KMP算法解析:提升字符串模式匹配效率
需积分: 9 109 浏览量
更新于2024-09-20
收藏 204KB DOC 举报
"KMP字符串模式匹配详解"
KMP算法,全称为Knuth-Morris-Pratt算法,是一种在文本字符串中高效地查找模式串(目标字符串)的算法。相较于简单的暴力匹配方法,KMP算法避免了不必要的回溯,显著提高了搜索效率。其核心思想是利用模式串的已知信息来减少不必要的比较,尤其是在遇到不匹配的情况时。
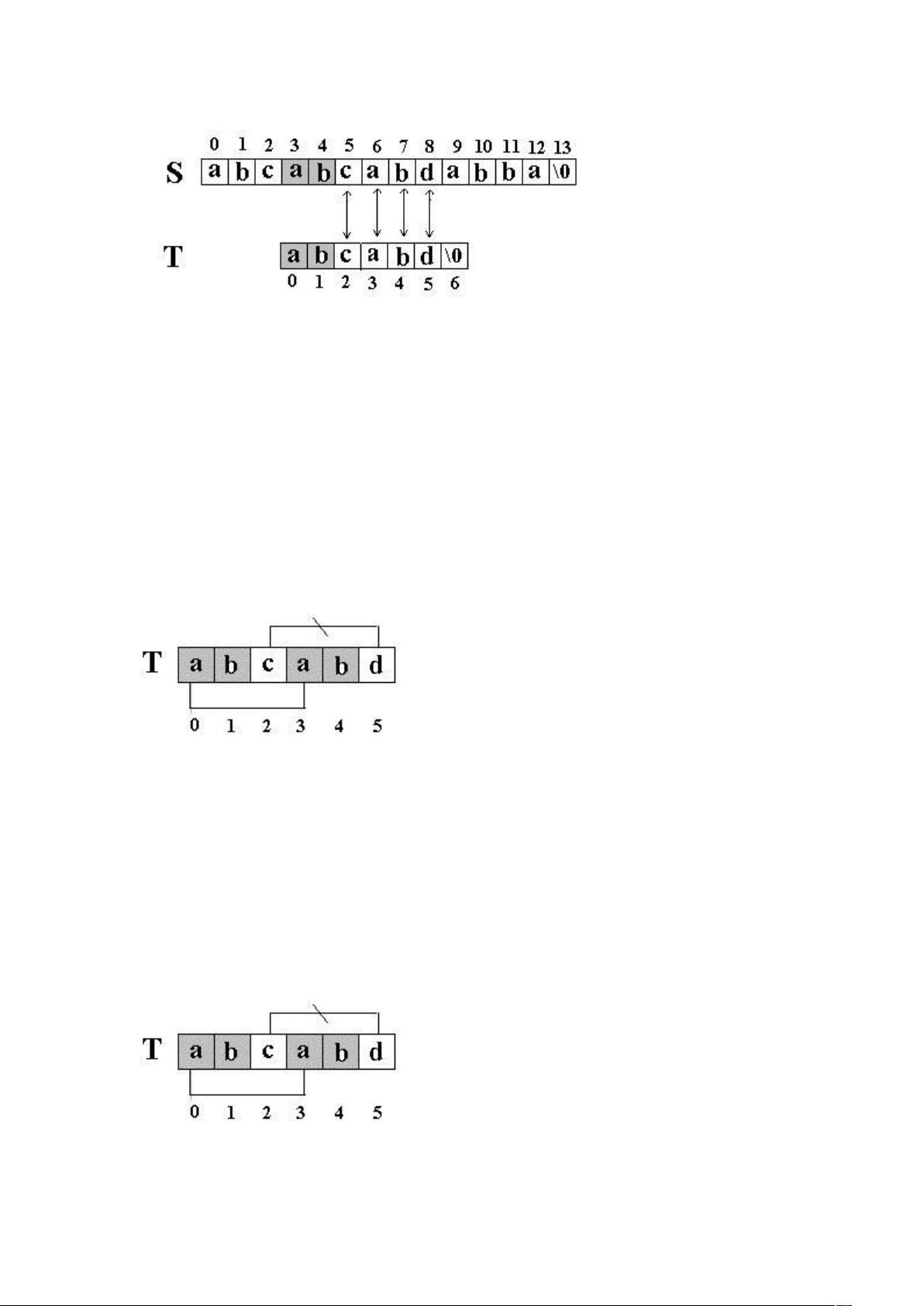
在简单匹配算法中,当主串S和模式串T在某个位置比较不匹配时,算法会将模式串T回溯到起始位置,而主串S则向前移动一位,这种做法在模式串中存在重复字符序列时会引发大量的无效比较。例如,在查找"abcabd"于"abcabcabdabba"中的位置时,简单的匹配算法会在多个位置重复比较相同的字符序列,导致效率低下。
KMP算法通过构造一个部分匹配表(也称为“失配表”或“最长公共前后缀表”),来解决这个问题。这个表记录了在模式串T中每个位置的字符与之前字符组成的最长达子串的长度。当发生不匹配时,根据部分匹配表,可以直接确定模式串应向右移动多少位,而无需从头开始比较。
例如,对于模式串"abcabd",部分匹配表可能如下:
- T[0]: 0
- T[1]: 0
- T[2]: 1 (因为"a"和"ab"的公共前后缀长度为1)
- T[3]: 2 (因为"bc"和"abc"的公共前后缀长度为2)
- T[4]: 0
- T[5]: 1 (因为"d"和"abcab"没有公共前后缀,但与"abcabd"的后一个字符有公共前后缀)
在匹配过程中,如果在位置i处S[i]与T[j]不匹配,那么模式串T会根据部分匹配表向前移动j个位置,而不是回到起点。这样,KMP算法能够在大多数情况下避免了重复比较,从而提高效率。
在上述例子中,当第一次失配发生在S[5]和T[5]时,根据部分匹配表,T会回退到位置2,而S保持在当前位置6,继续比较。如此,KMP算法可以更有效地找到模式串在主串中的位置,时间复杂度为O(m+n),其中m是主串S的长度,n是模式串T的长度。
总结来说,KMP算法通过部分匹配表优化了字符串匹配的过程,减少了不必要的比较次数,尤其在处理包含重复子串的模式时,效率远高于简单的暴力匹配。理解并实现KMP算法对于处理大量字符串数据的问题具有重要的实际意义。
匹配算法和简单匹配算法效率比较,一个极端的例子是:
在 '“======>==“&!! 个 =中查找 '5=========5 简单匹配算法每次都是比
较到 的结尾,发现字符不同,然后 的下标回溯到开始, 的下标也要回溯相同长度后
增 &,继续比较。如果使用 匹配算法,就不必回溯:
对于一般文稿中串的匹配,简单匹配算法的时间复杂度可降为 ?@,,因此在多数的实
际应用场合下被应用。
算法的核心思想是利用已经得到的部分匹配信息来进行后面的匹配过程。看前面的例
子。为什么 8'';;的模式函数值等于 <(8'<),其实这个 < 表示 8'';;的前
面有 < 个字符和开始的两个字符相同,且 8'';;不等于开始的两个字符之后的第三个字
符(<';;):如图:
也就是说,如果开始的两个字符之后的第三个字符也为’;那么,尽管 8'';;的前面有 <
个字符和开始的两个字符相同,8'';;的模式函数值也不为 <,而是为 !。
前面我说:在 '5666665中查找 '5665,如果使用 匹配算法,当第一
次搜索到 8 和 8不等后, 下标不是回溯到 &, 下标也不是回溯到开始,而是根据
中 8'';;的模式函数值,直接比较 8 和 <是否相等。。。为什么可以这样?
刚才我又说:“(8'<),其实这个 < 表示 8'';;的前面有 < 个字符和开始的两个
字 符 相 同 ” 。 请 看 图 ,,: 因 为 , A ''A , 9 ''9 , 根 据 8'< , 有
9''!,A''&,所以 9''!,A''&(两对相当于间接比较过了),因
此,接下来比较 8 和 <是否相等。。。
有 人 可 能会问: 9 和 ! , A 和 & 是 根 据 8'< 间 接 比 较 相 等 , 那 & 和
剩余10页未读,继续阅读

jiamianwuzhe
- 粉丝: 10
- 资源: 33
 我的内容管理
展开
我的内容管理
展开







最新资源
- CVS与配置管理.ppt
- linux命令大全~~~~~~
- 软件测试规范使你更加了解软件测试的规则
- sql语法帮助大全sql
- CISCO IOS名称意义详解
- Measurement technique for characterizing memory effects in RF power amplifiers
- Eclipse中文教程
- Microsoft Introducing Silverlight 2.0
- MyEclipse6 中文教程
- Java水晶报表教程
- Linux菜鸟过关(赠给初学者)
- Test.Driven.TDD.and.Acceptance.TDD.for.Java.Developers
- 编写高效简洁的C语言代码
- AIX 5L 安装手册
- Linux下的shell与make
- C#.Net函数方法集
