Hadoop离线分析:深入理解HDFS的副本机制与块存储
172 浏览量
更新于2024-09-02
收藏 1.21MB PDF 举报
HDFS全称为Hadoop Distributed File System,是一个专为大规模数据集设计的分布式文件系统,它是Apache Hadoop项目的核心组成部分。本文将深入讲解HDFS的基础概念、设计思路、关键组件以及其在分布式文件系统中的应用。
**分布式文件系统设计思路**
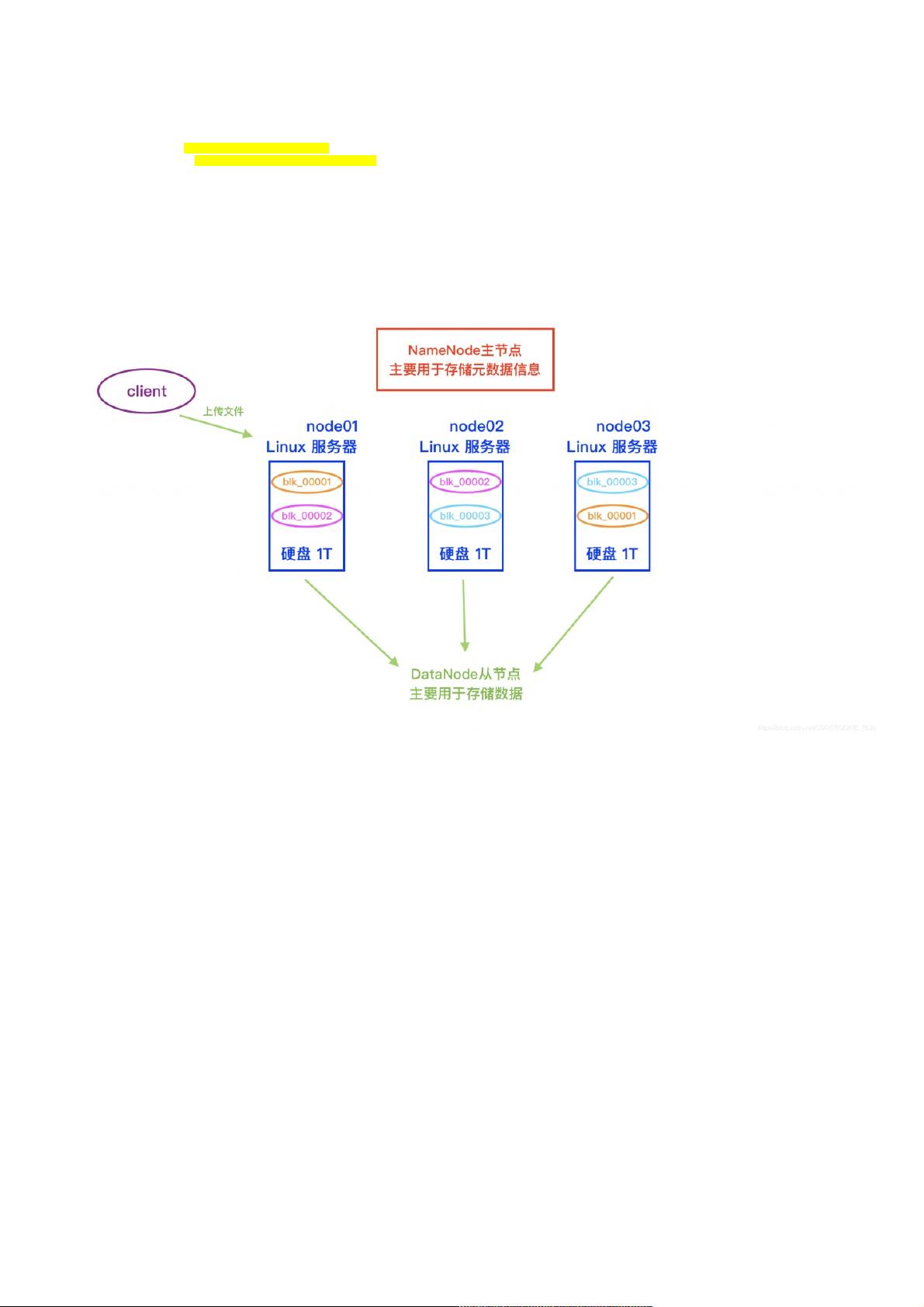
HDFS的设计灵感来源于单一机器文件系统的简单结构,但随着数据量的增长,单机无法满足需求。在多台机器上分发文件时,传统的查找方式需指定具体机器路径,如"hello.txt/node02/export/servers/hello.txt"。为解决数据丢失问题,HDFS引入了副本机制,每个文件块至少会被复制到不同的DataNode节点,确保数据的冗余性和可靠性。
**文件块与元数据管理**
HDFS将文件划分为固定大小的块(block),比如常见的默认块大小为64MB或128MB。每个块都有一个唯一的标识(blk_00001、blk_00002等),这些信息由NameNode管理。NameNode记录了每个块的元数据,包括块的位置信息(如node01、node02等),以及块的副本分布情况。这使得文件能够被多个节点共享,提高数据安全性。
**NameNode与DataNode的角色**
NameNode作为整个文件系统的管理核心,它维护着文件系统的命名空间和元数据,包括文件和目录的创建、删除、重命名等操作。同时,它负责协调客户端的读写请求,确保数据的正确分发。DataNode则是实际存储数据的节点,它们接收来自NameNode的指令,执行数据的读取和写入操作。
**HDFS设计目标**
HDFS旨在应对高硬件故障率、数据流访问、大数据集处理、稳定而非效率优先、数据一次写入多次读取等场景。它适合存储历史数据,不擅长频繁更新,更倾向于移动计算而非频繁的数据传输。同时,HDFS强调跨平台兼容性,易于在不同软硬件环境中部署。
**文件副本机制**
HDFS采用数据副本机制,通常将每个块复制三份,以提高容错性和可用性。当某个DataNode节点发生故障,其他副本节点可以接管,保证服务不间断。NameNode负责监控和动态调整副本分布,以优化数据访问性能。
**基础架构图示**
HDFS的基本架构包括NameNode和DataNode。NameNode作为主控中心,而DataNode负责数据的存储。NameNode通过心跳机制与DataNode保持通信,并定期更新元数据的磁盘快照。这种设计保证了系统的高可用性。
HDFS是一个为大数据处理设计的分布式文件系统,通过复制机制、块存储和集中式的元数据管理,提供高可靠性和高效的数据访问。理解并掌握HDFS的工作原理对于Hadoop生态系统开发者和运维人员至关重要。
【【Hadoop离线基础总结】离线基础总结】HDFS详细介绍详细介绍
HDFS详细介绍详细介绍
分布式文件系统设计思路分布式文件系统设计思路
概述概述
只有一台机器时的文件查找:hello.txt /export/servers/hello.txt
如果有多台机器时的文件查找:hello.txt node02 /export/servers/hello.txt
为了解决数据丢失的问题,引入副本机制副本机制,保证数据不会丢失
如果对文件进行切块存储,那么元数据信息又要继续变化
blk元数据信息的记录元数据信息的记录
blk_00001 node01 node03 /export/servers/blk_00001
blk_00002 node02 node01 /export/servers/blk_00002
blk_00003 node03 node02 /export/servers/blk_00003
概念简图概念简图
文件系统基本介绍文件系统基本介绍
概览概览
下载后可阅读完整内容,剩余4页未读,立即下载
2018-07-04 上传
2018-06-06 上传
2021-01-07 上传
2023-11-07 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38647517
- 粉丝: 2
- 资源: 964
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
