MySQL主从复制机制与挑战
171 浏览量
更新于2024-08-31
收藏 286KB PDF 举报
"本文主要介绍了MySQL的简单主从方案及其存在的问题,以及其工作原理,重点关注MySQL自带的日志复制机制(Replication)。"
在MySQL数据库系统中,主从复制(Replication)是一种常用的技术,用于实现数据的冗余和负载均衡,特别是对于读写分离的场景。MySQL 5.6版本的Replication机制已经相当成熟,虽然文中提到的一些特性在5.7和8.0版本中得到了进一步优化,但基本原理仍然适用。
2-1 MySQL-Replication工作原理详解
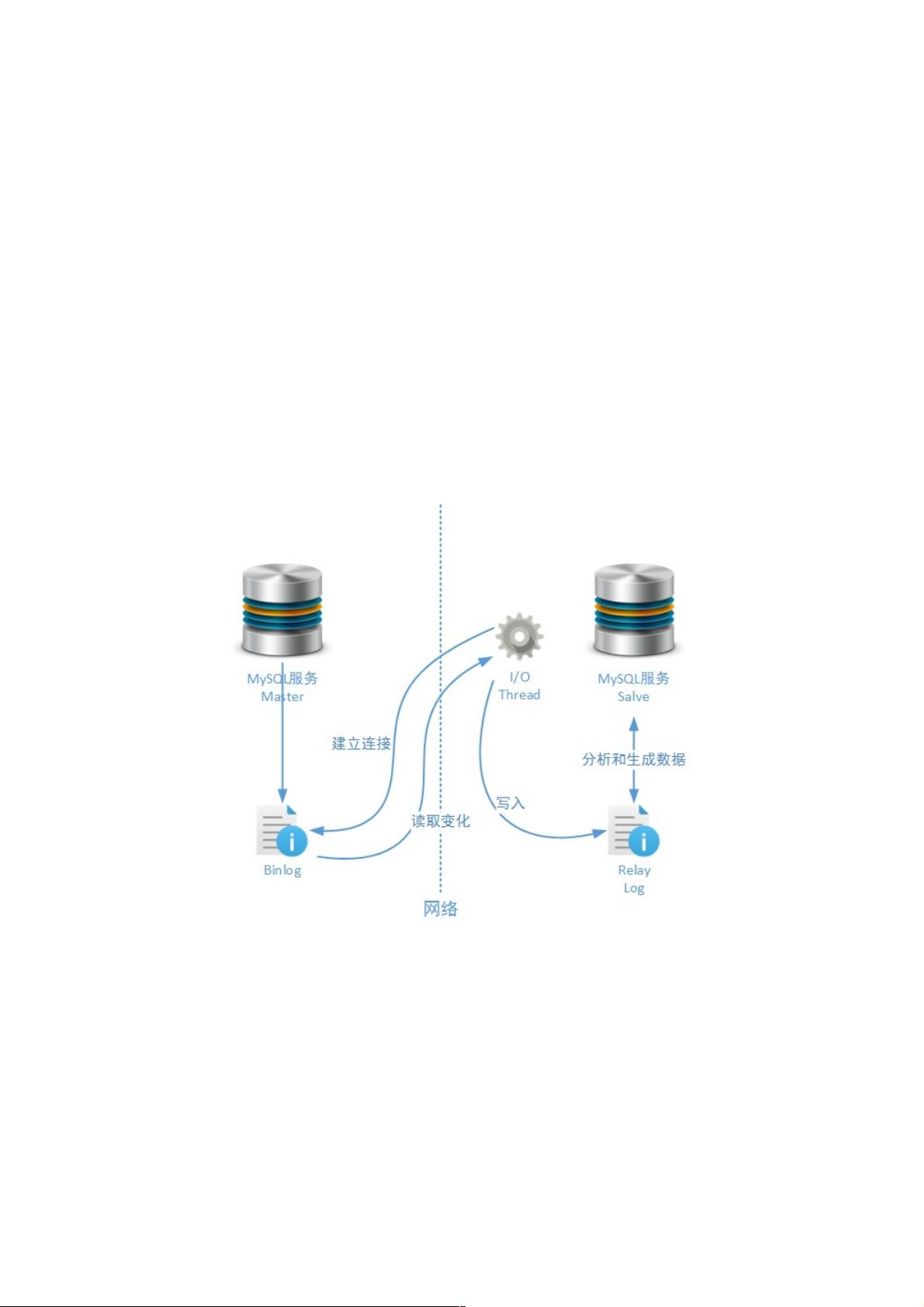
Replication主要包括两个核心角色:Master(主服务器)和Slave(从服务器)。Master负责处理写操作并生成二进制日志(Binary Log),记录所有改变数据的SQL语句。Slave则从Master那里获取这些日志,再应用到自身的数据中,从而保持与Master的数据同步。
Replication的过程大致如下:
1. Slave在初始化时,通常需要执行一次全量复制,获取Master的当前数据状态。
2. 全量复制完成后,Slave持续连接Master,监听Binary Log的变化。
3. 当Master上有新的写操作时,这些操作会被记录到Binary Log中。
4. Master将Binary Log事件发送给Slave,通常是通过网络连接。
5. Slave收到事件后,将其写入中继日志(Relay Log)。
6. 中继日志中的事件由 Slave 的I/O线程读取并交给SQL线程,由SQL线程在Slave上执行相同的SQL语句,完成数据更新。
这种机制使得数据能够在多个服务器之间实时同步,为实现读写分离提供了基础。在读密集型应用中,可以将读请求分发到Slave,减轻Master的压力,提高系统整体性能。
然而,MySQL简单主从方案也存在一些问题和挑战:
1. 单点故障:如果Master服务器出现故障,可能影响整个系统的可用性,因为所有的写操作都依赖于Master。
2. 延迟问题:尽管Replication是实时的,但由于网络延迟和处理时间,Slave与Master之间可能存在数据延迟。
3. 数据一致性:在某些情况下,如网络中断或错误配置,可能会导致数据不一致。
4. 扩展性限制:随着数据和读写请求的增长,简单的主从架构可能不足以应对,需要更复杂的集群方案,如多主复制或多层复制。
为了解决这些问题,后续的文章可能会探讨更复杂的MySQL集群方案,比如多主复制、分布式数据库(如Galera Cluster)或使用第三方工具(如PXC, Percona XtraDB Cluster)构建的高可用集群,这些方案旨在提供更高的容错性和扩展性,同时尽量减少数据延迟和保证一致性。
MySQL的主从复制是数据库高可用性和读写分离的基础,但随着业务需求的复杂化,需要结合其他技术来提升系统的健壮性和性能。理解并掌握这些原理和技术,对于构建和维护大型数据库系统至关重要。
MySQL简单主从方案及暴露的问题简单主从方案及暴露的问题
1、概述
从本篇文章开始我们将花一定的篇幅向读者介绍mysql的各种服务集群的搭建方式。大致的讨论思路是从最简的MySQL主从方
案开始介绍,通过这种方案的不足延伸出更复杂的集群方案,并介绍后者是如何针对这些不足进行改进的。MySQL的集群技
术方案特别多,这几篇文章会选择一些典型的集群方案向读者进行介绍。
2、MySQL最简单主从方案及工作原理
我们讲解的版本还是依据目前在生产环境上使用最多的version 5.6进行,其中一些特性在Version 5.7和最新的Version 8.0中有
所改进,但这不影响读者通过文章去理解构建MySQL集群的技术思路,甚至可以将这种机制延续到MariaDB。例如马上要提
到的MySQL自带的日志复制机制(Replicaion机制)。
MySQL自带的日志复制机制称为MySQL-Replicaion。从MySQL很早的 Version 5.1版本就有Replicaion技术,发展到现有版本
该技术已经非常成熟,通过它的支持技术人员可以做出多种MySQL集群结构。当然,后文我们还会介绍一些由第三方软件/组
件支持的MySQL集群方案。
2-1、MySQL-Replicaion基本工作原理
Replicaion机制从技术层面讲,存在两种基本角色:Master和Salve。Master节点负责在Replicaion机制中,向一个或者多个目
标输出数据,而Salve节点负责在Replicaion机制中接受Master节点传来的数据。在实际业务环境下,Master节点和Salve节点
还分别有另外一个名字:Write节点和Read节点——是的,利用Replicaion机制我们可以搭建以读写分离为目标的MySQL集群
服务。但是为了保证读者在阅读文章内容时不会产生歧义,在本文(和后续文章)中我们都将使用Master节点和Salve节点这
样的称呼。Replicaion机制依靠MySQL服务的二进制日志同步数据:
如上图所示,Salve在启动后会建立一个和Master节点的网络连接,当Master节点的二进制日志发生变化后,一个或者多个
MySQL Salve服务节点就会通过网络接监听到这些变化日志。接着Salve节点会首先在本地将这些变化写入中继日志文件
(Relay Log),这样做是为了尽量避免MySQL服务在出现异常时同步数据失败,其原理和之前介绍过的InnoDB Log的工作
原理相似。当中继日志文件发生完成记录后,MySQL Salve服务会将这些变化反映到对应的数据表中,完成一次数据同步过
程。最后Salve会更新重做日志文件中的更新点(Position),并准备下一次Replicaion操作。
在这个过程中多个要素都可以进行配置,例如可以通过sync_binlog参数配置Master节点上数据操作次数和日志写入次数配比
关系、可以通过binlog_format参数配置日志数据的信息结构、可以通过sync_relay_log参数配置Salve节点上系统接收日志数
据与写入中继日志文件次数的配比关系。这些参数和其它一些在示例中使用的参数会在本文后续小节进行介绍。
2-2、MySQL一主多从搭建方式
介绍完MySQL Replicaion机制的基本工作方式后,我们紧接着就来快速搭建由一个Master节点和一个Salve节点构成的
MySQL集群。读者可以从这个一主一从的MySQL集群方案扩展出任何一主多从的集群方案:
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-09-09 上传
点击了解资源详情
2017-05-11 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38518885
- 粉丝: 8
- 资源: 942
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android应用源码之写的google map api 应用.zip项目安卓应用源码下载
- AdvExpFig:导出 MATLAB 图-matlab开发
- SuperChangelog:超级变更日志插件的源代码
- death_calc_version2
- hw_python_oop
- LX-PWM,ev3程序怎么看c语言源码,c语言程序
- material-typeahead-sample
- 基于Linux、QT、C++的“别踩白块儿”小游戏
- physx-js:PhysX for JavaScript
- 提取均值信号特征的matlab代码-First_unofficial_entry_2021:First_unofficial_entry_20
- Siege_solution_website
- ecf-2021-jd
- number.github.io:通过Szymon Rutyna
- Kinesys-RenPy-Practice:RenPy制作游戏
- Ad,c语言源码反码补码转换代码,c语言程序
- vgrid:具有魔术媒体查询混合功能的可变SCSS网格系统
