R语言数据挖掘:Crime&Shock案例分析与数据预处理
R数据挖掘实例深入解析
R语言作为一门强大的统计分析工具,尤其在数据挖掘领域备受青睐。本文将围绕R语言的使用,以"Crime&Shock"数据集为例,展开一系列的数据预处理、探索性数据分析和特征处理过程。首先,我们从描述中了解到,R语言由Ross Ihaka和Robert Gentleman开发,继承了S语言的传统,同时具备S语言的兼容性和Scheme语法特性。
1. 数据预处理:
- 通过`read.table()`函数导入数据集"crim.txt"和"attr_vol.txt",并调整变量名以提高可读性。使用`summary()`和`dim()`函数检查数据的基本属性,发现数据包含2215个观测值和147个变量,但存在部分缺失值。
2. 缺失值处理:
- 确认数据中几乎每一行都有缺失值,但由于数量在20左右,没有严重影响分析,因此选择不删除,而是采取邻近值插补的方法。首先对非因子变量(如gangUnit)进行处理,利用`cluster`包中的`daisy()`函数计算数据点之间的空间距离,以便找到相似样本进行插补。
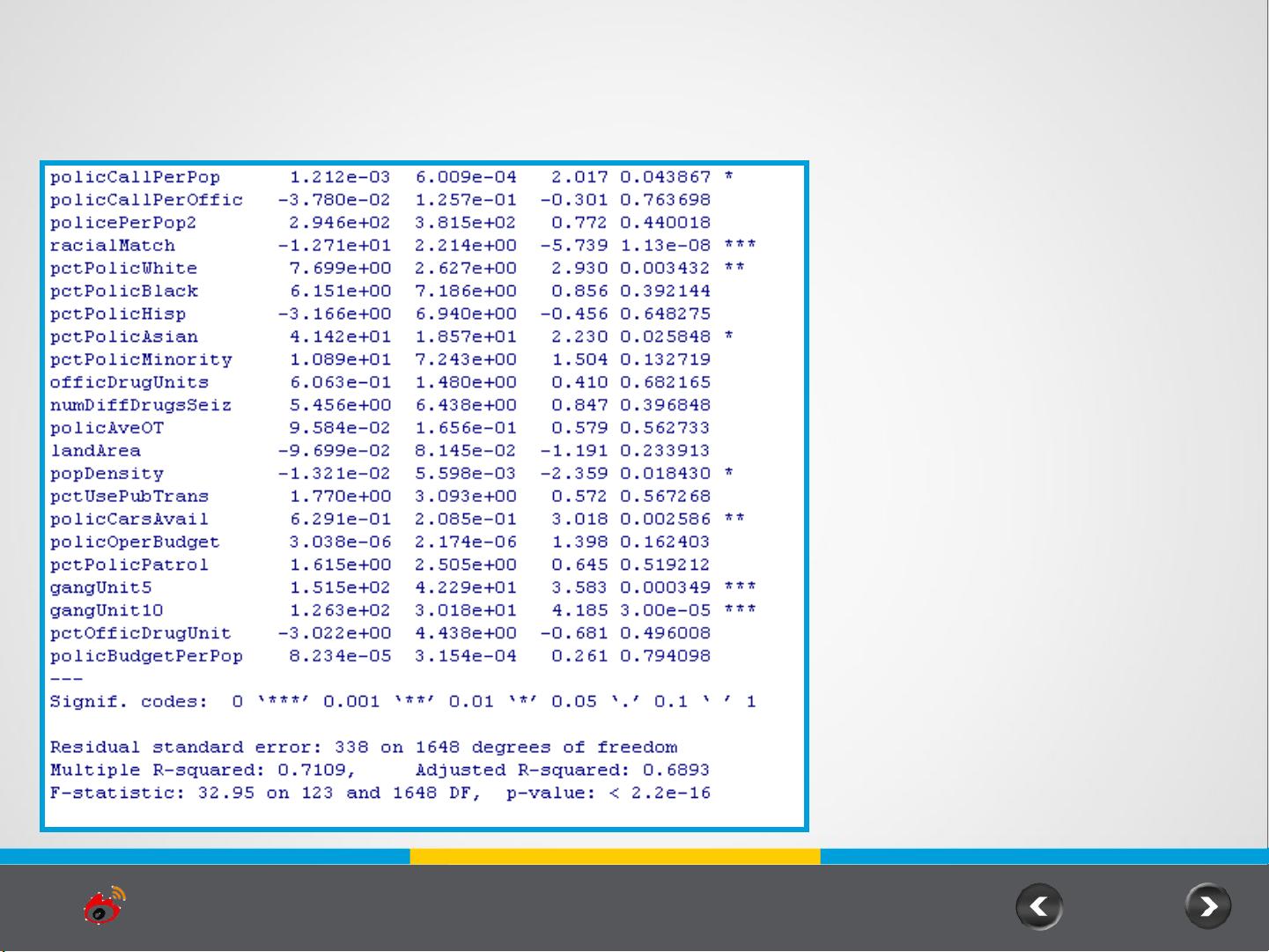
3. 数据探索与特征工程:
- 分析犯罪率分布,注意到violentPerPop和nonViolPerPop两个变量具有拖尾现象,为了改善数据的正态性,作者考虑对这两个变量进行对数变换,使得数据更加对称。
4. 地区差异与异常值检测:
- 对不同地区的犯罪率进行比较,发现犯罪率由西向东递减,但东部地区存在显著的离群值。这可能表明东部地区的犯罪情况与其他地区有所不同,需要进一步探究。
5. 数据可视化与特征处理:
- 通过图表展示数据分布情况,帮助理解数据特性,对对数变换后的数据进行观察,确认其在视觉上更加均匀。
本实例展示了如何使用R语言进行数据清洗、探索性数据分析以及特征工程的过程。通过处理缺失值、数据变换和可视化,为后续的数据挖掘和建模奠定了基础。对于实际应用中遇到的数据集,类似的方法可以帮助分析师更有效地提取有价值的信息,并提高模型的性能。


2025-02-17 上传
2025-02-17 上传
PID、ADRC和MPC轨迹跟踪控制器在Matlab 2018与Carsim 8中的Simulink仿真研究,PID、ADRC与MPC轨迹跟踪控制器在Matlab 2018与Carsim 8中的仿真研
2025-02-17 上传
2025-02-17 上传
2025-02-17 上传
2025-02-17 上传

路凡
- 粉丝: 16
 我的内容管理
展开
我的内容管理
展开







最新资源
- Spring开发指南:V0.8预览版 - 持久层、Web工作流与AOP详解
- 精通Eclipse插件开发:从入门到实践
- DB2驱动的联系人信息管理系统数据库设计与实现
- Struts开发步骤详解:从创建工程到数据操作
- C#编程入门与进阶指南
- C#面试必备:核心概念与题目解析
- ESRI Shapefile格式详解:专业地理信息存储标准
- Hibernate缓存机制详解:事务、进程与集群范围
- Java正则表达式完全指南
- 整合STRUTS、SPRING与HIBERNATE实践笔记
- Oracle函数详解:SQL指令与字符串操作
- JAVA数据库编程详解:连接、操作与事务处理
- Java取余操作谜题:解析isOdd方法的陷阱
- 高质量C++/C编程规范与指南
- 计算机网络习题解析与解答
- 配置多节点JBoss服务器:端口修改指南
