排序算法详解:冒泡、插入、选择、归并与快速排序
需积分: 0 115 浏览量
更新于2024-09-07
收藏 1.28MB DOCX 举报
"这篇文档涵盖了第4章的算法知识,主要涉及了各种排序算法的总结,包括冒泡排序、插入排序、选择排序、快速排序、归并排序和堆排序,以及图上的最短路径算法如DFS、BFS、Dijkstra和Floyd算法,还有最小生成树的Kruskal和Prim算法,以及Hash概念。文档特别强调了这些算法的时间复杂度和稳定性,并提供了相关的链接以供深入学习。"
排序算法是计算机科学中非常基础且重要的概念,它们用于组织和优化数据处理。以下是对几种常见排序算法的详细解释:
1. 冒泡排序:通过重复遍历待排序的列表,比较相邻元素并交换位置来排序。冒泡排序在最好情况下(已排序)的时间复杂度为O(n),最坏(倒序)为O(n^2),平均情况下也是O(n^2)。它是一种稳定的排序算法,但效率较低。
2. 直接插入排序:将每个元素逐个插入到已排序的序列中的适当位置。在最好情况下(已排序)的时间复杂度为O(n),最坏为O(n^2),平均时间复杂度同样为O(n^2)。插入排序也是稳定的排序方法。
3. 选择排序:每次找到未排序部分的最大(或最小)元素,将其放在正确位置。无论输入顺序如何,选择排序的时间复杂度始终为O(n^2),并且它是不稳定的排序算法。
4. 归并排序:采用分治策略,将大问题分解为小问题,然后合并这些小问题的解。归并排序在所有情况下都有O(n log n)的时间复杂度,是稳定的排序算法,适合处理大规模数据。
5. 快速排序:选择一个基准元素,将数组分为两部分,使得一部分的所有元素小于基准,另一部分的所有元素大于基准,然后对这两部分递归地进行快速排序。快速排序的平均时间复杂度为O(n log n),最坏情况(已排序或逆序)为O(n^2),但实际应用中通常表现优秀。
图上最短路径算法包括深度优先搜索(DFS)、广度优先搜索(BFS)、Dijkstra算法和Floyd算法,它们分别用于寻找单源最短路径和所有对最短路径。这些算法在路由、网络流量调度等领域有广泛应用。
最小生成树算法Kruskal和Prim是解决加权无向图的最小树问题,Kruskal算法基于边的集合选择,而Prim算法基于节点的集合选择,两者都能找到连接所有节点且总权重最小的树。
Hash,也称为哈希,是一种数据结构,它可以将任意大小的数据映射到固定大小的值,常用于快速查找和数据索引。
这些算法是IT初赛中常见的基础知识,理解和掌握它们对于编程和数据处理非常重要。深入学习这些概念,有助于提升解决问题的能力。
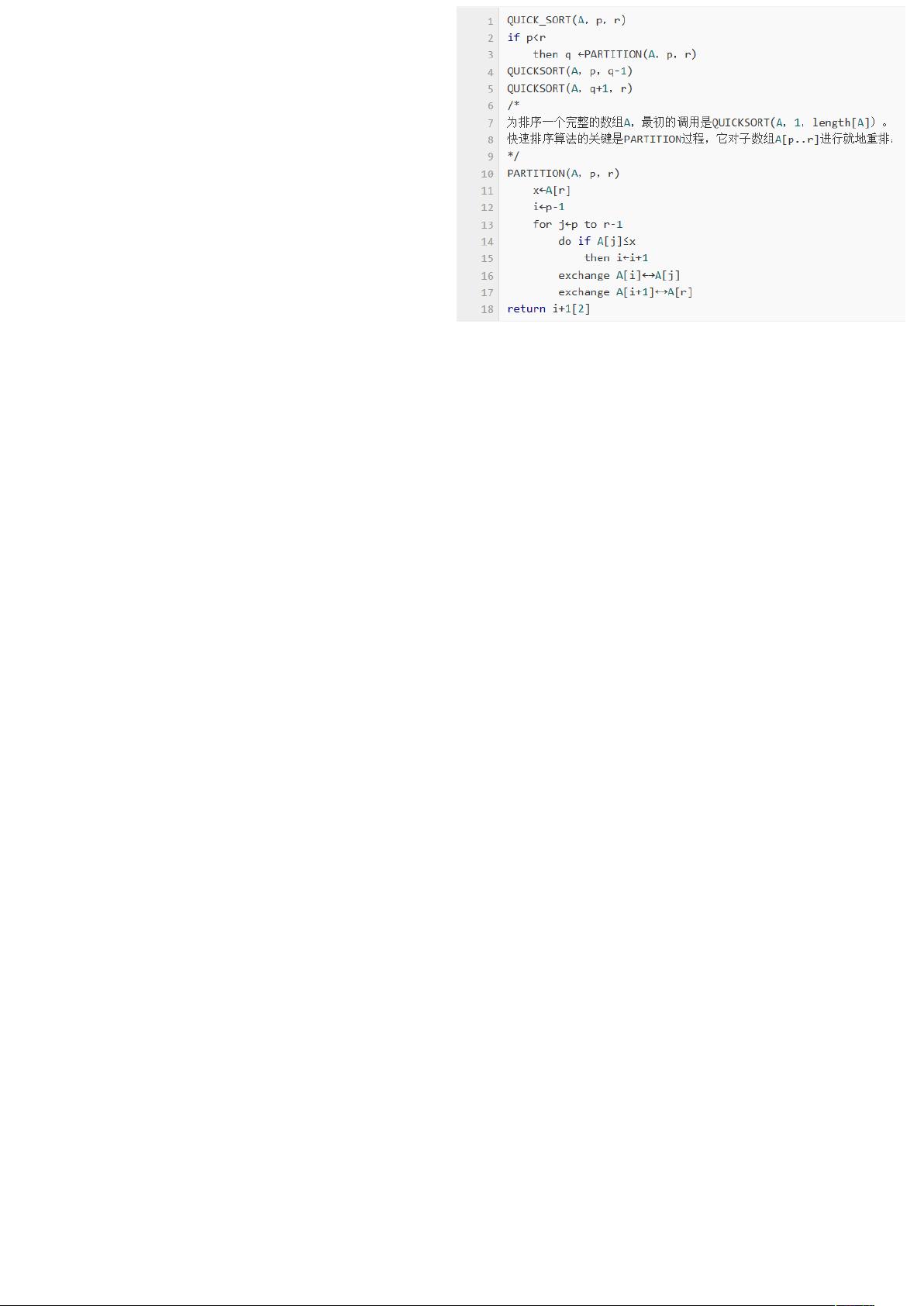
五、快速排序
首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它
小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。
复杂度分析:
空间效率:仅用了一个辅助交换单元 O(1)。
辅助的存储空间 O(log2n)
最好的时间复杂度为 O(nlog2n) 。
最坏时间复杂度为 O(n2)。
平均时间复杂度为 O(nlog2n)。
快速排序是不稳定的。
六、堆排序
利用数据结构堆进行排序
(1)根据初始数组去构造初始堆(构建一个完全二叉树,保证所有的父结点都比它
的孩子结点数值大)。
(2)每次交换第一个和最后一个元素,输出最后一个元素(最大值),然后把剩下
元素重新调整为大根堆。
当输出完最后一个元素后,这个数组已经是按照从小到大的顺序排列了。
剩余10页未读,继续阅读
2022-07-02 上传
2022-06-01 上传
2021-12-09 上传
2021-09-30 上传
2023-03-13 上传
2020-05-25 上传
2021-03-03 上传
2023-07-06 上传
2012-10-30 上传

WLHW
- 粉丝: 17
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- gcc4.4.7合集包
- MyPetShop.Web_weatherserviceref_mypetshop_web_asp.net_
- flex:Swagger模式验证器
- app.rar_PHP__PHP_
- bdd-example:我尝试使用 Cucumber js 作为轻量级框架进行测试
- Python库 | jirafs_graphviz-3.0.1-py3-none-any.whl
- 基于LSTM的图像描述研究和实现.zip
- INFO6270_Final_Project:Infro6270最终项目-在Halifax公共图书馆系统中扩展公共图书馆嵌入式社会工作者的实施
- JNI编程指南(实用1).zip
- quirc-master (1)_quirc_qr读取_
- exzeitable:通过Phoenix LiveView动态更新可搜索,可排序的数据表
- Python库 | jiradls-1.0-py3-none-any.whl
- Ogitor-开源
- poke:带有Redux和React-Pixi的Pokemon Red相似实验
- datasheet_bk2461芯片手册_bk2461芯片手册_V2_bk2461_BK2461芯片资料_
- avcodec:编码器解码器渲染器
