ComicStudio漫画入门教程与实战指南
需积分: 10 189 浏览量
更新于2024-07-18
收藏 31.02MB PDF 举报
"ComicStudio软件入门全集是一份针对初学者设计的详尽教程,涵盖了ComicStudio这款专业级的电脑绘画软件的全面使用方法。该PDF文件主要分为以下几个部分:
1. 界面图解与创作流程:首先,读者会被引导了解软件的基本界面布局,包括工具栏、菜单选项和常用快捷键,以及创作流程的各个环节,如绘制角色、背景、分镜等。
2. ComicStudio教室系列:共十节课程,从基础操作开始,逐步深入到进阶技巧,如角色设计、色彩应用、特效制作等。每节课都通过实例教学,使学习者能够边学边实践。
3. 番外篇:包含对特定功能的深入探讨,如破格对话框的建立与处理、网络纸张的使用技巧、透视尺的应用,以及自定义特殊字体效果等,这些内容旨在帮助用户充分利用软件的高级功能。
4. 简易教程与基本知识:对于初次接触ComicStudio的新手,有简明易懂的教程和基础知识介绍,让学习者快速上手。
5. 额外资源:除了ComicStudio本身,还包含了Artrage漫画教程,以及更广泛的漫画教学内容,如日本漫画杂志的排版技术,甚至如何将照片转换成网点,以实现传统与数字艺术的融合。
6. 解决小问题:书中还可能包含常见问题解答,帮助用户在遇到困难时找到解决方案。
这份教程不仅适合想要系统学习电脑漫画绘画的人,也适合有一定基础的漫画创作者提升技能。无论是想从事漫画创作,还是希望提高现有作品质量的爱好者,都能从中获益匪浅。通过阅读和实践,读者可以迅速掌握ComicStudio的强大功能,为自己的漫画作品增添专业质感。"

13
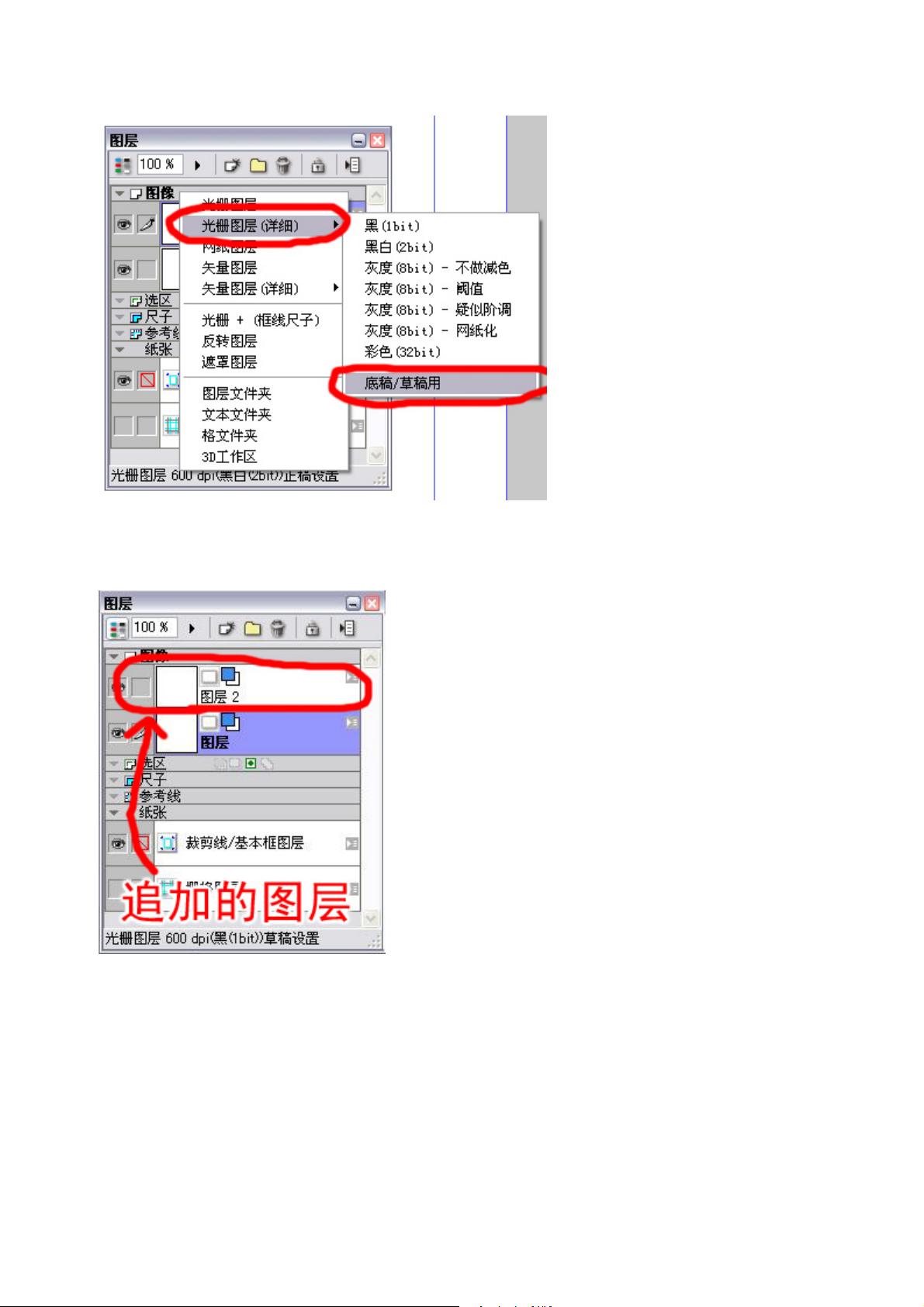
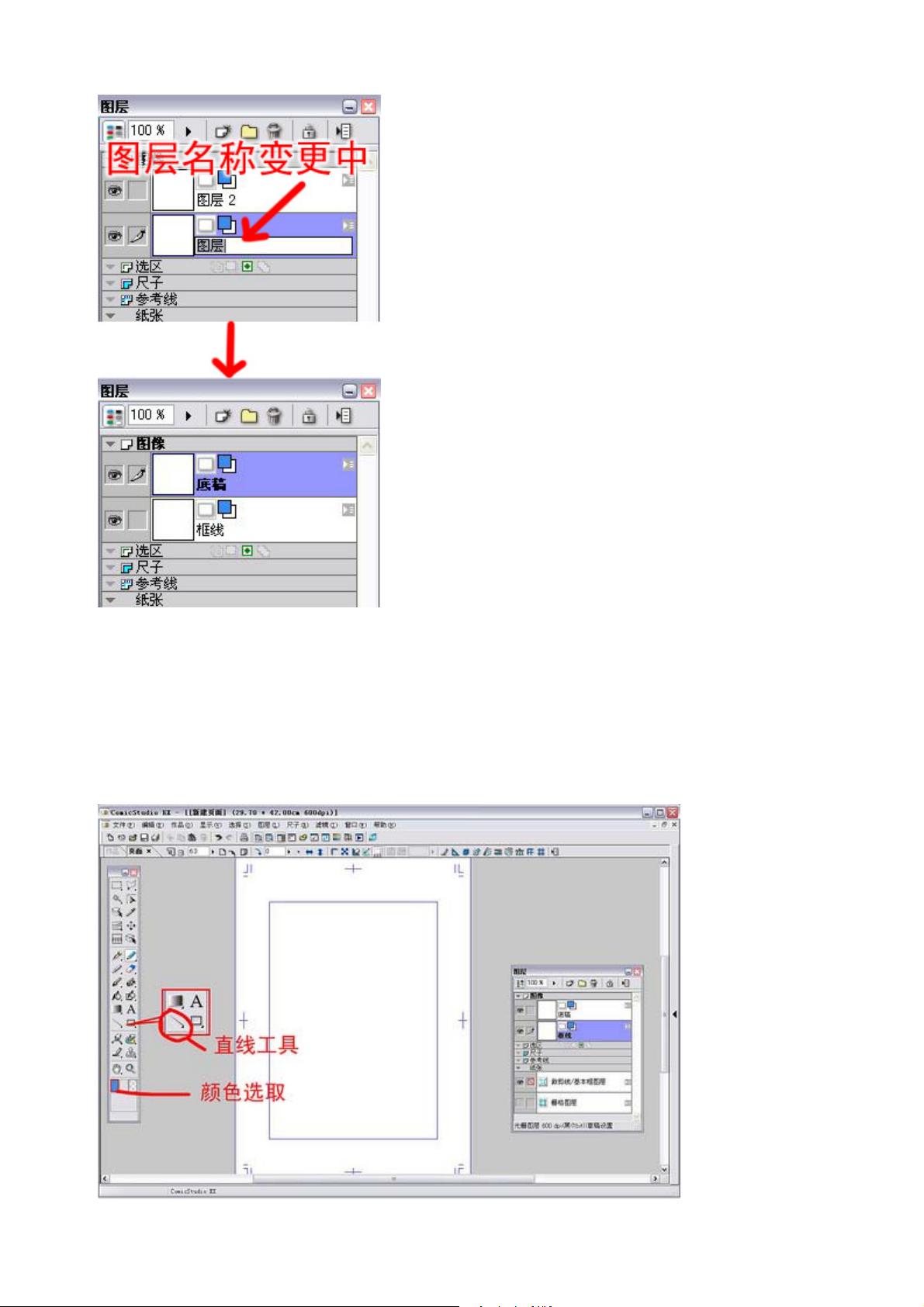
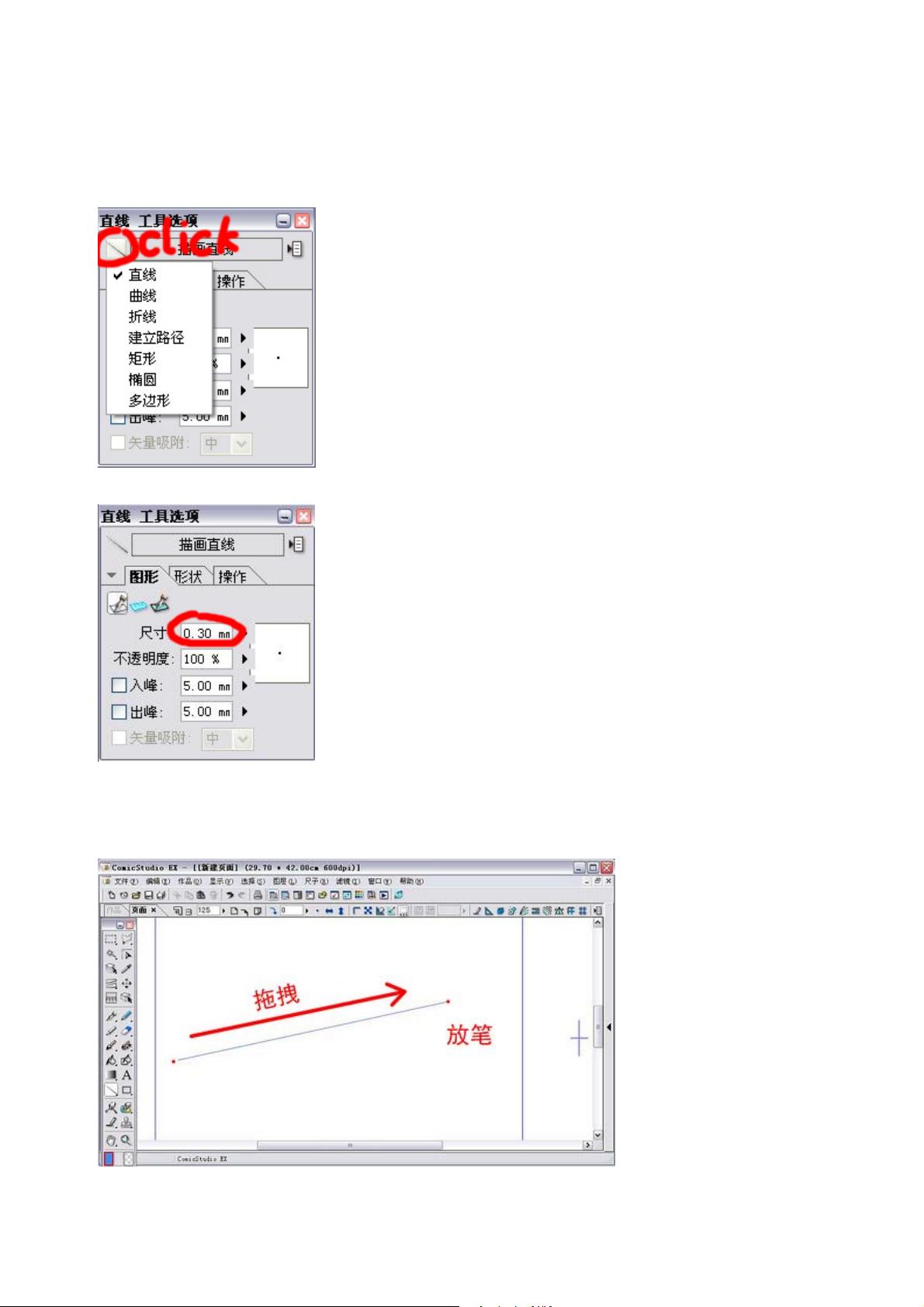
下面进入真正的漫画绘制作业(终于……)将“新手指南”部分隐藏,尽量多留点儿地方给原稿纸。这时候
如果已经有一些工具栏出现在桌面上的话按[TAB]键可以将其隐藏。
全部隐藏了?那么现在将最低限度的工具栏调出。(这也许是作者的毛病,他的显示器可能太小,拥有大
显示器的家伙就不要管了)按[F2][F3][F4][F5]键将“工具对话框”“工具选项对话框”“图层对话框”“新手指
南”调出。
调出工具栏,准备 OK

剩余244页未读,继续阅读
432 浏览量
148 浏览量
点击了解资源详情
2021-11-18 上传
2021-10-11 上传
212 浏览量
432 浏览量
119 浏览量
2021-09-26 上传

C__supreme
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- J_Space 4.2人才招聘系统官方修订版整合ucenter uchome
- Xnap组件使用方法及特性介绍
- 微软TTS5.1实现高效语音播放文本功能
- 使用JavaScript和Canvas实现Conway生命游戏
- ZTREE父子树插件:优化查询、搜索与高亮功能
- OCPP 1.6协议文档与 schemas文件详解
- 网件R4300路由器刷机指南与工具包
- 窗口大小调整后正确显示Combobox下拉数据的解决方案
- 深入解析Android中Socket编程的源码
- Arkpex00升级与布鲁斯男孩服务器页面维护
- 解决FragmentDemo屏幕旋转文字重叠问题的方案
- strong-pubsub: 跨平台 PubSub 实现介绍及安装指南
- RBF神经网络在腐蚀数据分析中的应用——MATLAB实现方法
- 基于Matlab的粒子群算法优化TSP问题详解
- 演示项目:在JavaScript中实现Azure沉浸式阅读器
- C#多线程编程指南:线程同步技术详解
