尚硅谷大数据:Kafka详解——消息队列与解耦关键
需积分: 11 36 浏览量
更新于2024-07-16
收藏 1.48MB PDF 举报
《大数据技术之Kafka》是一份由尚硅谷大数据研发部编写的文档,专注于介绍Kafka这一关键的大数据技术。Kafka是一款分布式流处理平台,它主要以消息队列的形式提供高效、可靠、实时的数据传输服务。本文档共分为两部分:第一章节概述了Kafka的基本概念和工作模式。
1.1 消息队列及其内部实现原理
Kafka支持两种主要模式:点对点模式和发布/订阅模式。点对点模式强调一对一的通信,客户端主动拉取消息,消息一旦被接收就从队列中移除;发布/订阅模式则是多对多的,生产者将消息推送给所有订阅者,不论其是否在线。这种设计提供了解耦、冗余、扩展性和灵活性,能够处理峰值负载,确保数据的顺序传递和缓冲机制。
- 解耦:通过消息队列,应用程序之间的依赖关系被分解,各个组件可以根据需要独立扩展或修改,只需保持接口的一致性。
- 冗余:Kafka通过持久化消息来防止数据丢失,采用"插入-获取-删除"的机制,只有在处理确认后才删除消息,确保数据安全。
- 扩展性:由于消息队列的解耦特性,可以通过增加处理节点来应对业务增长,提升系统吞吐量。
- 峰值处理能力:在流量激增时,应用仍能正常运行,因为Kafka能处理高并发和临时的流量波动。
1.2 为何选择Kafka
Kafka被广泛应用于大数据场景,原因在于其强大的功能和优势。除了上述的解耦和冗余特性外,还有其他重要因素:
- 可恢复性:Kafka支持持久化的日志存储,即使系统崩溃,也能从备份中恢复数据,提高系统的可靠性。
- 顺序保证:Kafka保证消息的顺序处理,这对于需要按时间顺序处理的系统至关重要。
- 异步通信:通过异步模型,Kafka减少了系统的响应时间和资源消耗,提升了整体性能。
《大数据技术之Kafka.pdf》文档深入剖析了Kafka的核心概念和应用场景,对于理解和使用Kafka在大数据处理中的角色具有重要的参考价值。如果你需要了解更多关于Java、大数据、前端、Python等领域的资料,可以访问尚硅谷官网获取更多资源。
尚硅谷大数据技术之 Kafka
—————————————————————————————
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
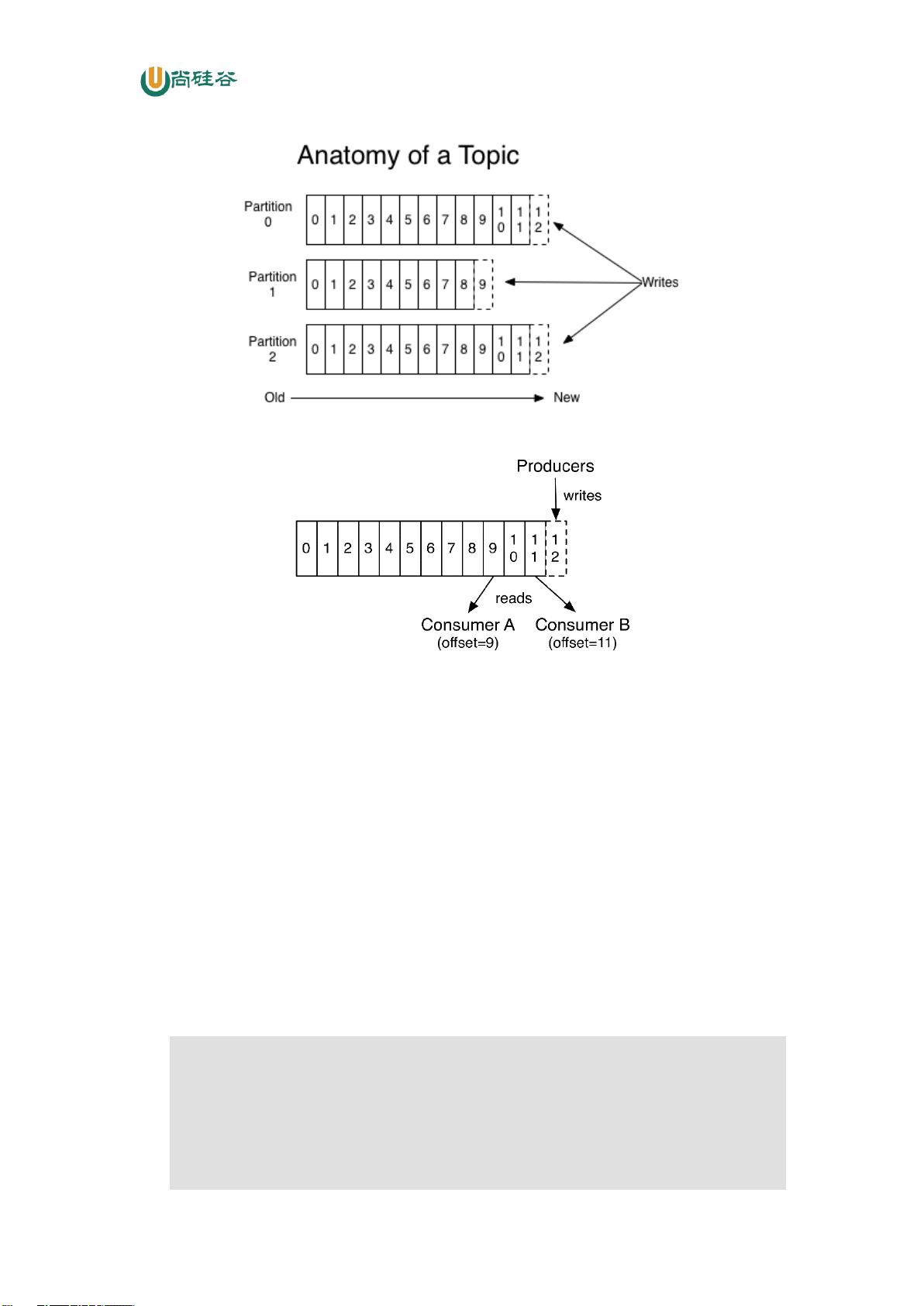
我们可以看到,每个 Partition 中的消息都是有序的,生产的消息被不断追加到 Partition
log 上,其中的每一个消息都被赋予了一个唯一的 offset 值。
1)分区的原因
(1)方便在集群中扩展,每个 Partition 可以通过调整以适应它所在的机器,而一个 topic
又可以有多个 Partition 组成,因此整个集群就可以适应任意大小的数据了;
(2)可以提高并发,因为可以以 Partition 为单位读写了。
2)分区的原则
(1)指定了 patition,则直接使用;
(2)未指定 patition 但指定 key,通过对 key 的 value 进行 hash 出一个 patition;
(3)patition 和 key 都未指定,使用轮询选出一个 patition。
DefaultPartitioner 类
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[]
valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions =
cluster.availablePartitionsForTopic(topic);

剩余44页未读,继续阅读
2019-05-28 上传
2019-07-09 上传
2019-06-27 上传
2021-10-14 上传
2022-11-05 上传
2022-12-24 上传
2022-11-20 上传
2021-10-14 上传

smileNicky
- 粉丝: 2w+
- 资源: 407
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
