群的方式,这样可以保证在每个数据中心内读写性能都很高。然而,这种方案的缺点是无法保证全局数据的唯一性,因为每个集群可能拥有不同的数据视图。为了解决这个问题,可以考虑使用Quorum机制或配置复制策略,确保两个数据中心的数据同步。
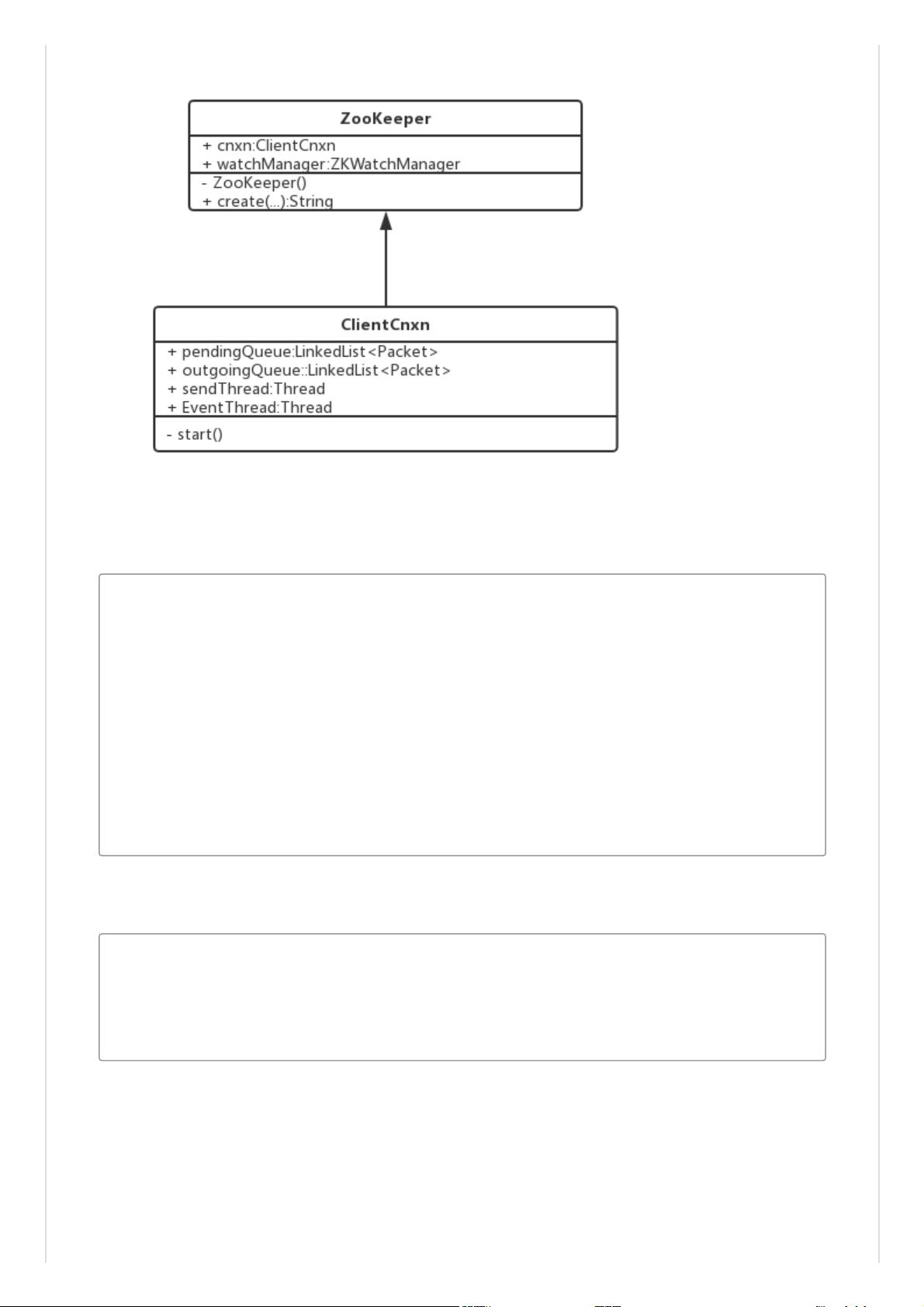
在Zookeeper的客户端连接过程中,涉及到几个关键步骤。当创建`ZooKeeper`对象时,会启动`ClientCnxn`的`start`方法。这个方法会初始化一个`SendThread`和`EventThread`线程。`SendThread`负责与服务器的通信,处理连接和服务端的交互,而`EventThread`则处理客户端的事件,如服务器状态变化或操作结果返回。
`SendThread`的工作原理是,客户端的请求被封装成`Packet`对象并放入`OutgoingQueue`,等待网络连接准备就绪后,这些请求会被移动到`PendingQueue`,然后由`SendThread`进行发送。当服务器响应时,事件会被封装成`Event`对象,放入`EventThread`,由`EventThread`负责通知客户端。
总结来说,Zookeeper的双数据中心容灾策略旨在通过独立的集群在数据中心故障时保持服务连续性。客户端通过复杂的连接和事件处理机制与Zookeeper服务器进行交互,保证了请求的正确发送和处理。理解这些机制对于优化Zookeeper的部署和提高系统的可靠性至关重要。
2017/10/10 zookeeper双数据中心容灾研究
file:///C:/users/admini~1/appdata/local/temp/23.html 3/11
其中客户端连接过程具体如下:
0:在构造Zookeeper对象时,会执行cnxn的start方法:
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher,
boolean canBeReadOnly)
throws IOException
{
HostProvider hostProvider = new StaticHostProvider(
connectStringParser.getServerAddresses());
cnxn = new ClientCnxn(connectStringParser.getChrootPath(),
hostProvider, sessionTimeout, this, watchManager,
getClientCnxnSocket(), canBeReadOnly);
cnxn.start();
}
1:start方法启动了SendThread和EventThread线程:
public void start() {
sendThread.start();
eventThread.start();
}
2:SendThread线程会有对服务端连接的操作(源码有删减):
剩余10页未读,继续阅读
2020-08-05 上传
2021-10-24 上传
2023-06-14 上传
2017-11-23 上传
2019-12-13 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

史努比狗狗
- 粉丝: 30
- 资源: 317
 我的内容管理
展开
我的内容管理
展开







