Hadoop3.0分布式集群搭建详细指南
需积分: 14 175 浏览量
更新于2024-09-09
收藏 37KB DOCX 举报
"Hadoop3.0版本分布式搭建文档主要涵盖了Hadoop环境的配置,包括JDK的安装、Hadoop的解压与配置,以及核心配置文件的修改,以实现一个分布式集群的搭建。"
在Hadoop3.0版本中,构建分布式集群是一个重要的任务,因为这关乎到大数据处理的效率和可靠性。以下是详细步骤和关键知识点:
1. JDK8的安装与配置:
- Hadoop3.0要求Java开发工具包(JDK)版本为8。首先,需要下载JDK8并进行解压。
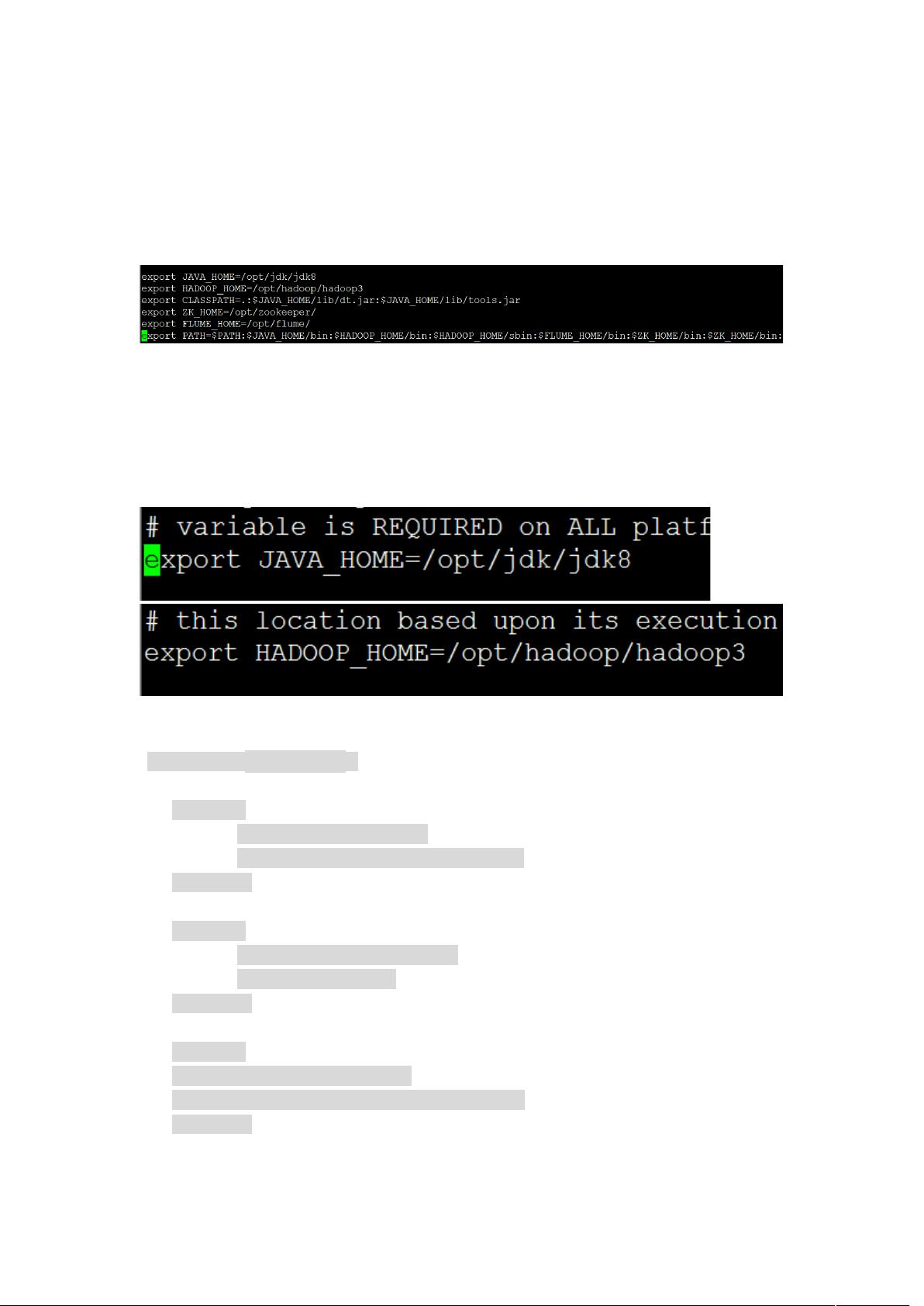
- 配置`profile`文件是确保系统环境变量能够识别JDK路径的关键。通过`vi /etc/profile`编辑文件,添加JDK8的安装路径,并在完成后执行`source /etc/profile`使配置生效。
2. Hadoop3.0的解压:
- 解压缩下载好的Hadoop3.0二进制包,通常将其放在合适的位置,例如 `/opt` 目录下。
3. 配置Hadoop环境:
- 进入`etc/hadoop`目录,开始配置Hadoop的相关环境变量。
- 修改`hadoop-env.sh`文件,设置`JAVA_HOME`为JDK8的路径,同时设定`HADOOP_HOME`为Hadoop的安装路径。
4. 配置core-site.xml:
- `core-site.xml`文件用于定义Hadoop的基本行为。在这个文件中,你需要配置默认文件系统(`fs.defaultFS`),例如设置为`hdfs://192.168.10.21:8020`,这里192.168.10.21是NameNode的IP地址。
- `io.file.buffer.size`定义了I/O缓冲区的大小,此处设为131072字节,可以根据实际需求调整。
- `hadoop.tmp.dir`指定Hadoop临时文件的目录,例如`file:///opt/hadoop/hadoop3/tmp`。
5. 配置hdfs-site.xml:
- `dfs.namenode.name.dir`定义NameNode存储元数据的目录,如`file:///opt/dfs/name`,这将保存HDFS的命名空间信息和检查点。
- `dfs.datanode.data.dir`设置DataNode的数据存储目录,例如`file:///opt/dfs/data`,每个DataNode在此目录下创建多个数据块存储目录。
- `dfs.http.address`配置NameNode的Web UI端口,以便通过浏览器查看HDFS状态,这里是`192.168.10.21:50070`。
- `dfs.secondary.http.address`配置Secondary NameNode的Web UI端口,用于监控NameNode,这里是`192.168.10.21:50090`,同样需要替换为实际的IP地址。
完成上述配置后,还需要在集群中的其他节点上复制配置文件和Hadoop软件,并进行相应的修改以适应各自的角色。对于DataNode,需要配置`slaves`文件列出所有DataNode的主机名。接着启动Hadoop服务,包括NameNode、DataNode、Secondary NameNode以及其他相关守护进程,以确保集群正常运行。
在实际操作中,还需要关注网络配置、安全性设置、数据均衡策略、性能优化等方面,以保证Hadoop集群的稳定性和高效性。同时,监控工具如Ambari、Ganglia或Prometheus可以帮助管理和监控Hadoop集群的状态。此外,熟悉Hadoop的YARN资源管理器和MapReduce计算框架也是运维人员必备的知识。
版本分布式集群搭建
要求 版本必须为 请先下载好 并解压
配置 文件信息添加 路径以及 路径配置完请刷新
解压
进入 目录
首先配置 文件配置好 !"#$ 路径以及 ""%!"#$ 路径
&配置 '(在)*+,-)*+,-中间加入一下信息
./ 为第一台节点 0%
)1-
)(-22+34)(-
)+-25./5)+-
)1-
)1-
)(-6+78)(-
)+-9)+-
)1-
)1-
)(-()(-
)+-5()+-
)1-
/配置 2'(在)*+,-)*+,-中间加入一下信息
下载后可阅读完整内容,剩余4页未读,立即下载
1525 浏览量
777 浏览量
777 浏览量
127 浏览量
162 浏览量
325 浏览量
279 浏览量

qq_34678029
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入探讨V2C控制Buck变换器稳定性分析及仿真验证
- 2012款途观怡利导航破解方法及多图功能实现
- Vue.js图表库vuetrend:简洁优雅的动态数据展示
- 提升效率:仓库管理系统中的算法与数据结构设计
- Matlab入门必读教程——快速上手指南
- NARRA项目可视化工具集 - JavaScript框架解析
- 小蜜蜂天气预报查询系统:PHP源码与前端后端应用
- JVM运行机制深入解析教程
- MATLAB分子结构绘制源代码免费分享
- 掌握MySQL 5:《权威指南》第三版中文版
- Swift框架:QtC++打造的易用Web服务器解决方案
- 实现对话框控件自适应的多种效果
- 白镇奇士推出DBF转EXCEL高效工具:hap-dbf2xls-hyy
- 构建简易TCP路由器的代码开发指南
- ElasticSearch架构与应用实战教程
- MyBatis自动生成MySQL映射文件教程
