深入理解DRBD官方指南:多路径复制技术详解
需积分: 12 87 浏览量
更新于2024-07-17
收藏 1.1MB PDF 举报
《DRBD用户指南》是Brian Hellman、Florian Haas、Philipp Reisner和Lars Ellenberg四位作者共同编写的官方文档,专为DRBD(Distributed Replicated Block Device)社区设计。该指南不仅包含了关于DRBD的核心概念、安装配置、原理与操作的详细信息,还强调了持续改进的重要性,鼓励读者通过公共邮件列表[110]提供反馈和建议。
文档版权方面,2008年至2011年期间的部分内容分别由LINBIT Information Technologies GmbH和LINBIT HASolutions GmbH持有。所有文本和插图遵循Creative Commons Attribution-ShareAlike 3.0 Unported (CC-BY-SA) 许可协议,这意味着如果你在分发此文档或其改编版本时,必须提供原始版本的URL链接,尊重原作者的权益。
特别指出的是,DRBD、DRBD logo、LINBIT以及LINBIT logo是LINBIT Information Technologies GmbH在奥地利、美国和其他国家注册或使用的商标。
《DRBD用户指南》涵盖了以下主要知识点:
1. **DRBD简介**:介绍了DRBD的基本概念,作为一款分布式复制块设备,它旨在实现数据中心中的数据冗余和高可用性。
2. **安装与配置**:详细阐述了如何在不同的操作系统和架构上安装DRBD,包括设置网络连接、配置镜像和容错策略等关键步骤。
3. **工作原理**:解释了DRBD如何实现实时数据同步,包括心跳检测、一致性算法和故障恢复机制。
4. **操作与管理**:提供了日常维护、监控、故障排查和性能优化等方面的指导。
5. **高级主题**:涉及集群扩展、存储池管理、存储虚拟化和与其他技术(如HAProxy或Pacemaker)的集成等内容。
6. **最佳实践与安全**:讨论了如何制定和实施安全策略,以及如何避免常见问题和提高整体性能。
7. **更新与社区支持**:强调了社区的重要性,并指出可以通过邮件列表获得最新的更新和解决方案。
《DRBD用户指南》是深入理解并使用DRBD进行高性能、高可用性数据存储的关键资源,无论是对初学者还是经验丰富的系统管理员都具有极高的参考价值。

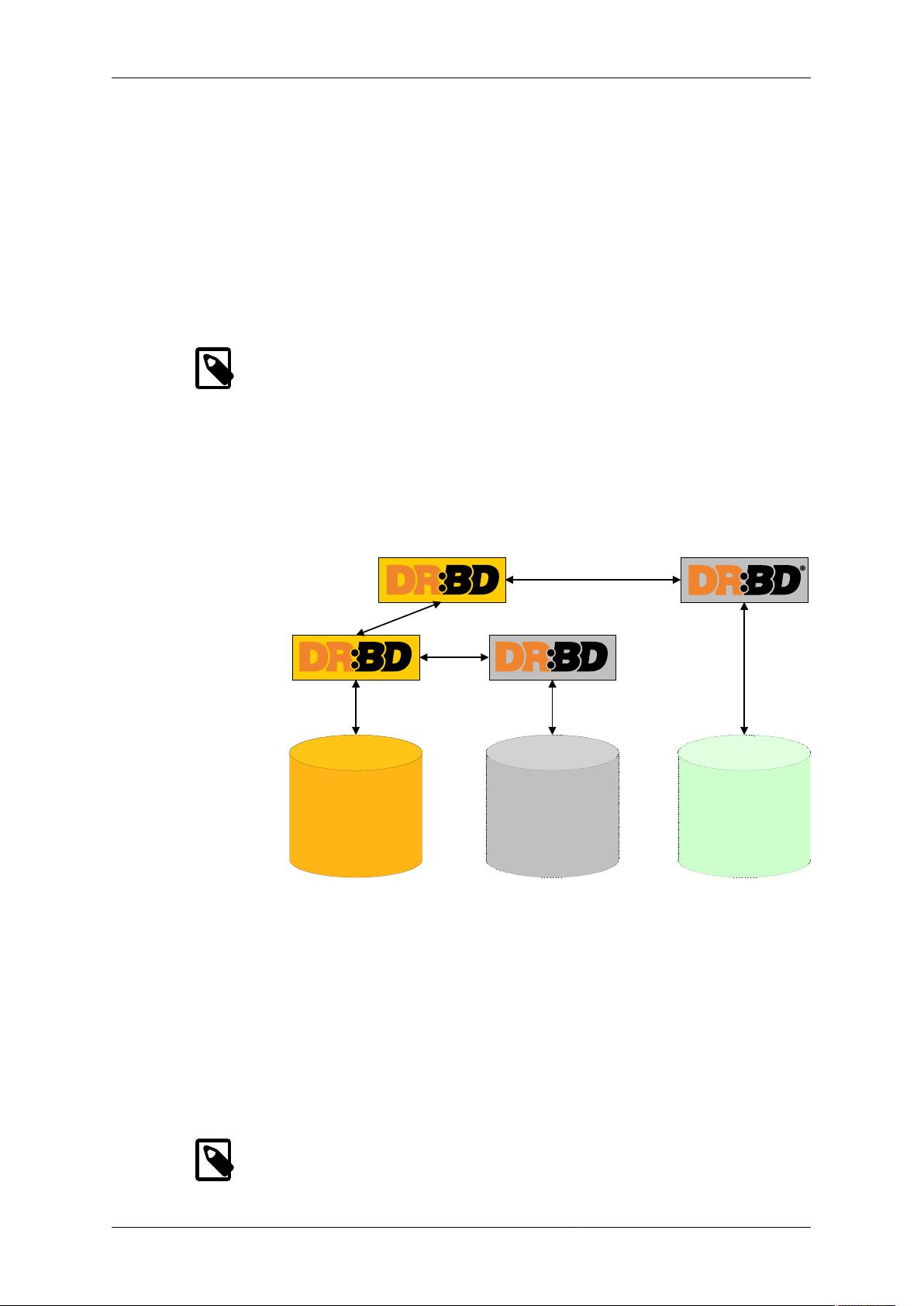
DRBD Features
8
Note that efficient refers to efficient use of network bandwidth here, and to the fact that
verification does not break redundancy in any way. On-line verification is still a resource-intensive
operation, with a noticeable impact on CPU utilization and load average.
It works by one node (the verification source) sequentially calculating a cryptographic digest
of every block stored on the lower-level storage device of a particular resource. DRBD then
transmits that digest to the peer node (the verification target), where it is checked against a digest
of the local copy of the affected block. If the digests do not match, the block is marked out-of-
sync and may later be synchronized. Because DRBD transmits just the digests, not the full blocks,
on-line verification uses network bandwidth very efficiently.
The process is termed on-line verification because it does not require that the DRBD resource
being verified is unused at the time of verification. Thus, though it does carry a slight performance
penalty while it is running, on-line verification does not cause service interruption or system down
time — neither during the verification run nor during subsequent synchronization.
It is a common use case to have on-line verification managed by the local cron daemon,
running it, for example, once a week or once a month. See Section6.6, “Using on-line device
verification” [38] for information on how to enable, invoke, and automate on-line verification.
2.8.Replication�traffic�integrity�checking
DRBD optionally performs end-to-end message integrity checking using cryptographic message
digest algorithms such as MD5, SHA-1 or CRC-32C.
These message digest algorithms are not provided by DRBD. The Linux kernel crypto API provides
these; DRBD merely uses them. Thus, DRBD is capable of utilizing any message digest algorithm
available in a particular system’s kernel configuration.
With this feature enabled, DRBD generates a message digest of every data block it replicates
to the peer, which the peer then uses to verify the integrity of the replication packet. If the
replicated block can not be verified against the digest, the peer requests retransmission. Thus,
DRBD replication is protected against several error sources, all of which, if unchecked, would
potentially lead to data corruption during the replication process:
• Bitwise errors ("bit flips") occurring on data in transit between main memory and the network
interface on the sending node (which goes undetected by TCP checksumming if it is offloaded
to the network card, as is common in recent implementations);
• bit flips occuring on data in transit from the network interface to main memory on the receiving
node (the same considerations apply for TCP checksum offloading);
• any form of corruption due to a race conditions or bugs in network interface firmware or
drivers;
• bit flips or random corruption injected by some reassembling network component between
nodes (if not using direct, back-to-back connections).
See Section 6.11, “Configuring replication traffic integrity checking” [43] for information on
how to enable replication traffic integrity checking.
2.9.Split�brain�notification�and�automatic
recovery
Split brain is a situation where, due to temporary failure of all network links between cluster
nodes, and possibly due to intervention by a cluster management software or human error, both
nodes switched to the primary role while disconnected. This is a potentially harmful state, as it



剩余169页未读,继续阅读
2021-02-05 上传
2020-06-09 上传
315 浏览量
点击了解资源详情
2013-10-02 上传
2021-01-20 上传

lisq6151
- 粉丝: 0
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
